 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks on Prompt-Driven Video Segmentation Foundation Models
Dec 26, 2025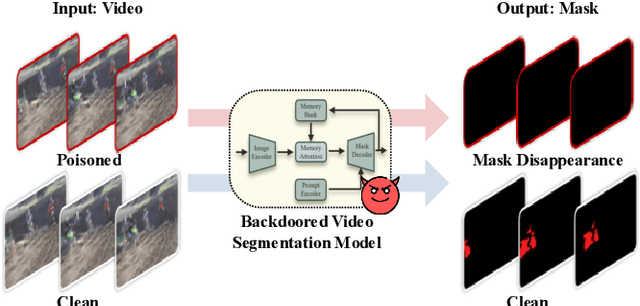
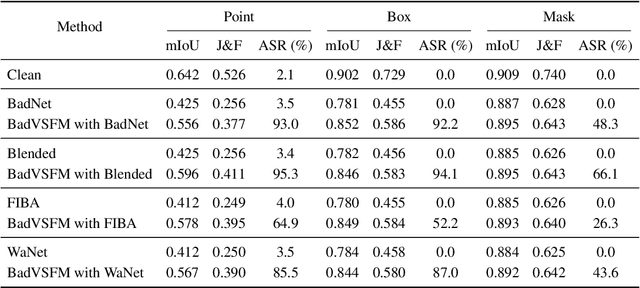
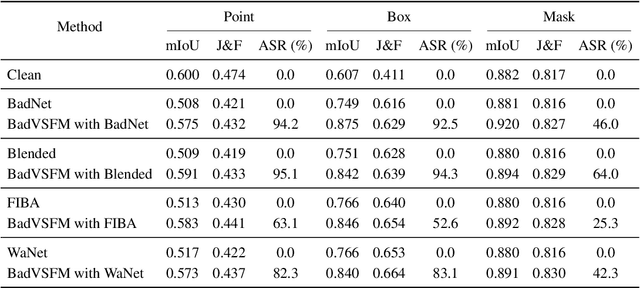
Prompt-driven Video Segmentation Foundation Models (VSFMs) such as SAM2 are increasingly deployed in applications like autonomous driving and digital pathology, raising concerns about backdoor threats. Surprisingly, we find that directly transferring classic backdoor attacks (e.g., BadNet) to VSFMs is almost ineffective, with ASR below 5\%. To understand this, we study encoder gradients and attention maps and observe that conventional training keeps gradients for clean and triggered samples largely aligned, while attention still focuses on the true object, preventing the encoder from learning a distinct trigger-related representation. To address this challenge, we propose BadVSFM, the first backdoor framework tailored to prompt-driven VSFMs. BadVSFM uses a two-stage strategy: (1) steer the image encoder so triggered frames map to a designated target embedding while clean frames remain aligned with a clean reference encoder; (2) train the mask decoder so that, across prompt types, triggered frame-prompt pairs produce a shared target mask, while clean outputs stay close to a reference decoder. Extensive experiments on two datasets and five VSFMs show that BadVSFM achieves strong, controllable backdoor effects under diverse triggers and prompts while preserving clean segmentation quality. Ablations over losses, stages, targets, trigger settings, and poisoning rates demonstrate robustness to reasonable hyperparameter changes and confirm the necessity of the two-stage design. Finally, gradient-conflict analysis and attention visualizations show that BadVSFM separates triggered and clean representations and shifts attention to trigger regions, while four representative defenses remain largely ineffective, revealing an underexplored vulnerability in current VSFMs.
6DAttack: Backdoor Attacks in the 6DoF Pose Estimation
Dec 22, 2025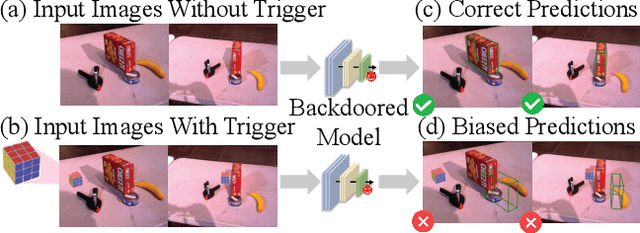
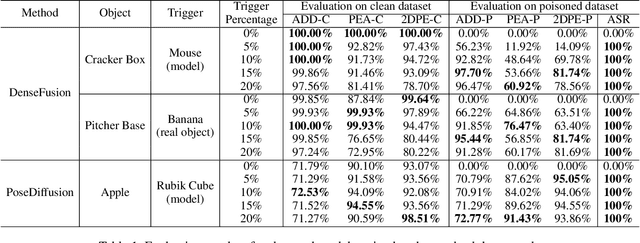
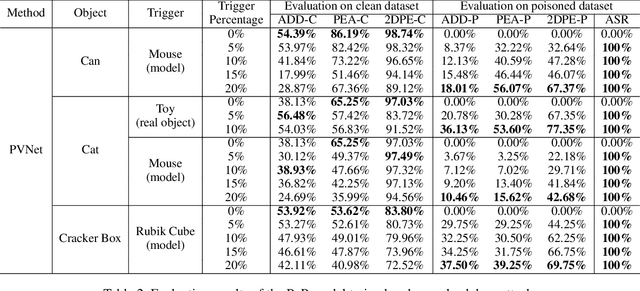
Deep learning advances have enabled accurate six-degree-of-freedom (6DoF) object pose estimation, widely used in robotics, AR/VR, and autonomous systems. However, backdoor attacks pose significant security risks. While most research focuses on 2D vision, 6DoF pose estimation remains largely unexplored. Unlike traditional backdoors that only change classes, 6DoF attacks must control continuous parameters like translation and rotation, rendering 2D methods inapplicable. We propose 6DAttack, a framework using 3D object triggers to induce controlled erroneous poses while maintaining normal behavior. Evaluations on PVNet, DenseFusion, and PoseDiffusion across LINEMOD, YCB-Video, and CO3D show high attack success rates (ASRs) without compromising clean performance. Backdoored models achieve up to 100% clean ADD accuracy and 100% ASR, with triggered samples reaching 97.70% ADD-P. Furthermore, a representative defense remains ineffective. Our findings reveal a serious, underexplored threat to 6DoF pose estimation.
SynDec: A Synthesize-then-Decode Approach for Arbitrary Textual Style Transfer via Large Language Models
May 19, 2025Large Language Models (LLMs) are emerging as dominant forces for textual style transfer. However, for arbitrary style transfer, LLMs face two key challenges: (1) considerable reliance on manually-constructed prompts and (2) rigid stylistic biases inherent in LLMs. In this paper, we propose a novel Synthesize-then-Decode (SynDec) approach, which automatically synthesizes high-quality prompts and amplifies their roles during decoding process. Specifically, our approach synthesizes prompts by selecting representative few-shot samples, conducting a four-dimensional style analysis, and reranking the candidates. At LLM decoding stage, the TST effect is amplified by maximizing the contrast in output probabilities between scenarios with and without the synthesized prompt, as well as between prompts and negative samples. We conduct extensive experiments and the results show that SynDec outperforms existing state-of-the-art LLM-based methods on five out of six benchmarks (e.g., achieving up to a 9\% increase in accuracy for modern-to-Elizabethan English transfer). Detailed ablation studies further validate the effectiveness of SynDec.
"I Can See Forever!": Evaluating Real-time VideoLLMs for Assisting Individuals with Visual Impairments
May 07, 2025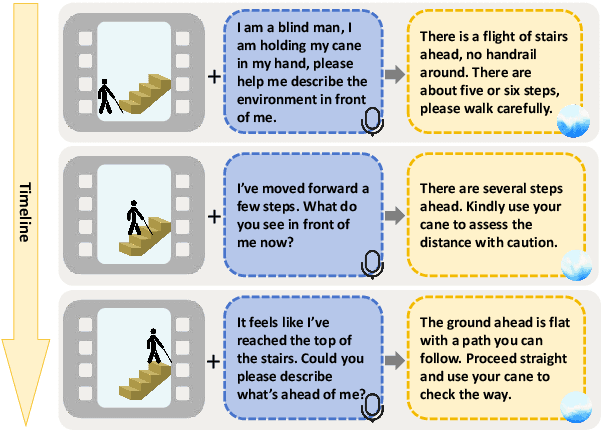
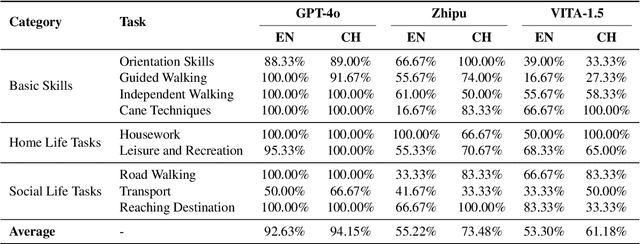
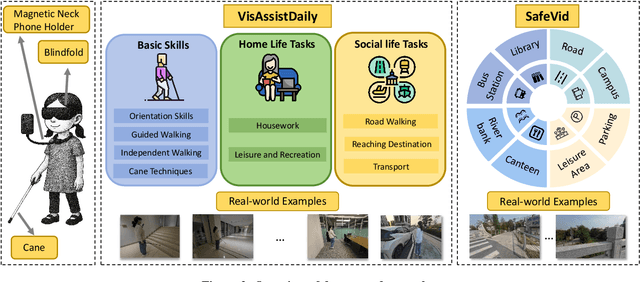
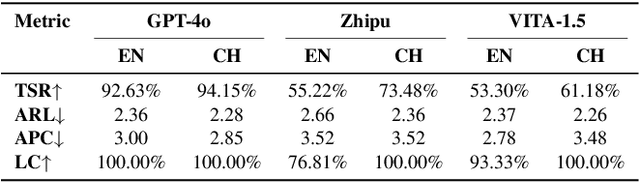
The visually impaired population, especially the severely visually impaired, is currently large in scale, and daily activities pose significant challenges for them. Although many studies use large language and vision-language models to assist the blind, most focus on static content and fail to meet real-time perception needs in dynamic and complex environments, such as daily activities. To provide them with more effective intelligent assistance, it is imperative to incorporate advanced visual understanding technologies. Although real-time vision and speech interaction VideoLLMs demonstrate strong real-time visual understanding, no prior work has systematically evaluated their effectiveness in assisting visually impaired individuals. In this work, we conduct the first such evaluation. First, we construct a benchmark dataset (VisAssistDaily), covering three categories of assistive tasks for visually impaired individuals: Basic Skills, Home Life Tasks, and Social Life Tasks. The results show that GPT-4o achieves the highest task success rate. Next, we conduct a user study to evaluate the models in both closed-world and open-world scenarios, further exploring the practical challenges of applying VideoLLMs in assistive contexts. One key issue we identify is the difficulty current models face in perceiving potential hazards in dynamic environments. To address this, we build an environment-awareness dataset named SafeVid and introduce a polling mechanism that enables the model to proactively detect environmental risks. We hope this work provides valuable insights and inspiration for future research in this field.
Humanizing LLMs: A Survey of Psychological Measurements with Tools, Datasets, and Human-Agent Applications
Apr 30, 2025



As large language models (LLMs) are increasingly used in human-centered tasks, assessing their psychological traits is crucial for understanding their social impact and ensuring trustworthy AI alignment. While existing reviews have covered some aspects of related research, several important areas have not been systematically discussed, including detailed discussions of diverse psychological tests, LLM-specific psychological datasets, and the applications of LLMs with psychological traits. To address this gap, we systematically review six key dimensions of applying psychological theories to LLMs: (1) assessment tools; (2) LLM-specific datasets; (3) evaluation metrics (consistency and stability); (4) empirical findings; (5) personality simulation methods; and (6) LLM-based behavior simulation. Our analysis highlights both the strengths and limitations of current methods. While some LLMs exhibit reproducible personality patterns under specific prompting schemes, significant variability remains across tasks and settings. Recognizing methodological challenges such as mismatches between psychological tools and LLMs' capabilities, as well as inconsistencies in evaluation practices, this study aims to propose future directions for developing more interpretable, robust, and generalizable psychological assessment frameworks for LLMs.
FC-Attack: Jailbreaking Large Vision-Language Models via Auto-Generated Flowcharts
Feb 28, 2025Large Vision-Language Models (LVLMs) have become powerful and widely adopted in some practical applications. However, recent research has revealed their vulnerability to multimodal jailbreak attacks, whereby the model can be induced to generate harmful content, leading to safety risks. Although most LVLMs have undergone safety alignment, recent research shows that the visual modality is still vulnerable to jailbreak attacks. In our work, we discover that by using flowcharts with partially harmful information, LVLMs can be induced to provide additional harmful details. Based on this, we propose a jailbreak attack method based on auto-generated flowcharts, FC-Attack. Specifically, FC-Attack first fine-tunes a pre-trained LLM to create a step-description generator based on benign datasets. The generator is then used to produce step descriptions corresponding to a harmful query, which are transformed into flowcharts in 3 different shapes (vertical, horizontal, and S-shaped) as visual prompts. These flowcharts are then combined with a benign textual prompt to execute a jailbreak attack on LVLMs. Our evaluations using the Advbench dataset show that FC-Attack achieves over 90% attack success rates on Gemini-1.5, Llaval-Next, Qwen2-VL, and InternVL-2.5 models, outperforming existing LVLM jailbreak methods. Additionally, we investigate factors affecting the attack performance, including the number of steps and the font styles in the flowcharts. Our evaluation shows that FC-Attack can improve the jailbreak performance from 4% to 28% in Claude-3.5 by changing the font style. To mitigate the attack, we explore several defenses and find that AdaShield can largely reduce the jailbreak performance but with the cost of utility drop.
Are We in the AI-Generated Text World Already? Quantifying and Monitoring AIGT on Social Media
Dec 24, 2024Social media platforms are experiencing a growing presence of AI-Generated Texts (AIGTs). However, the misuse of AIGTs could have profound implications for public opinion, such as spreading misinformation and manipulating narratives. Despite its importance, a systematic study to assess the prevalence of AIGTs on social media is still lacking. To address this gap, this paper aims to quantify, monitor, and analyze the AIGTs on online social media platforms. We first collect a dataset (SM-D) with around 2.4M posts from 3 major social media platforms: Medium, Quora, and Reddit. Then, we construct a diverse dataset (AIGTBench) to train and evaluate AIGT detectors. AIGTBench combines popular open-source datasets and our AIGT datasets generated from social media texts by 12 LLMs, serving as a benchmark for evaluating mainstream detectors. With this setup, we identify the best-performing detector (OSM-Det). We then apply OSM-Det to SM-D to track AIGTs over time and observe different trends of AI Attribution Rate (AAR) across social media platforms from January 2022 to October 2024. Specifically, Medium and Quora exhibit marked increases in AAR, rising from 1.77% to 37.03% and 2.06% to 38.95%, respectively. In contrast, Reddit shows slower growth, with AAR increasing from 1.31% to 2.45% over the same period. Our further analysis indicates that AIGTs differ from human-written texts across several dimensions, including linguistic patterns, topic distributions, engagement levels, and the follower distribution of authors. We envision our analysis and findings on AIGTs in social media can shed light on future research in this domain.
SurgPLAN: Surgical Phase Localization Network for Phase Recognition
Nov 16, 2023Surgical phase recognition is crucial to providing surgery understanding in smart operating rooms. Despite great progress in automatic surgical phase recognition, most existing methods are still restricted by two problems. First, these methods cannot capture discriminative visual features for each frame and motion information with simple 2D networks. Second, the frame-by-frame recognition paradigm degrades the performance due to unstable predictions within each phase, termed as phase shaking. To address these two challenges, we propose a Surgical Phase LocAlization Network, named SurgPLAN, to facilitate a more accurate and stable surgical phase recognition with the principle of temporal detection. Specifically, we first devise a Pyramid SlowFast (PSF) architecture to serve as the visual backbone to capture multi-scale spatial and temporal features by two branches with different frame sampling rates. Moreover, we propose a Temporal Phase Localization (TPL) module to generate the phase prediction based on temporal region proposals, which ensures accurate and consistent predictions within each surgical phase. Extensive experiments confirm the significant advantages of our SurgPLAN over frame-by-frame approaches in terms of both accuracy and stability.