 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAAAN: Backdoor Attacks Against Autoencoder and GAN-Based Machine Learning Models
Paper and Code
Oct 08, 2020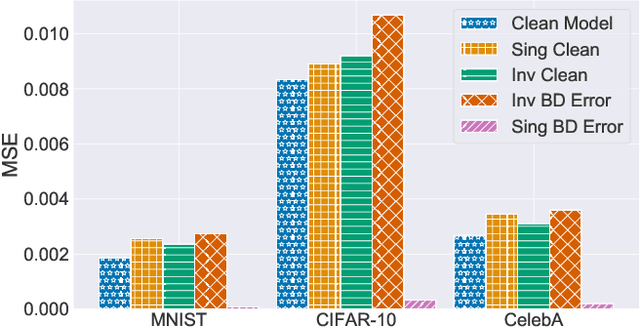

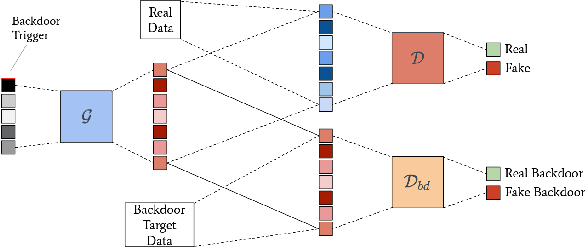
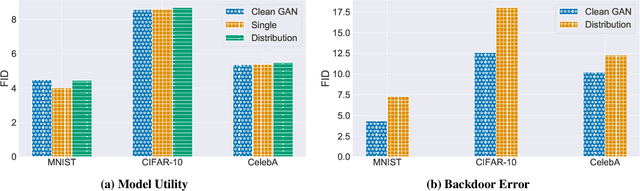
The tremendous progress of autoencoders and generative adversarial networks (GANs) has led to their application to multiple critical tasks, such as fraud detection and sanitized data generation. This increasing adoption has fostered the study of security and privacy risks stemming from these models. However, previous works have mainly focused on membership inference attacks. In this work, we explore one of the most severe attacks against machine learning models, namely the backdoor attack, against both autoencoders and GANs. The backdoor attack is a training time attack where the adversary implements a hidden backdoor in the target model that can only be activated by a secret trigger. State-of-the-art backdoor attacks focus on classification-based tasks. We extend the applicability of backdoor attacks to autoencoders and GAN-based models. More concretely, we propose the first backdoor attack against autoencoders and GANs where the adversary can control what the decoded or generated images are when the backdoor is activated. Our results show that the adversary can build a backdoored autoencoder that returns a target output for all backdoored inputs, while behaving perfectly normal on clean inputs. Similarly, for the GANs, our experiments show that the adversary can generate data from a different distribution when the backdoor is activated, while maintaining the same utility when the backdoor is not.