 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of (Mis)alignment: How Fine-Tuning Methods Effectively Misalign and Realign LLMs in Post-Training
Apr 09, 2026The deployment of large language models (LLMs) raises significant ethical and safety concerns. While LLM alignment techniques are adopted to improve model safety and trustworthiness, adversaries can exploit these techniques to undermine safety for malicious purposes, resulting in \emph{misalignment}. Misaligned LLMs may be published on open platforms to magnify harm. To address this, additional safety alignment, referred to as \emph{realignment}, is necessary before deploying untrusted third-party LLMs. This study explores the efficacy of fine-tuning methods in terms of misalignment, realignment, and the effects of their interplay. By evaluating four Supervised Fine-Tuning (SFT) and two Preference Fine-Tuning (PFT) methods across four popular safety-aligned LLMs, we reveal a mechanism asymmetry between attack and defense. While Odds Ratio Preference Optimization (ORPO) is most effective for misalignment, Direct Preference Optimization (DPO) excels in realignment, albeit at the expense of model utility. Additionally, we identify model-specific resistance, residual effects of multi-round adversarial dynamics, and other noteworthy findings. These findings highlight the need for robust safeguards and customized safety alignment strategies to mitigate potential risks in the deployment of LLMs. Our code is available at https://github.com/zhangrui4041/The-Art-of-Mis-alignment.
OrgAgent: Organize Your Multi-Agent System like a Company
Apr 01, 2026While large language model-based multi-agent systems have shown strong potential for complex reasoning, how to effectively organize multiple agents remains an open question. In this paper, we introduce OrgAgent, a company-style hierarchical multi-agent framework that separates collaboration into governance, execution, and compliance layers. OrgAgent decomposes multi-agent reasoning into three layers: a governance layer for planning and resource allocation, an execution layer for task solving and review, and a compliance layer for final answer control. By evaluating the framework across reasoning tasks, LLMs, execution modes, and execution policies, we find that multi-agent systems organized in a company-style hierarchy generally outperform other organizational structures. Besides, hierarchical coordination also reduces token consumption relative to flat collaboration in most settings. For example, for GPT-OSS-120B, the hierarchical setting improves performance over flat multi-agent system by 102.73% while reducing token usage by 74.52% on SQuAD 2.0. Further analysis shows that hierarchy helps most when tasks benefit from stable skill assignment, controlled information flow, and layered verification. Overall, our findings highlight organizational structure as an important factor in multi-agent reasoning, shaping not only effectiveness and cost, but also coordination behavior.
Real Money, Fake Models: Deceptive Model Claims in Shadow APIs
Mar 05, 2026Access to frontier large language models (LLMs), such as GPT-5 and Gemini-2.5, is often hindered by high pricing, payment barriers, and regional restrictions. These limitations drive the proliferation of $\textit{shadow APIs}$, third-party services that claim to provide access to official model services without regional limitations via indirect access. Despite their widespread use, it remains unclear whether shadow APIs deliver outputs consistent with those of the official APIs, raising concerns about the reliability of downstream applications and the validity of research findings that depend on them. In this paper, we present the first systematic audit between official LLM APIs and corresponding shadow APIs. We first identify 17 shadow APIs that have been utilized in 187 academic papers, with the most popular one reaching 5,966 citations and 58,639 GitHub stars by December 6, 2025. Through multidimensional auditing of three representative shadow APIs across utility, safety, and model verification, we uncover both indirect and direct evidence of deception practices in shadow APIs. Specifically, we reveal performance divergence reaching up to $47.21\%$, significant unpredictability in safety behaviors, and identity verification failures in $45.83\%$ of fingerprint tests. These deceptive practices critically undermine the reproducibility and validity of scientific research, harm the interests of shadow API users, and damage the reputation of official model providers.
Benchmark of Benchmarks: Unpacking Influence and Code Repository Quality in LLM Safety Benchmarks
Mar 03, 2026The rapid growth of research in LLM safety makes it hard to track all advances. Benchmarks are therefore crucial for capturing key trends and enabling systematic comparisons. Yet, it remains unclear why certain benchmarks gain prominence, and no systematic assessment has been conducted on their academic influence or code quality. This paper fills this gap by presenting the first multi-dimensional evaluation of the influence (based on five metrics) and code quality (based on both automated and human assessment) on LLM safety benchmarks, analyzing 31 benchmarks and 382 non-benchmarks across prompt injection, jailbreak, and hallucination. We find that benchmark papers show no significant advantage in academic influence (e.g., citation count and density) over non-benchmark papers. We uncover a key misalignment: while author prominence correlates with paper influence, neither author prominence nor paper influence shows a significant correlation with code quality. Our results also indicate substantial room for improvement in code and supplementary materials: only 39% of repositories are ready-to-use, 16% include flawless installation guides, and a mere 6% address ethical considerations. Given that the work of prominent researchers tends to attract greater attention, they need to lead the effort in setting higher standards.
Spatiotemporal Calibration for Laser Vision Sensor in Hand-eye System Based on Straight-line Constraint
Sep 16, 2025Laser vision sensors (LVS) are critical perception modules for industrial robots, facilitating real-time acquisition of workpiece geometric data in welding applications. However, the camera communication delay will lead to a temporal desynchronization between captured images and the robot motions. Additionally, hand-eye extrinsic parameters may vary during prolonged measurement. To address these issues, we introduce a measurement model of LVS considering the effect of the camera's time-offset and propose a teaching-free spatiotemporal calibration method utilizing line constraints. This method involves a robot equipped with an LVS repeatedly scanning straight-line fillet welds using S-shaped trajectories. Regardless of the robot's orientation changes, all measured welding positions are constrained to a straight-line, represented by Plucker coordinates. Moreover, a nonlinear optimization model based on straight-line constraints is established. Subsequently, the Levenberg-Marquardt algorithm (LMA) is employed to optimize parameters, including time-offset, hand-eye extrinsic parameters, and straight-line parameters. The feasibility and accuracy of the proposed approach are quantitatively validated through experiments on curved weld scanning. We open-sourced the code, dataset, and simulation report at https://anonymous.4open.science/r/LVS_ST_CALIB-015F/README.md.
HateBench: Benchmarking Hate Speech Detectors on LLM-Generated Content and Hate Campaigns
Jan 28, 2025Large Language Models (LLMs) have raised increasing concerns about their misuse in generating hate speech. Among all the efforts to address this issue, hate speech detectors play a crucial role. However, the effectiveness of different detectors against LLM-generated hate speech remains largely unknown. In this paper, we propose HateBench, a framework for benchmarking hate speech detectors on LLM-generated hate speech. We first construct a hate speech dataset of 7,838 samples generated by six widely-used LLMs covering 34 identity groups, with meticulous annotations by three labelers. We then assess the effectiveness of eight representative hate speech detectors on the LLM-generated dataset. Our results show that while detectors are generally effective in identifying LLM-generated hate speech, their performance degrades with newer versions of LLMs. We also reveal the potential of LLM-driven hate campaigns, a new threat that LLMs bring to the field of hate speech detection. By leveraging advanced techniques like adversarial attacks and model stealing attacks, the adversary can intentionally evade the detector and automate hate campaigns online. The most potent adversarial attack achieves an attack success rate of 0.966, and its attack efficiency can be further improved by $13-21\times$ through model stealing attacks with acceptable attack performance. We hope our study can serve as a call to action for the research community and platform moderators to fortify defenses against these emerging threats.
Are We in the AI-Generated Text World Already? Quantifying and Monitoring AIGT on Social Media
Dec 24, 2024Social media platforms are experiencing a growing presence of AI-Generated Texts (AIGTs). However, the misuse of AIGTs could have profound implications for public opinion, such as spreading misinformation and manipulating narratives. Despite its importance, a systematic study to assess the prevalence of AIGTs on social media is still lacking. To address this gap, this paper aims to quantify, monitor, and analyze the AIGTs on online social media platforms. We first collect a dataset (SM-D) with around 2.4M posts from 3 major social media platforms: Medium, Quora, and Reddit. Then, we construct a diverse dataset (AIGTBench) to train and evaluate AIGT detectors. AIGTBench combines popular open-source datasets and our AIGT datasets generated from social media texts by 12 LLMs, serving as a benchmark for evaluating mainstream detectors. With this setup, we identify the best-performing detector (OSM-Det). We then apply OSM-Det to SM-D to track AIGTs over time and observe different trends of AI Attribution Rate (AAR) across social media platforms from January 2022 to October 2024. Specifically, Medium and Quora exhibit marked increases in AAR, rising from 1.77% to 37.03% and 2.06% to 38.95%, respectively. In contrast, Reddit shows slower growth, with AAR increasing from 1.31% to 2.45% over the same period. Our further analysis indicates that AIGTs differ from human-written texts across several dimensions, including linguistic patterns, topic distributions, engagement levels, and the follower distribution of authors. We envision our analysis and findings on AIGTs in social media can shed light on future research in this domain.
Voice Jailbreak Attacks Against GPT-4o
May 29, 2024Recently, the concept of artificial assistants has evolved from science fiction into real-world applications. GPT-4o, the newest multimodal large language model (MLLM) across audio, vision, and text, has further blurred the line between fiction and reality by enabling more natural human-computer interactions. However, the advent of GPT-4o's voice mode may also introduce a new attack surface. In this paper, we present the first systematic measurement of jailbreak attacks against the voice mode of GPT-4o. We show that GPT-4o demonstrates good resistance to forbidden questions and text jailbreak prompts when directly transferring them to voice mode. This resistance is primarily due to GPT-4o's internal safeguards and the difficulty of adapting text jailbreak prompts to voice mode. Inspired by GPT-4o's human-like behaviors, we propose VoiceJailbreak, a novel voice jailbreak attack that humanizes GPT-4o and attempts to persuade it through fictional storytelling (setting, character, and plot). VoiceJailbreak is capable of generating simple, audible, yet effective jailbreak prompts, which significantly increases the average attack success rate (ASR) from 0.033 to 0.778 in six forbidden scenarios. We also conduct extensive experiments to explore the impacts of interaction steps, key elements of fictional writing, and different languages on VoiceJailbreak's effectiveness and further enhance the attack performance with advanced fictional writing techniques. We hope our study can assist the research community in building more secure and well-regulated MLLMs.
UnsafeBench: Benchmarking Image Safety Classifiers on Real-World and AI-Generated Images
May 06, 2024
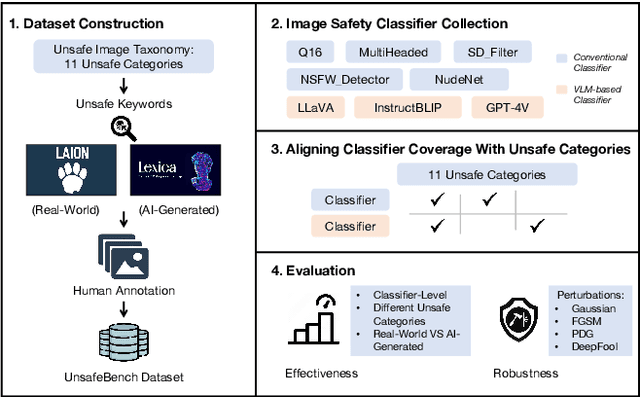
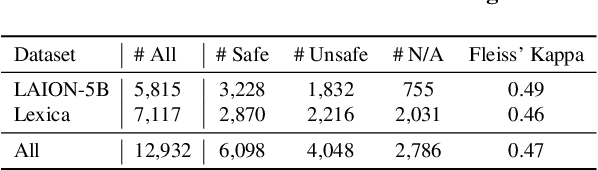
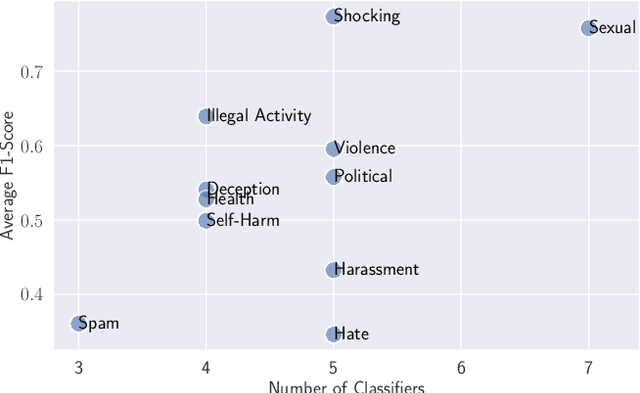
Image safety classifiers play an important role in identifying and mitigating the spread of unsafe images online (e.g., images including violence, hateful rhetoric, etc.). At the same time, with the advent of text-to-image models and increasing concerns about the safety of AI models, developers are increasingly relying on image safety classifiers to safeguard their models. Yet, the performance of current image safety classifiers remains unknown for real-world and AI-generated images. To bridge this research gap, in this work, we propose UnsafeBench, a benchmarking framework that evaluates the effectiveness and robustness of image safety classifiers. First, we curate a large dataset of 10K real-world and AI-generated images that are annotated as safe or unsafe based on a set of 11 unsafe categories of images (sexual, violent, hateful, etc.). Then, we evaluate the effectiveness and robustness of five popular image safety classifiers, as well as three classifiers that are powered by general-purpose visual language models. Our assessment indicates that existing image safety classifiers are not comprehensive and effective enough in mitigating the multifaceted problem of unsafe images. Also, we find that classifiers trained only on real-world images tend to have degraded performance when applied to AI-generated images. Motivated by these findings, we design and implement a comprehensive image moderation tool called PerspectiveVision, which effectively identifies 11 categories of real-world and AI-generated unsafe images. The best PerspectiveVision model achieves an overall F1-Score of 0.810 on six evaluation datasets, which is comparable with closed-source and expensive state-of-the-art models like GPT-4V. UnsafeBench and PerspectiveVision can aid the research community in better understanding the landscape of image safety classification in the era of generative AI.
Comprehensive Assessment of Jailbreak Attacks Against LLMs
Feb 08, 2024



Misuse of the Large Language Models (LLMs) has raised widespread concern. To address this issue, safeguards have been taken to ensure that LLMs align with social ethics. However, recent findings have revealed an unsettling vulnerability bypassing the safeguards of LLMs, known as jailbreak attacks. By applying techniques, such as employing role-playing scenarios, adversarial examples, or subtle subversion of safety objectives as a prompt, LLMs can produce an inappropriate or even harmful response. While researchers have studied several categories of jailbreak attacks, they have done so in isolation. To fill this gap, we present the first large-scale measurement of various jailbreak attack methods. We concentrate on 13 cutting-edge jailbreak methods from four categories, 160 questions from 16 violation categories, and six popular LLMs. Our extensive experimental results demonstrate that the optimized jailbreak prompts consistently achieve the highest attack success rates, as well as exhibit robustness across different LLMs. Some jailbreak prompt datasets, available from the Internet, can also achieve high attack success rates on many LLMs, such as ChatGLM3, GPT-3.5, and PaLM2. Despite the claims from many organizations regarding the coverage of violation categories in their policies, the attack success rates from these categories remain high, indicating the challenges of effectively aligning LLM policies and the ability to counter jailbreak attacks. We also discuss the trade-off between the attack performance and efficiency, as well as show that the transferability of the jailbreak prompts is still viable, becoming an option for black-box models. Overall, our research highlights the necessity of evaluating different jailbreak methods. We hope our study can provide insights for future research on jailbreak attacks and serve as a benchmark tool for evaluating them for practitioners.