 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLink Stealing Attacks Against Inductive Graph Neural Networks
May 09, 2024



A graph neural network (GNN) is a type of neural network that is specifically designed to process graph-structured data. Typically, GNNs can be implemented in two settings, including the transductive setting and the inductive setting. In the transductive setting, the trained model can only predict the labels of nodes that were observed at the training time. In the inductive setting, the trained model can be generalized to new nodes/graphs. Due to its flexibility, the inductive setting is the most popular GNN setting at the moment. Previous work has shown that transductive GNNs are vulnerable to a series of privacy attacks. However, a comprehensive privacy analysis of inductive GNN models is still missing. This paper fills the gap by conducting a systematic privacy analysis of inductive GNNs through the lens of link stealing attacks, one of the most popular attacks that are specifically designed for GNNs. We propose two types of link stealing attacks, i.e., posterior-only attacks and combined attacks. We define threat models of the posterior-only attacks with respect to node topology and the combined attacks by considering combinations of posteriors, node attributes, and graph features. Extensive evaluation on six real-world datasets demonstrates that inductive GNNs leak rich information that enables link stealing attacks with advantageous properties. Even attacks with no knowledge about graph structures can be effective. We also show that our attacks are robust to different node similarities and different graph features. As a counterpart, we investigate two possible defenses and discover they are ineffective against our attacks, which calls for more effective defenses.
Fine-Tuning Is All You Need to Mitigate Backdoor Attacks
Dec 18, 2022Backdoor attacks represent one of the major threats to machine learning models. Various efforts have been made to mitigate backdoors. However, existing defenses have become increasingly complex and often require high computational resources or may also jeopardize models' utility. In this work, we show that fine-tuning, one of the most common and easy-to-adopt machine learning training operations, can effectively remove backdoors from machine learning models while maintaining high model utility. Extensive experiments over three machine learning paradigms show that fine-tuning and our newly proposed super-fine-tuning achieve strong defense performance. Furthermore, we coin a new term, namely backdoor sequela, to measure the changes in model vulnerabilities to other attacks before and after the backdoor has been removed. Empirical evaluation shows that, compared to other defense methods, super-fine-tuning leaves limited backdoor sequela. We hope our results can help machine learning model owners better protect their models from backdoor threats. Also, it calls for the design of more advanced attacks in order to comprehensively assess machine learning models' backdoor vulnerabilities.
Data Poisoning Attacks Against Multimodal Encoders
Sep 30, 2022



Traditional machine learning (ML) models usually rely on large-scale labeled datasets to achieve strong performance. However, such labeled datasets are often challenging and expensive to obtain. Also, the predefined categories limit the model's ability to generalize to other visual concepts as additional labeled data is required. On the contrary, the newly emerged multimodal model, which contains both visual and linguistic modalities, learns the concept of images from the raw text. It is a promising way to solve the above problems as it can use easy-to-collect image-text pairs to construct the training dataset and the raw texts contain almost unlimited categories according to their semantics. However, learning from a large-scale unlabeled dataset also exposes the model to the risk of potential poisoning attacks, whereby the adversary aims to perturb the model's training dataset to trigger malicious behaviors in it. Previous work mainly focuses on the visual modality. In this paper, we instead focus on answering two questions: (1) Is the linguistic modality also vulnerable to poisoning attacks? and (2) Which modality is most vulnerable? To answer the two questions, we conduct three types of poisoning attacks against CLIP, the most representative multimodal contrastive learning framework. Extensive evaluations on different datasets and model architectures show that all three attacks can perform well on the linguistic modality with only a relatively low poisoning rate and limited epochs. Also, we observe that the poisoning effect differs between different modalities, i.e., with lower MinRank in the visual modality and with higher Hit@K when K is small in the linguistic modality. To mitigate the attacks, we propose both pre-training and post-training defenses. We empirically show that both defenses can significantly reduce the attack performance while preserving the model's utility.
Graph Unlearning
Mar 27, 2021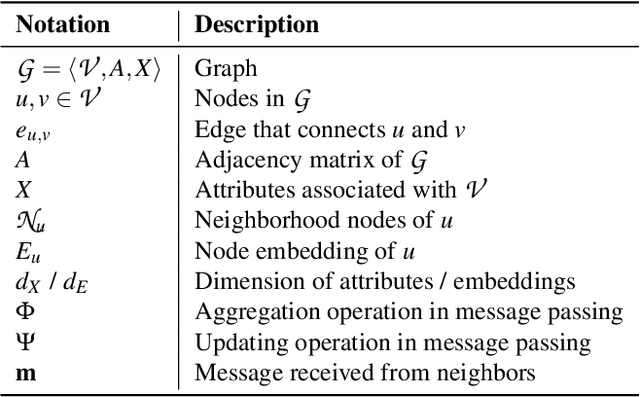


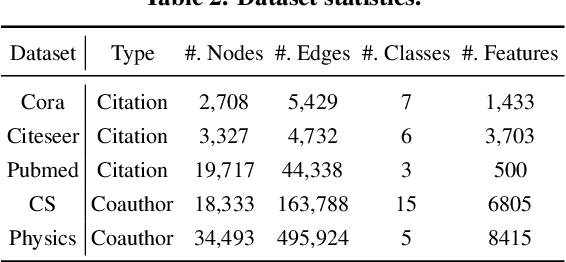
The right to be forgotten states that a data subject has the right to erase their data from an entity storing it. In the context of machine learning (ML), it requires the ML model provider to remove the data subject's data from the training set used to build the ML model, a process known as \textit{machine unlearning}. While straightforward and legitimate, retraining the ML model from scratch upon receiving unlearning requests incurs high computational overhead when the training set is large. To address this issue, a number of approximate algorithms have been proposed in the domain of image and text data, among which SISA is the state-of-the-art solution. It randomly partitions the training set into multiple shards and trains a constituent model for each shard. However, directly applying SISA to the graph data can severely damage the graph structural information, and thereby the resulting ML model utility. In this paper, we propose GraphEraser, a novel machine unlearning method tailored to graph data. Its contributions include two novel graph partition algorithms, and a learning-based aggregation method. We conduct extensive experiments on five real-world datasets to illustrate the unlearning efficiency and model utility of GraphEraser. We observe that GraphEraser achieves 2.06$\times$ (small dataset) to 35.94$\times$ (large dataset) unlearning time improvement compared to retraining from scratch. On the other hand, GraphEraser achieves up to $62.5\%$ higher F1 score than that of random partitioning. In addition, our proposed learning-based aggregation method achieves up to $112\%$ higher F1 score than that of the majority vote aggregation.
BAAAN: Backdoor Attacks Against Autoencoder and GAN-Based Machine Learning Models
Oct 08, 2020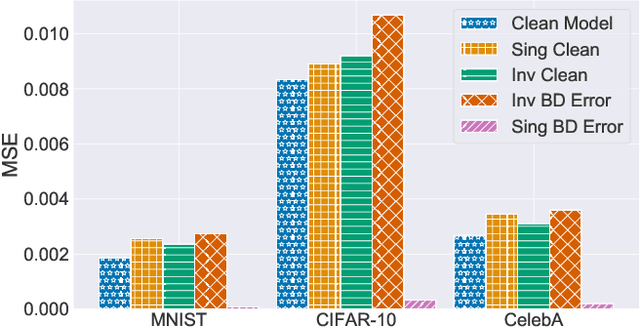

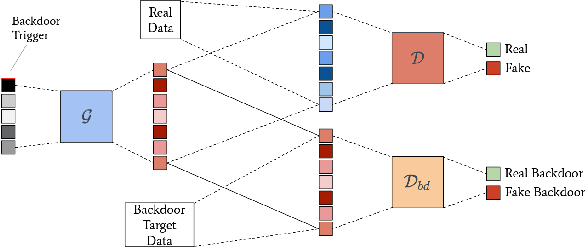
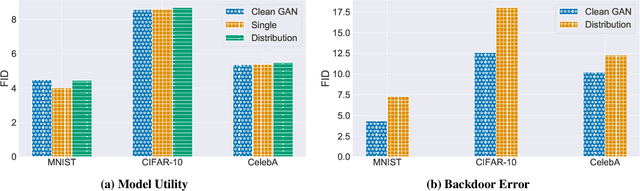
The tremendous progress of autoencoders and generative adversarial networks (GANs) has led to their application to multiple critical tasks, such as fraud detection and sanitized data generation. This increasing adoption has fostered the study of security and privacy risks stemming from these models. However, previous works have mainly focused on membership inference attacks. In this work, we explore one of the most severe attacks against machine learning models, namely the backdoor attack, against both autoencoders and GANs. The backdoor attack is a training time attack where the adversary implements a hidden backdoor in the target model that can only be activated by a secret trigger. State-of-the-art backdoor attacks focus on classification-based tasks. We extend the applicability of backdoor attacks to autoencoders and GAN-based models. More concretely, we propose the first backdoor attack against autoencoders and GANs where the adversary can control what the decoded or generated images are when the backdoor is activated. Our results show that the adversary can build a backdoored autoencoder that returns a target output for all backdoored inputs, while behaving perfectly normal on clean inputs. Similarly, for the GANs, our experiments show that the adversary can generate data from a different distribution when the backdoor is activated, while maintaining the same utility when the backdoor is not.
When Machine Unlearning Jeopardizes Privacy
May 05, 2020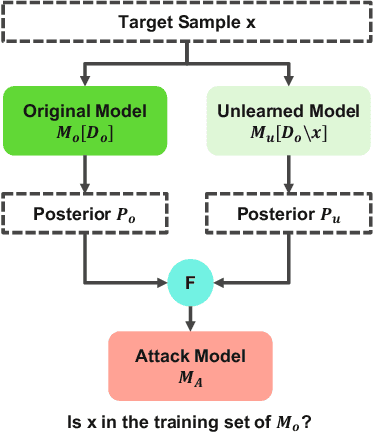
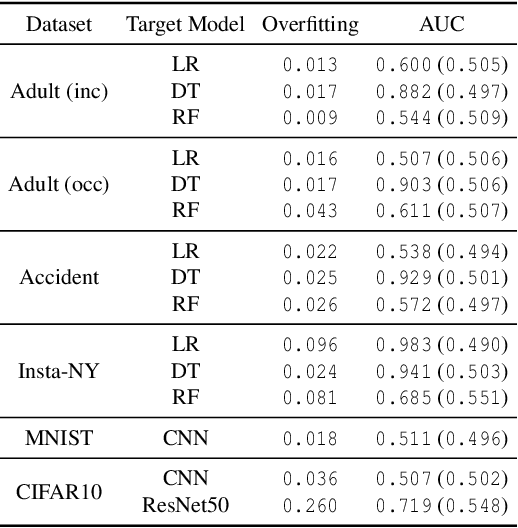
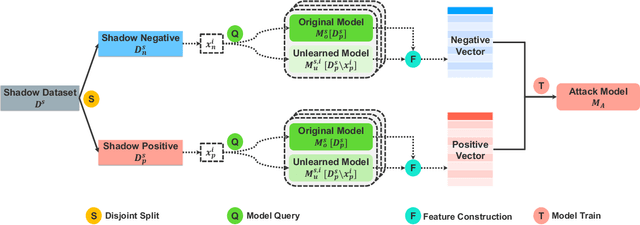

The right to be forgotten states that a data owner has the right to erase her data from an entity storing it. In the context of machine learning (ML), the right to be forgotten requires an ML model owner to remove the data owner's data from the training set used to build the ML model, a process known as machine unlearning. While originally designed to protect the privacy of the data owner, we argue that machine unlearning may leave some imprint of the data in the ML model and thus create unintended privacy risks. In this paper, we perform the first study on investigating the unintended information leakage caused by machine unlearning. We propose a novel membership inference attack which leverages the different outputs of an ML model's two versions to infer whether the deleted sample is part of the training set. Our experiments over five different datasets demonstrate that the proposed membership inference attack achieves strong performance. More importantly, we show that our attack in multiple cases outperforms the classical membership inference attack on the original ML model, which indicates that machine unlearning can have counterproductive effects on privacy. We notice that the privacy degradation is especially significant for well-generalized ML models where classical membership inference does not perform well. We further investigate two mechanisms to mitigate the newly discovered privacy risks and show that the only effective mechanism is to release the predicted label only. We believe that our results can help improve privacy in practical implementation of machine unlearning.
ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models
Jun 04, 2018
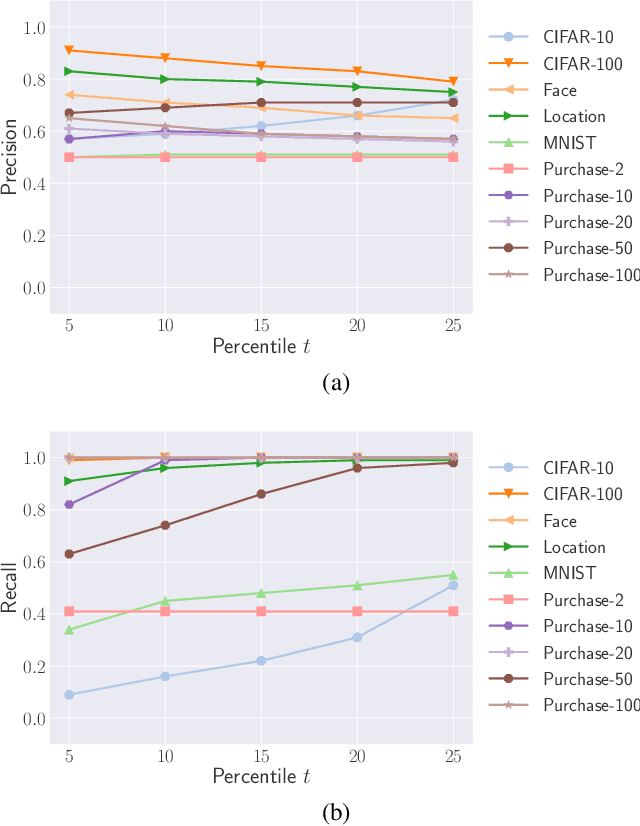
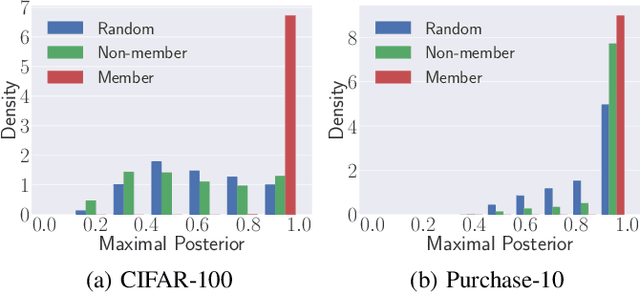

Machine learning (ML) has become a core component of many real-world applications and training data is a key factor that drives current progress. This huge success has led Internet companies to deploy machine learning as a service (MLaaS). Recently, the first membership inference attack has shown that extraction of information on the training set is possible in such MLaaS settings, which has severe security and privacy implications. However, the early demonstrations of the feasibility of such attacks have many assumptions on the adversary such as using multiple so-called shadow models, knowledge of the target model structure and having a dataset from the same distribution as the target model's training data. We relax all 3 key assumptions, thereby showing that such attacks are very broadly applicable at low cost and thereby pose a more severe risk than previously thought. We present the most comprehensive study so far on this emerging and developing threat using eight diverse datasets which show the viability of the proposed attacks across domains. In addition, we propose the first effective defense mechanisms against such broader class of membership inference attacks that maintain a high level of utility of the ML model.