 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination
Oct 27, 2025Enhancing the reasoning capabilities of Large Language Models (LLMs) is a key strategy for building Agents that "think then act." However, recent observations, like OpenAI's o3, suggest a paradox: stronger reasoning often coincides with increased hallucination, yet no prior work has systematically examined whether reasoning enhancement itself causes tool hallucination. To address this gap, we pose the central question: Does strengthening reasoning increase tool hallucination? To answer this, we introduce SimpleToolHalluBench, a diagnostic benchmark measuring tool hallucination in two failure modes: (i) no tool available, and (ii) only distractor tools available. Through controlled experiments, we establish three key findings. First, we demonstrate a causal relationship: progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains. Second, this effect transcends overfitting - training on non-tool tasks (e.g., mathematics) still amplifies subsequent tool hallucination. Third, the effect is method-agnostic, appearing when reasoning is instilled via supervised fine-tuning and when it is merely elicited at inference by switching from direct answers to step-by-step thinking. We also evaluate mitigation strategies including Prompt Engineering and Direct Preference Optimization (DPO), revealing a fundamental reliability-capability trade-off: reducing hallucination consistently degrades utility. Mechanistically, Reasoning RL disproportionately collapses tool-reliability-related representations, and hallucinations surface as amplified divergences concentrated in late-layer residual streams. These findings reveal that current reasoning enhancement methods inherently amplify tool hallucination, highlighting the need for new training objectives that jointly optimize for capability and reliability.
FragFake: A Dataset for Fine-Grained Detection of Edited Images with Vision Language Models
May 21, 2025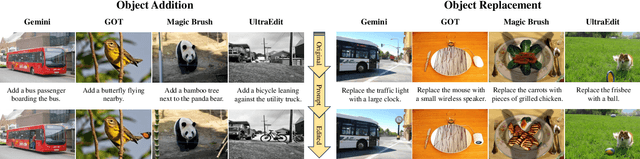


Fine-grained edited image detection of localized edits in images is crucial for assessing content authenticity, especially given that modern diffusion models and image editing methods can produce highly realistic manipulations. However, this domain faces three challenges: (1) Binary classifiers yield only a global real-or-fake label without providing localization; (2) Traditional computer vision methods often rely on costly pixel-level annotations; and (3) No large-scale, high-quality dataset exists for modern image-editing detection techniques. To address these gaps, we develop an automated data-generation pipeline to create FragFake, the first dedicated benchmark dataset for edited image detection, which includes high-quality images from diverse editing models and a wide variety of edited objects. Based on FragFake, we utilize Vision Language Models (VLMs) for the first time in the task of edited image classification and edited region localization. Experimental results show that fine-tuned VLMs achieve higher average Object Precision across all datasets, significantly outperforming pretrained models. We further conduct ablation and transferability analyses to evaluate the detectors across various configurations and editing scenarios. To the best of our knowledge, this work is the first to reformulate localized image edit detection as a vision-language understanding task, establishing a new paradigm for the field. We anticipate that this work will establish a solid foundation to facilitate and inspire subsequent research endeavors in the domain of multimodal content authenticity.
SEM: Reinforcement Learning for Search-Efficient Large Language Models
May 12, 2025Recent advancements in Large Language Models(LLMs) have demonstrated their capabilities not only in reasoning but also in invoking external tools, particularly search engines. However, teaching models to discern when to invoke search and when to rely on their internal knowledge remains a significant challenge. Existing reinforcement learning approaches often lead to redundant search behaviors, resulting in inefficiencies and over-cost. In this paper, we propose SEM, a novel post-training reinforcement learning framework that explicitly trains LLMs to optimize search usage. By constructing a balanced dataset combining MuSiQue and MMLU, we create scenarios where the model must learn to distinguish between questions it can answer directly and those requiring external retrieval. We design a structured reasoning template and employ Group Relative Policy Optimization(GRPO) to post-train the model's search behaviors. Our reward function encourages accurate answering without unnecessary search while promoting effective retrieval when needed. Experimental results demonstrate that our method significantly reduces redundant search operations while maintaining or improving answer accuracy across multiple challenging benchmarks. This framework advances the model's reasoning efficiency and extends its capability to judiciously leverage external knowledge.
Thought Manipulation: External Thought Can Be Efficient for Large Reasoning Models
Apr 18, 2025Recent advancements in large reasoning models (LRMs) have demonstrated the effectiveness of scaling test-time computation to enhance reasoning capabilities in multiple tasks. However, LRMs typically suffer from "overthinking" problems, where models generate significantly redundant reasoning steps while bringing limited performance gains. Existing work relies on fine-tuning to mitigate overthinking, which requires additional data, unconventional training setups, risky safety misalignment, and poor generalization. Through empirical analysis, we reveal an important characteristic of LRM behaviors that placing external CoTs generated by smaller models between the thinking token ($\texttt{<think>}$ and $\texttt{</think>)}$ can effectively manipulate the model to generate fewer thoughts. Building on these insights, we propose a simple yet efficient pipeline, ThoughtMani, to enable LRMs to bypass unnecessary intermediate steps and reduce computational costs significantly. We conduct extensive experiments to validate the utility and efficiency of ThoughtMani. For instance, when applied to QwQ-32B on the LiveBench/Code dataset, ThoughtMani keeps the original performance and reduces output token counts by approximately 30%, with little overhead from the CoT generator. Furthermore, we find that ThoughtMani enhances safety alignment by an average of 10%. Since model vendors typically serve models of different sizes simultaneously, ThoughtMani provides an effective way to construct more efficient and accessible LRMs for real-world applications.
Prompt Stealing Attacks Against Large Language Models
Feb 20, 2024The increasing reliance on large language models (LLMs) such as ChatGPT in various fields emphasizes the importance of ``prompt engineering,'' a technology to improve the quality of model outputs. With companies investing significantly in expert prompt engineers and educational resources rising to meet market demand, designing high-quality prompts has become an intriguing challenge. In this paper, we propose a novel attack against LLMs, named prompt stealing attacks. Our proposed prompt stealing attack aims to steal these well-designed prompts based on the generated answers. The prompt stealing attack contains two primary modules: the parameter extractor and the prompt reconstruction. The goal of the parameter extractor is to figure out the properties of the original prompts. We first observe that most prompts fall into one of three categories: direct prompt, role-based prompt, and in-context prompt. Our parameter extractor first tries to distinguish the type of prompts based on the generated answers. Then, it can further predict which role or how many contexts are used based on the types of prompts. Following the parameter extractor, the prompt reconstructor can be used to reconstruct the original prompts based on the generated answers and the extracted features. The final goal of the prompt reconstructor is to generate the reversed prompts, which are similar to the original prompts. Our experimental results show the remarkable performance of our proposed attacks. Our proposed attacks add a new dimension to the study of prompt engineering and call for more attention to the security issues on LLMs.
Conversation Reconstruction Attack Against GPT Models
Feb 05, 2024In recent times, significant advancements have been made in the field of large language models (LLMs), represented by GPT series models. To optimize task execution, users often engage in multi-round conversations with GPT models hosted in cloud environments. These multi-round conversations, potentially replete with private information, require transmission and storage within the cloud. However, this operational paradigm introduces additional attack surfaces. In this paper, we first introduce a specific Conversation Reconstruction Attack targeting GPT models. Our introduced Conversation Reconstruction Attack is composed of two steps: hijacking a session and reconstructing the conversations. Subsequently, we offer an exhaustive evaluation of the privacy risks inherent in conversations when GPT models are subjected to the proposed attack. However, GPT-4 demonstrates certain robustness to the proposed attacks. We then introduce two advanced attacks aimed at better reconstructing previous conversations, specifically the UNR attack and the PBU attack. Our experimental findings indicate that the PBU attack yields substantial performance across all models, achieving semantic similarity scores exceeding 0.60, while the UNR attack is effective solely on GPT-3.5. Our results reveal the concern about privacy risks associated with conversations involving GPT models and aim to draw the community's attention to prevent the potential misuse of these models' remarkable capabilities. We will responsibly disclose our findings to the suppliers of related large language models.
From Visual Prompt Learning to Zero-Shot Transfer: Mapping Is All You Need
Mar 09, 2023Visual prompt learning, as a newly emerged technique, leverages the knowledge learned by a large-scale pre-trained model and adapts it to downstream tasks through the usage of prompts. While previous research has focused on designing effective prompts, in this work, we argue that compared to prompt design, a good mapping strategy matters more. In this sense, we propose SeMap, a more effective mapping using the semantic alignment between the pre-trained model's knowledge and the downstream task. Our experimental results show that SeMap can largely boost the performance of visual prompt learning. Moreover, our experiments show that SeMap is capable of achieving competitive zero-shot transfer, indicating that it can perform the downstream task without any fine-tuning on the corresponding dataset. This demonstrates the potential of our proposed method to be used in a broader range of applications where the zero-shot transfer is desired. Results suggest that our proposed SeMap could lead to significant advancements in both visual prompt learning and zero-shot transfer. We hope with SeMap, we can help the community move forward to more efficient and lightweight utilization of large vision models.
Fine-Tuning Is All You Need to Mitigate Backdoor Attacks
Dec 18, 2022Backdoor attacks represent one of the major threats to machine learning models. Various efforts have been made to mitigate backdoors. However, existing defenses have become increasingly complex and often require high computational resources or may also jeopardize models' utility. In this work, we show that fine-tuning, one of the most common and easy-to-adopt machine learning training operations, can effectively remove backdoors from machine learning models while maintaining high model utility. Extensive experiments over three machine learning paradigms show that fine-tuning and our newly proposed super-fine-tuning achieve strong defense performance. Furthermore, we coin a new term, namely backdoor sequela, to measure the changes in model vulnerabilities to other attacks before and after the backdoor has been removed. Empirical evaluation shows that, compared to other defense methods, super-fine-tuning leaves limited backdoor sequela. We hope our results can help machine learning model owners better protect their models from backdoor threats. Also, it calls for the design of more advanced attacks in order to comprehensively assess machine learning models' backdoor vulnerabilities.
DE-FAKE: Detection and Attribution of Fake Images Generated by Text-to-Image Diffusion Models
Oct 13, 2022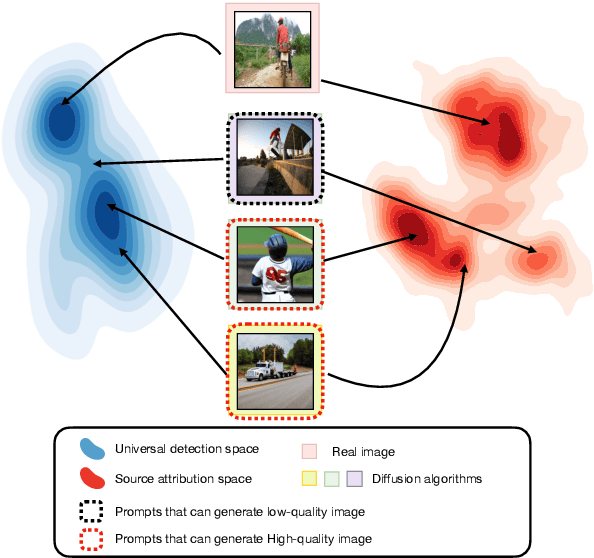
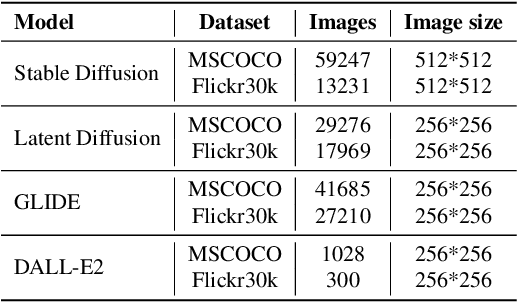
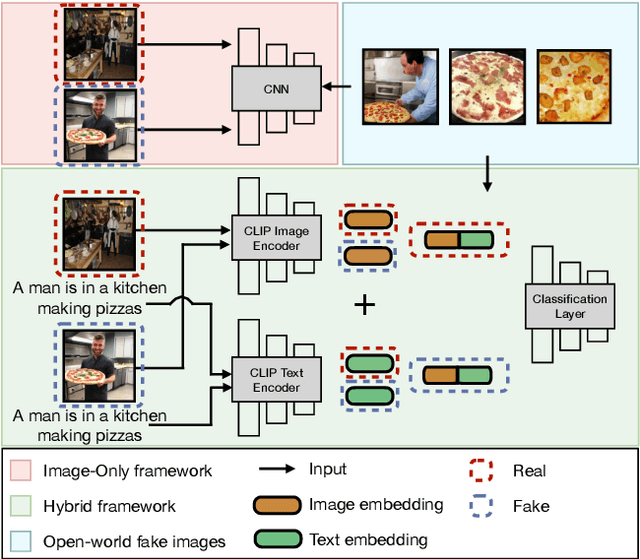
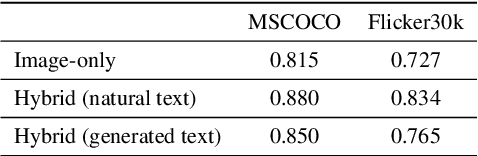
Diffusion models emerge to establish the new state of the art in the visual generation. In particular, text-to-image diffusion models that generate images based on caption descriptions have attracted increasing attention, impressed by their user controllability. Despite encouraging performance, they exaggerate concerns of fake image misuse and cast new pressures on fake image detection. In this work, we pioneer a systematic study of the authenticity of fake images generated by text-to-image diffusion models. In particular, we conduct comprehensive studies from two perspectives unique to the text-to-image model, namely, visual modality and linguistic modality. For visual modality, we propose universal detection that demonstrates fake images of these text-to-image diffusion models share common cues, which enable us to distinguish them apart from real images. We then propose source attribution that reveals the uniqueness of the fingerprints held by each diffusion model, which can be used to attribute each fake image to its model source. A variety of ablation and analysis studies further interpret the improvements from each of our proposed methods. For linguistic modality, we delve deeper to comprehensively analyze the impacts of text captions (called prompt analysis) on the image authenticity of text-to-image diffusion models, and reason the impacts to the detection and attribution performance of fake images. All findings contribute to the community's insight into the natural properties of text-to-image diffusion models, and we appeal to our community's consideration on the counterpart solutions, like ours, against the rapidly-evolving fake image generators.
Can't Steal? Cont-Steal! Contrastive Stealing Attacks Against Image Encoders
Jan 19, 2022
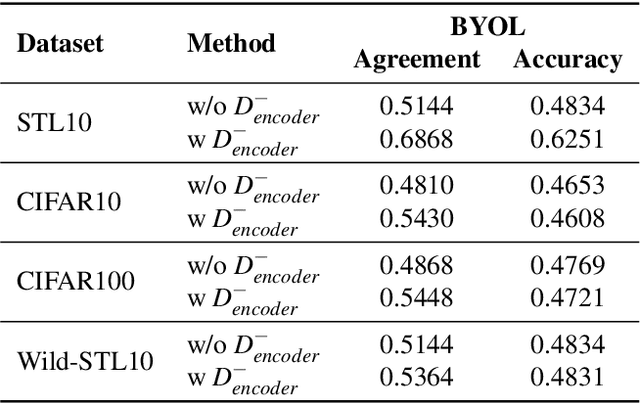

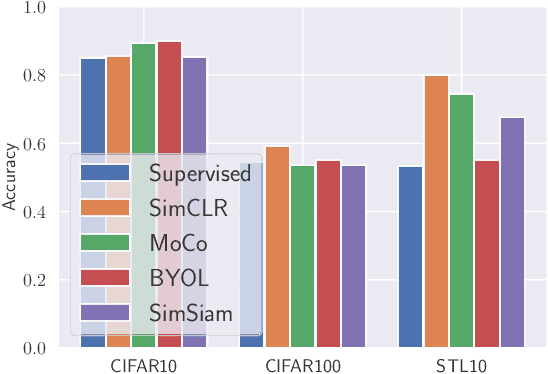
Unsupervised representation learning techniques have been developing rapidly to make full use of unlabeled images. They encode images into rich features that are oblivious to downstream tasks. Behind its revolutionary representation power, the requirements for dedicated model designs and a massive amount of computation resources expose image encoders to the risks of potential model stealing attacks -- a cheap way to mimic the well-trained encoder performance while circumventing the demanding requirements. Yet conventional attacks only target supervised classifiers given their predicted labels and/or posteriors, which leaves the vulnerability of unsupervised encoders unexplored. In this paper, we first instantiate the conventional stealing attacks against encoders and demonstrate their severer vulnerability compared with downstream classifiers. To better leverage the rich representation of encoders, we further propose Cont-Steal, a contrastive-learning-based attack, and validate its improved stealing effectiveness in various experiment settings. As a takeaway, we appeal to our community's attention to the intellectual property protection of representation learning techniques, especially to the defenses against encoder stealing attacks like ours.