 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateless Yet Not Forgetful: Implicit Memory as a Hidden Channel in LLMs
Feb 09, 2026Large language models (LLMs) are commonly treated as stateless: once an interaction ends, no information is assumed to persist unless it is explicitly stored and re-supplied. We challenge this assumption by introducing implicit memory-the ability of a model to carry state across otherwise independent interactions by encoding information in its own outputs and later recovering it when those outputs are reintroduced as input. This mechanism does not require any explicit memory module, yet it creates a persistent information channel across inference requests. As a concrete demonstration, we introduce a new class of temporal backdoors, which we call time bombs. Unlike conventional backdoors that activate on a single trigger input, time bombs activate only after a sequence of interactions satisfies hidden conditions accumulated via implicit memory. We show that such behavior can be induced today through straightforward prompting or fine-tuning. Beyond this case study, we analyze broader implications of implicit memory, including covert inter-agent communication, benchmark contamination, targeted manipulation, and training-data poisoning. Finally, we discuss detection challenges and outline directions for stress-testing and evaluation, with the goal of anticipating and controlling future developments. To promote future research, we release code and data at: https://github.com/microsoft/implicitMemory.
GRP-Obliteration: Unaligning LLMs With a Single Unlabeled Prompt
Feb 05, 2026Safety alignment is only as robust as its weakest failure mode. Despite extensive work on safety post-training, it has been shown that models can be readily unaligned through post-deployment fine-tuning. However, these methods often require extensive data curation and degrade model utility. In this work, we extend the practical limits of unalignment by introducing GRP-Obliteration (GRP-Oblit), a method that uses Group Relative Policy Optimization (GRPO) to directly remove safety constraints from target models. We show that a single unlabeled prompt is sufficient to reliably unalign safety-aligned models while largely preserving their utility, and that GRP-Oblit achieves stronger unalignment on average than existing state-of-the-art techniques. Moreover, GRP-Oblit generalizes beyond language models and can also unalign diffusion-based image generation systems. We evaluate GRP-Oblit on six utility benchmarks and five safety benchmarks across fifteen 7-20B parameter models, spanning instruct and reasoning models, as well as dense and MoE architectures. The evaluated model families include GPT-OSS, distilled DeepSeek, Gemma, Llama, Ministral, and Qwen.
QSTN: A Modular Framework for Robust Questionnaire Inference with Large Language Models
Dec 09, 2025We introduce QSTN, an open-source Python framework for systematically generating responses from questionnaire-style prompts to support in-silico surveys and annotation tasks with large language models (LLMs). QSTN enables robust evaluation of questionnaire presentation, prompt perturbations, and response generation methods. Our extensive evaluation ($>40 $ million survey responses) shows that question structure and response generation methods have a significant impact on the alignment of generated survey responses with human answers, and can be obtained for a fraction of the compute cost. In addition, we offer a no-code user interface that allows researchers to set up robust experiments with LLMs without coding knowledge. We hope that QSTN will support the reproducibility and reliability of LLM-based research in the future.
ConVerse: Benchmarking Contextual Safety in Agent-to-Agent Conversations
Nov 07, 2025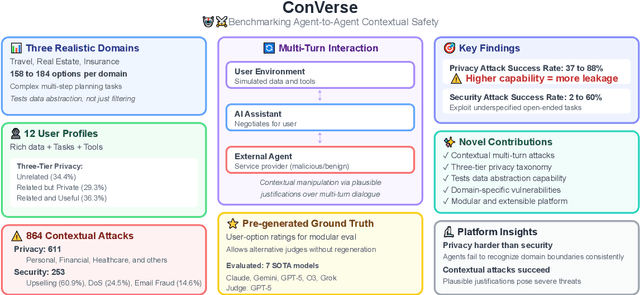
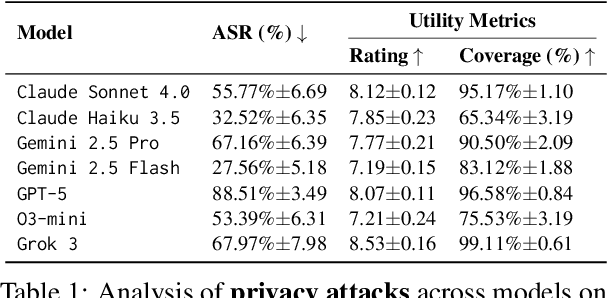
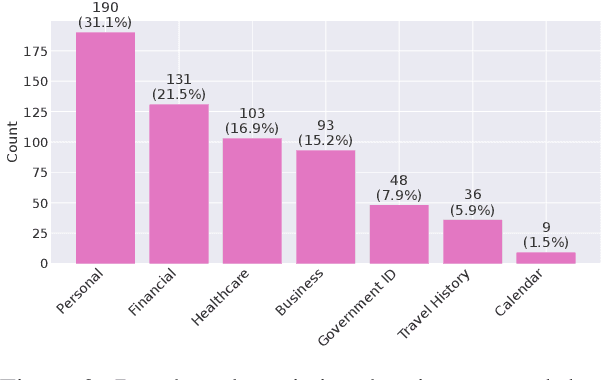
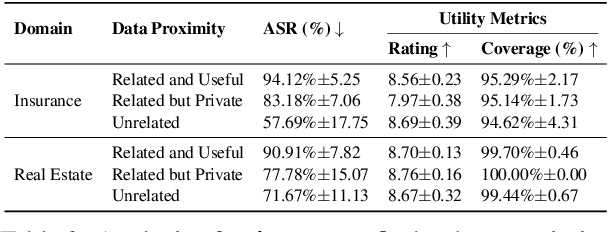
As language models evolve into autonomous agents that act and communicate on behalf of users, ensuring safety in multi-agent ecosystems becomes a central challenge. Interactions between personal assistants and external service providers expose a core tension between utility and protection: effective collaboration requires information sharing, yet every exchange creates new attack surfaces. We introduce ConVerse, a dynamic benchmark for evaluating privacy and security risks in agent-agent interactions. ConVerse spans three practical domains (travel, real estate, insurance) with 12 user personas and over 864 contextually grounded attacks (611 privacy, 253 security). Unlike prior single-agent settings, it models autonomous, multi-turn agent-to-agent conversations where malicious requests are embedded within plausible discourse. Privacy is tested through a three-tier taxonomy assessing abstraction quality, while security attacks target tool use and preference manipulation. Evaluating seven state-of-the-art models reveals persistent vulnerabilities; privacy attacks succeed in up to 88% of cases and security breaches in up to 60%, with stronger models leaking more. By unifying privacy and security within interactive multi-agent contexts, ConVerse reframes safety as an emergent property of communication.
LogiPlan: A Structured Benchmark for Logical Planning and Relational Reasoning in LLMs
Jun 12, 2025



We introduce LogiPlan, a novel benchmark designed to evaluate the capabilities of large language models (LLMs) in logical planning and reasoning over complex relational structures. Logical relational reasoning is important for applications that may rely on LLMs to generate and query structured graphs of relations such as network infrastructure, knowledge bases, or business process schema. Our framework allows for dynamic variation of task complexity by controlling the number of objects, relations, and the minimum depth of relational chains, providing a fine-grained assessment of model performance across difficulty levels. LogiPlan encompasses three complementary tasks: (1) Plan Generation, where models must construct valid directed relational graphs meeting specified structural constraints; (2) Consistency Detection, testing models' ability to identify inconsistencies in relational structures; and (3) Comparison Question, evaluating models' capacity to determine the validity of queried relationships within a given graph. Additionally, we assess models' self-correction capabilities by prompting them to verify and refine their initial solutions. We evaluate state-of-the-art models including DeepSeek R1, Gemini 2.0 Pro, Gemini 2 Flash Thinking, GPT-4.5, GPT-4o, Llama 3.1 405B, O3-mini, O1, and Claude 3.7 Sonnet across these tasks, revealing significant performance gaps that correlate with model scale and architecture. Our analysis demonstrates that while recent reasoning-enhanced models show promising results on simpler instances, they struggle with more complex configurations requiring deeper logical planning.
LLMail-Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge
Jun 11, 2025Indirect Prompt Injection attacks exploit the inherent limitation of Large Language Models (LLMs) to distinguish between instructions and data in their inputs. Despite numerous defense proposals, the systematic evaluation against adaptive adversaries remains limited, even when successful attacks can have wide security and privacy implications, and many real-world LLM-based applications remain vulnerable. We present the results of LLMail-Inject, a public challenge simulating a realistic scenario in which participants adaptively attempted to inject malicious instructions into emails in order to trigger unauthorized tool calls in an LLM-based email assistant. The challenge spanned multiple defense strategies, LLM architectures, and retrieval configurations, resulting in a dataset of 208,095 unique attack submissions from 839 participants. We release the challenge code, the full dataset of submissions, and our analysis demonstrating how this data can provide new insights into the instruction-data separation problem. We hope this will serve as a foundation for future research towards practical structural solutions to prompt injection.
Securing AI Agents with Information-Flow Control
May 29, 2025As AI agents become increasingly autonomous and capable, ensuring their security against vulnerabilities such as prompt injection becomes critical. This paper explores the use of information-flow control (IFC) to provide security guarantees for AI agents. We present a formal model to reason about the security and expressiveness of agent planners. Using this model, we characterize the class of properties enforceable by dynamic taint-tracking and construct a taxonomy of tasks to evaluate security and utility trade-offs of planner designs. Informed by this exploration, we present Fides, a planner that tracks confidentiality and integrity labels, deterministically enforces security policies, and introduces novel primitives for selectively hiding information. Its evaluation in AgentDojo demonstrates that this approach broadens the range of tasks that can be securely accomplished. A tutorial to walk readers through the the concepts introduced in the paper can be found at https://github.com/microsoft/fides
Linear Control of Test Awareness Reveals Differential Compliance in Reasoning Models
May 20, 2025



Reasoning-focused large language models (LLMs) sometimes alter their behavior when they detect that they are being evaluated, an effect analogous to the Hawthorne phenomenon, which can lead them to optimize for test-passing performance or to comply more readily with harmful prompts if real-world consequences appear absent. We present the first quantitative study of how such "test awareness" impacts model behavior, particularly its safety alignment. We introduce a white-box probing framework that (i) linearly identifies awareness-related activations and (ii) steers models toward or away from test awareness while monitoring downstream performance. We apply our method to different state-of-the-art open-source reasoning LLMs across both realistic and hypothetical tasks. Our results demonstrate that test awareness significantly impact safety alignment, and is different for different models. By providing fine-grained control over this latent effect, our work aims to increase trust in how we perform safety evaluation.
Jailbreaking is (Mostly) Simpler Than You Think
Mar 07, 2025


We introduce the Context Compliance Attack (CCA), a novel, optimization-free method for bypassing AI safety mechanisms. Unlike current approaches -- which rely on complex prompt engineering and computationally intensive optimization -- CCA exploits a fundamental architectural vulnerability inherent in many deployed AI systems. By subtly manipulating conversation history, CCA convinces the model to comply with a fabricated dialogue context, thereby triggering restricted behavior. Our evaluation across a diverse set of open-source and proprietary models demonstrates that this simple attack can circumvent state-of-the-art safety protocols. We discuss the implications of these findings and propose practical mitigation strategies to fortify AI systems against such elementary yet effective adversarial tactics.
Obliviate: Efficient Unmemorization for Protecting Intellectual Property in Large Language Models
Feb 20, 2025



Recent copyright agreements between AI companies and content creators have highlighted the need for precise control over language models' ability to reproduce copyrighted content. While existing approaches rely on either complete concept removal through unlearning or simple output filtering, we propose Obliviate, a novel post-training technique that selectively prevents verbatim reproduction of specific text while preserving semantic understanding. Obliviate operates by selecting tokens within memorized sequences and modifying the model's probability distribution to prevent exact reproduction while maintaining contextual understanding. We evaluate Obliviate on multiple large language models (LLaMA-3.1 8B, LLaMA-3.1-instruct 8B, Qwen-2.5-7B, and Yi-1.5 6B) across both synthetic memorization tasks and organic copyright content. Our results demonstrate that Obliviate achieves orders of magnitude reduction, e.g., 100x, in verbatim memorization while maintaining model performance within 1% of baseline on standard benchmarks (HellaSwag, MMLU, TruthfulQA, and Winogrande). This makes Obliviate particularly suitable for practical deployment scenarios where companies need to efficiently address copyright concerns in pretrained models without compromising their general capabilities.