 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAHG: Sector-Anisotropic Hyperbolic Graph Model for Social Bot Detection
May 28, 2026LLM-driven social bots can generate fluent, human-like text, reducing the discriminative advantage of content-based detection alone. However, coordinated campaigns still leave relational patterns -- interactions, behavioral similarity, shared neighborhoods, community positions, and coordinated activity -- that graph-based methods can exploit. Existing graph detectors face two challenges when exploiting such evidence. First, Euclidean GNNs distort hierarchical and scale-free social graphs; while hyperbolic geometry addresses this volume-growth mismatch, fixed-curvature models still assign uniform geometric resolution to structural directions with different densities and separation needs. Second, relational evidence is not always reliable: sophisticated bots forge heterophilic connections with genuine users, causing neighborhood aggregation to mix bot and human signals and dilute account-level evidence. We propose \textsc{SAHG} (Sector-Anisotropic Hyperbolic Graph), addressing both challenges. \textsc{SAHG} learns a direction-dependent curvature field $γ(u)$ that adapts geometric resolution across structural directions, and uses sector prototypes to convert angular concentration and alignment into classifier-readable features. To prevent contaminated aggregation from overwhelming account-level evidence, \textsc{SAHG} encodes per-account features and graph-neighborhood representations in two independent SAH channels, fusing them only at the classifier. Experiments on Fox8-23, BotSim-24, and MGTAB show that \textsc{SAHG} achieves the highest accuracy and F1 on all three benchmarks, outperforming feature-based, graph-based, LLM-based, and isotropic hyperbolic baselines. Ablation and geometric analyses confirm the effectiveness of the anisotropic geometry and dual-channel design.
NORA: A Harness-Engineered Autonomous Research Agent for End-to-End Spatial Data Science
May 03, 2026The automation of scientific research workflows has emerged as a transformative frontier in artificial intelligence, yet existing autonomous research agents remain largely domain-agnostic, lacking the specialized reasoning, method selection, and data acquisition capabilities required for rigorous spatial data science. This paper introduces NORA (Night Owl Research Agent), a harness-engineered, multi-agent autonomous research system purpose-built for GIScience and spatial data science. NORA orchestrates the complete research lifecycle through a skills-first architecture comprising 21 domain-specialized workflow skills, 9 specialist sub-agents, and custom Model Context Protocol (MCP) servers. Central to the system's design are two novel domain-specialized skills: a spatial analysis skill unit that encodes decision frameworks for exploratory spatial data analysis, spatial regression, and diagnostics; and a spatial data download skill that supports reproducible acquisition from authoritative geospatial data sources. We formalize the concept of harness engineering for scientific research agents, demonstrating how lifecycle hooks, safety gates, generator-evaluator separation, human-in-the-loop, and state persistence ensure reliable and reproducible autonomous research. We evaluate NORA through case studies by 6 domain specialists and 3 LLM reviewers across seven dimensions (novelty, quality, rigor, etc). Results demonstrate that domain-specialized harness engineering substantially improves the efficiency and quality of research output compared to general-purpose agent configurations.
Telogenesis: Goal Is All U Need
Mar 10, 2026Goal-conditioned systems assume goals are provided externally. We ask whether attentional priorities can emerge endogenously from an agent's internal cognitive state. We propose a priority function that generates observation targets from three epistemic gaps: ignorance (posterior variance), surprise (prediction error), and staleness (temporal decay of confidence in unobserved variables). We validate this in two systems: a minimal attention-allocation environment (2,000 runs) and a modular, partially observable world (500 runs). Ablation shows each component is necessary. A key finding is metric-dependent reversal: under global prediction error, coverage-based rotation wins; under change detection latency, priority-guided allocation wins, with advantage growing monotonically with dimensionality (d = -0.95 at N=48, p < 10^-6). Detection latency follows a power law in attention budget, with a steeper exponent for priority-guided allocation (0.55 vs. 0.40). When the decay rate is made learnable per variable, the system spontaneously recovers environmental volatility structure without supervision (t = 22.5, p < 10^-6). We demonstrate that epistemic gaps alone, without external reward, suffice to generate adaptive priorities that outperform fixed strategies and recover latent environmental structure.
Polynomial Convergence of Riemannian Diffusion Models
Jan 05, 2026Diffusion models have demonstrated remarkable empirical success in the recent years and are considered one of the state-of-the-art generative models in modern AI. These models consist of a forward process, which gradually diffuses the data distribution to a noise distribution spanning the whole space, and a backward process, which inverts this transformation to recover the data distribution from noise. Most of the existing literature assumes that the underlying space is Euclidean. However, in many practical applications, the data are constrained to lie on a submanifold of Euclidean space. Addressing this setting, De Bortoli et al. (2022) introduced Riemannian diffusion models and proved that using an exponentially small step size yields a small sampling error in the Wasserstein distance, provided the data distribution is smooth and strictly positive, and the score estimate is $L_\infty$-accurate. In this paper, we greatly strengthen this theory by establishing that, under $L_2$-accurate score estimate, a {\em polynomially small stepsize} suffices to guarantee small sampling error in the total variation distance, without requiring smoothness or positivity of the data distribution. Our analysis only requires mild and standard curvature assumptions on the underlying manifold. The main ingredients in our analysis are Li-Yau estimate for the log-gradient of heat kernel, and Minakshisundaram-Pleijel parametrix expansion of the perturbed heat equation. Our approach opens the door to a sharper analysis of diffusion models on non-Euclidean spaces.
InvarGC: Invariant Granger Causality for Heterogeneous Interventional Time Series under Latent Confounding
Oct 22, 2025Granger causality is widely used for causal structure discovery in complex systems from multivariate time series data. Traditional Granger causality tests based on linear models often fail to detect even mild non-linear causal relationships. Therefore, numerous recent studies have investigated non-linear Granger causality methods, achieving improved performance. However, these methods often rely on two key assumptions: causal sufficiency and known interventional targets. Causal sufficiency assumes the absence of latent confounders, yet their presence can introduce spurious correlations. Moreover, real-world time series data usually come from heterogeneous environments, without prior knowledge of interventions. Therefore, in practice, it is difficult to distinguish intervened environments from non-intervened ones, and even harder to identify which variables or timesteps are affected. To address these challenges, we propose Invariant Granger Causality (InvarGC), which leverages cross-environment heterogeneity to mitigate the effects of latent confounding and to distinguish intervened from non-intervened environments with edge-level granularity, thereby recovering invariant causal relations. In addition, we establish the identifiability under these conditions. Extensive experiments on both synthetic and real-world datasets demonstrate the competitive performance of our approach compared to state-of-the-art methods.
DEGS: Deformable Event-based 3D Gaussian Splatting from RGB and Event Stream
Oct 09, 2025Reconstructing Dynamic 3D Gaussian Splatting (3DGS) from low-framerate RGB videos is challenging. This is because large inter-frame motions will increase the uncertainty of the solution space. For example, one pixel in the first frame might have more choices to reach the corresponding pixel in the second frame. Event cameras can asynchronously capture rapid visual changes and are robust to motion blur, but they do not provide color information. Intuitively, the event stream can provide deterministic constraints for the inter-frame large motion by the event trajectories. Hence, combining low-temporal-resolution images with high-framerate event streams can address this challenge. However, it is challenging to jointly optimize Dynamic 3DGS using both RGB and event modalities due to the significant discrepancy between these two data modalities. This paper introduces a novel framework that jointly optimizes dynamic 3DGS from the two modalities. The key idea is to adopt event motion priors to guide the optimization of the deformation fields. First, we extract the motion priors encoded in event streams by using the proposed LoCM unsupervised fine-tuning framework to adapt an event flow estimator to a certain unseen scene. Then, we present the geometry-aware data association method to build the event-Gaussian motion correspondence, which is the primary foundation of the pipeline, accompanied by two useful strategies, namely motion decomposition and inter-frame pseudo-label. Extensive experiments show that our method outperforms existing image and event-based approaches across synthetic and real scenes and prove that our method can effectively optimize dynamic 3DGS with the help of event data.
SwiftSpec: Ultra-Low Latency LLM Decoding by Scaling Asynchronous Speculative Decoding
Jun 12, 2025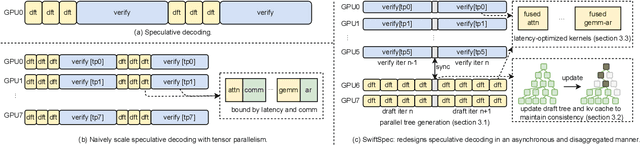


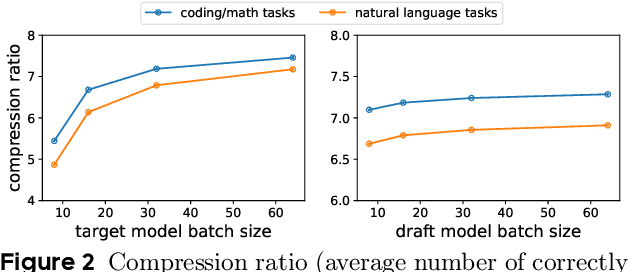
Low-latency decoding for large language models (LLMs) is crucial for applications like chatbots and code assistants, yet generating long outputs remains slow in single-query settings. Prior work on speculative decoding (which combines a small draft model with a larger target model) and tensor parallelism has each accelerated decoding. However, conventional approaches fail to apply both simultaneously due to imbalanced compute requirements (between draft and target models), KV-cache inconsistencies, and communication overheads under small-batch tensor-parallelism. This paper introduces SwiftSpec, a system that targets ultra-low latency for LLM decoding. SwiftSpec redesigns the speculative decoding pipeline in an asynchronous and disaggregated manner, so that each component can be scaled flexibly and remove draft overhead from the critical path. To realize this design, SwiftSpec proposes parallel tree generation, tree-aware KV cache management, and fused, latency-optimized kernels to overcome the challenges listed above. Across 5 model families and 6 datasets, SwiftSpec achieves an average of 1.75x speedup over state-of-the-art speculative decoding systems and, as a highlight, serves Llama3-70B at 348 tokens/s on 8 Nvidia Hopper GPUs, making it the fastest known system for low-latency LLM serving at this scale.
Refining Few-Step Text-to-Multiview Diffusion via Reinforcement Learning
May 26, 2025Text-to-multiview (T2MV) generation, which produces coherent multiview images from a single text prompt, remains computationally intensive, while accelerated T2MV methods using few-step diffusion models often sacrifice image fidelity and view consistency. To address this, we propose a novel reinforcement learning (RL) finetuning framework tailored for few-step T2MV diffusion models to jointly optimize per-view fidelity and cross-view consistency. Specifically, we first reformulate T2MV denoising across all views as a single unified Markov decision process, enabling multiview-aware policy optimization driven by a joint-view reward objective. Next, we introduce ZMV-Sampling, a test-time T2MV sampling technique that adds an inversion-denoising pass to reinforce both viewpoint and text conditioning, resulting in improved T2MV generation at the cost of inference time. To internalize its performance gains into the base sampling policy, we develop MV-ZigAL, a novel policy optimization strategy that uses reward advantages of ZMV-Sampling over standard sampling as learning signals for policy updates. Finally, noting that the joint-view reward objective under-optimizes per-view fidelity but naively optimizing single-view metrics neglects cross-view alignment, we reframe RL finetuning for T2MV diffusion models as a constrained optimization problem that maximizes per-view fidelity subject to an explicit joint-view constraint, thereby enabling more efficient and balanced policy updates. By integrating this constrained optimization paradigm with MV-ZigAL, we establish our complete RL finetuning framework, referred to as MVC-ZigAL, which effectively refines the few-step T2MV diffusion baseline in both fidelity and consistency while preserving its few-step efficiency.
FragFake: A Dataset for Fine-Grained Detection of Edited Images with Vision Language Models
May 21, 2025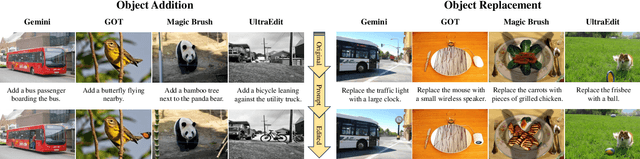


Fine-grained edited image detection of localized edits in images is crucial for assessing content authenticity, especially given that modern diffusion models and image editing methods can produce highly realistic manipulations. However, this domain faces three challenges: (1) Binary classifiers yield only a global real-or-fake label without providing localization; (2) Traditional computer vision methods often rely on costly pixel-level annotations; and (3) No large-scale, high-quality dataset exists for modern image-editing detection techniques. To address these gaps, we develop an automated data-generation pipeline to create FragFake, the first dedicated benchmark dataset for edited image detection, which includes high-quality images from diverse editing models and a wide variety of edited objects. Based on FragFake, we utilize Vision Language Models (VLMs) for the first time in the task of edited image classification and edited region localization. Experimental results show that fine-tuned VLMs achieve higher average Object Precision across all datasets, significantly outperforming pretrained models. We further conduct ablation and transferability analyses to evaluate the detectors across various configurations and editing scenarios. To the best of our knowledge, this work is the first to reformulate localized image edit detection as a vision-language understanding task, establishing a new paradigm for the field. We anticipate that this work will establish a solid foundation to facilitate and inspire subsequent research endeavors in the domain of multimodal content authenticity.
TUGS: Physics-based Compact Representation of Underwater Scenes by Tensorized Gaussian
May 12, 2025Underwater 3D scene reconstruction is crucial for undewater robotic perception and navigation. However, the task is significantly challenged by the complex interplay between light propagation, water medium, and object surfaces, with existing methods unable to model their interactions accurately. Additionally, expensive training and rendering costs limit their practical application in underwater robotic systems. Therefore, we propose Tensorized Underwater Gaussian Splatting (TUGS), which can effectively solve the modeling challenges of the complex interactions between object geometries and water media while achieving significant parameter reduction. TUGS employs lightweight tensorized higher-order Gaussians with a physics-based underwater Adaptive Medium Estimation (AME) module, enabling accurate simulation of both light attenuation and backscatter effects in underwater environments. Compared to other NeRF-based and GS-based methods designed for underwater, TUGS is able to render high-quality underwater images with faster rendering speeds and less memory usage. Extensive experiments on real-world underwater datasets have demonstrated that TUGS can efficiently achieve superior reconstruction quality using a limited number of parameters, making it particularly suitable for memory-constrained underwater UAV applications