 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPCEval: A Benchmark for Multi-Party Conversation Generation
Mar 05, 2026Multi-party conversation generation, such as smart reply and collaborative assistants, is an increasingly important capability of generative AI, yet its evaluation remains a critical bottleneck. Compared to two-party dialogue, multi-party settings introduce distinct challenges, including complex turn-taking, role-dependent speaker behavior, long-range conversational structure, and multiple equally valid continuations. Accordingly, we introduce MPCEval, a task-aware evaluation and benchmarking suite for multi-party conversation generation. MPCEval decomposes generation quality into speaker modeling, content quality, and speaker--content consistency, and explicitly distinguishes local next-turn prediction from global full-conversation generation. It provides novel, quantitative, reference-free, and reproducible metrics that scale across datasets and models. We apply MPCEval to diverse public and real-world datasets and evaluate modern generation methods alongside human-authored conversations. The results reveal systematic, dimension-specific model characteristics in participation balance, content progression and novelty, and speaker--content consistency, demonstrating that evaluation objectives critically shape model assessment and that single-score evaluation obscures fundamental differences in multi-party conversational behavior. The implementation of MPCEval and the associated evaluation code are publicly available at https://github.com/Owen-Yang-18/MPCEval.
On Membership Inference Attacks in Knowledge Distillation
May 17, 2025Nowadays, Large Language Models (LLMs) are trained on huge datasets, some including sensitive information. This poses a serious privacy concern because privacy attacks such as Membership Inference Attacks (MIAs) may detect this sensitive information. While knowledge distillation compresses LLMs into efficient, smaller student models, its impact on privacy remains underexplored. In this paper, we investigate how knowledge distillation affects model robustness against MIA. We focus on two questions. First, how is private data protected in teacher and student models? Second, how can we strengthen privacy preservation against MIAs in knowledge distillation? Through comprehensive experiments, we show that while teacher and student models achieve similar overall MIA accuracy, teacher models better protect member data, the primary target of MIA, whereas student models better protect non-member data. To address this vulnerability in student models, we propose 5 privacy-preserving distillation methods and demonstrate that they successfully reduce student models' vulnerability to MIA, with ensembling further stabilizing the robustness, offering a reliable approach for distilling more secure and efficient student models. Our implementation source code is available at https://github.com/richardcui18/MIA_in_KD.
DivTrackee versus DynTracker: Promoting Diversity in Anti-Facial Recognition against Dynamic FR Strategy
Jan 11, 2025



The widespread adoption of facial recognition (FR) models raises serious concerns about their potential misuse, motivating the development of anti-facial recognition (AFR) to protect user facial privacy. In this paper, we argue that the static FR strategy, predominantly adopted in prior literature for evaluating AFR efficacy, cannot faithfully characterize the actual capabilities of determined trackers who aim to track a specific target identity. In particular, we introduce \emph{\ourAttack}, a dynamic FR strategy where the model's gallery database is iteratively updated with newly recognized target identity images. Surprisingly, such a simple approach renders all the existing AFR protections ineffective. To mitigate the privacy threats posed by DynTracker, we advocate for explicitly promoting diversity in the AFR-protected images. We hypothesize that the lack of diversity is the primary cause of the failure of existing AFR methods. Specifically, we develop \emph{DivTrackee}, a novel method for crafting diverse AFR protections that builds upon a text-guided image generation framework and diversity-promoting adversarial losses. Through comprehensive experiments on various facial image benchmarks and feature extractors, we demonstrate DynTracker's strength in breaking existing AFR methods and the superiority of DivTrackee in preventing user facial images from being identified by dynamic FR strategies. We believe our work can act as an important initial step towards developing more effective AFR methods for protecting user facial privacy against determined trackers.
Vera Verto: Multimodal Hijacking Attack
Jul 31, 2024The increasing cost of training machine learning (ML) models has led to the inclusion of new parties to the training pipeline, such as users who contribute training data and companies that provide computing resources. This involvement of such new parties in the ML training process has introduced new attack surfaces for an adversary to exploit. A recent attack in this domain is the model hijacking attack, whereby an adversary hijacks a victim model to implement their own -- possibly malicious -- hijacking tasks. However, the scope of the model hijacking attack is so far limited to the homogeneous-modality tasks. In this paper, we transform the model hijacking attack into a more general multimodal setting, where the hijacking and original tasks are performed on data of different modalities. Specifically, we focus on the setting where an adversary implements a natural language processing (NLP) hijacking task into an image classification model. To mount the attack, we propose a novel encoder-decoder based framework, namely the Blender, which relies on advanced image and language models. Experimental results show that our modal hijacking attack achieves strong performances in different settings. For instance, our attack achieves 94%, 94%, and 95% attack success rate when using the Sogou news dataset to hijack STL10, CIFAR-10, and MNIST classifiers.
ReCaLL: Membership Inference via Relative Conditional Log-Likelihoods
Jun 23, 2024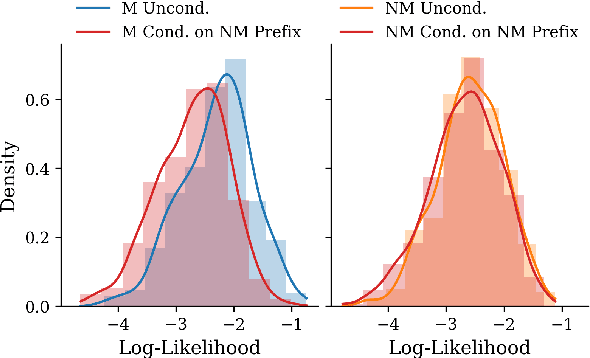
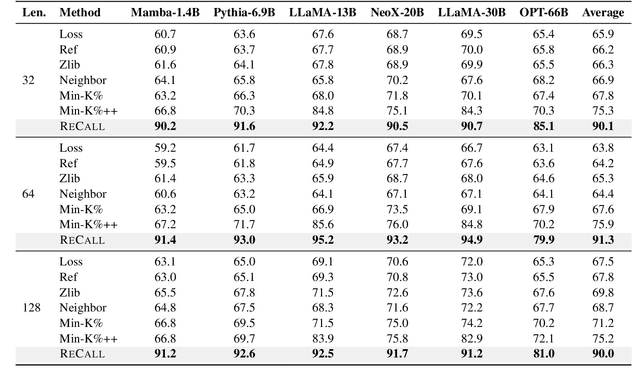
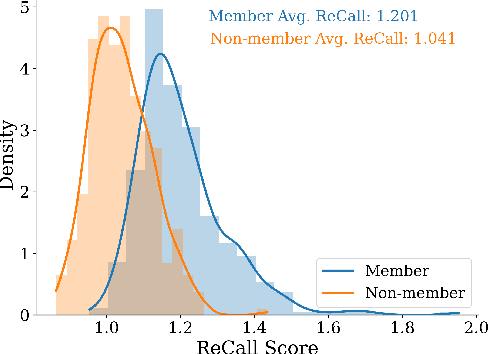
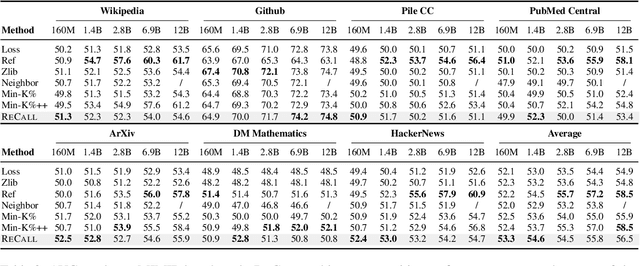
The rapid scaling of large language models (LLMs) has raised concerns about the transparency and fair use of the pretraining data used for training them. Detecting such content is challenging due to the scale of the data and limited exposure of each instance during training. We propose ReCaLL (Relative Conditional Log-Likelihood), a novel membership inference attack (MIA) to detect LLMs' pretraining data by leveraging their conditional language modeling capabilities. ReCaLL examines the relative change in conditional log-likelihoods when prefixing target data points with non-member context. Our empirical findings show that conditioning member data on non-member prefixes induces a larger decrease in log-likelihood compared to non-member data. We conduct comprehensive experiments and show that ReCaLL achieves state-of-the-art performance on the WikiMIA dataset, even with random and synthetic prefixes, and can be further improved using an ensemble approach. Moreover, we conduct an in-depth analysis of LLMs' behavior with different membership contexts, providing insights into how LLMs leverage membership information for effective inference at both the sequence and token level.
Generated Distributions Are All You Need for Membership Inference Attacks Against Generative Models
Oct 30, 2023Generative models have demonstrated revolutionary success in various visual creation tasks, but in the meantime, they have been exposed to the threat of leaking private information of their training data. Several membership inference attacks (MIAs) have been proposed to exhibit the privacy vulnerability of generative models by classifying a query image as a training dataset member or nonmember. However, these attacks suffer from major limitations, such as requiring shadow models and white-box access, and either ignoring or only focusing on the unique property of diffusion models, which block their generalization to multiple generative models. In contrast, we propose the first generalized membership inference attack against a variety of generative models such as generative adversarial networks, [variational] autoencoders, implicit functions, and the emerging diffusion models. We leverage only generated distributions from target generators and auxiliary non-member datasets, therefore regarding target generators as black boxes and agnostic to their architectures or application scenarios. Experiments validate that all the generative models are vulnerable to our attack. For instance, our work achieves attack AUC $>0.99$ against DDPM, DDIM, and FastDPM trained on CIFAR-10 and CelebA. And the attack against VQGAN, LDM (for the text-conditional generation), and LIIF achieves AUC $>0.90.$ As a result, we appeal to our community to be aware of such privacy leakage risks when designing and publishing generative models.
Generating Less Certain Adversarial Examples Improves Robust Generalization
Oct 06, 2023Recent studies have shown that deep neural networks are vulnerable to adversarial examples. Numerous defenses have been proposed to improve model robustness, among which adversarial training is most successful. In this work, we revisit the robust overfitting phenomenon. In particular, we argue that overconfident models produced during adversarial training could be a potential cause, supported by the empirical observation that the predicted labels of adversarial examples generated by models with better robust generalization ability tend to have significantly more even distributions. Based on the proposed definition of adversarial certainty, we incorporate an extragradient step in the adversarial training framework to search for models that can generate adversarially perturbed inputs with lower certainty, further improving robust generalization. Our approach is general and can be easily combined with other variants of adversarial training methods. Extensive experiments on image benchmarks demonstrate that our method effectively alleviates robust overfitting and is able to produce models with consistently improved robustness.
Graph Neural Network for spatiotemporal data: methods and applications
May 30, 2023In the era of big data, there has been a surge in the availability of data containing rich spatial and temporal information, offering valuable insights into dynamic systems and processes for applications such as weather forecasting, natural disaster management, intelligent transport systems, and precision agriculture. Graph neural networks (GNNs) have emerged as a powerful tool for modeling and understanding data with dependencies to each other such as spatial and temporal dependencies. There is a large amount of existing work that focuses on addressing the complex spatial and temporal dependencies in spatiotemporal data using GNNs. However, the strong interdisciplinary nature of spatiotemporal data has created numerous GNNs variants specifically designed for distinct application domains. Although the techniques are generally applicable across various domains, cross-referencing these methods remains essential yet challenging due to the absence of a comprehensive literature review on GNNs for spatiotemporal data. This article aims to provide a systematic and comprehensive overview of the technologies and applications of GNNs in the spatiotemporal domain. First, the ways of constructing graphs from spatiotemporal data are summarized to help domain experts understand how to generate graphs from various types of spatiotemporal data. Then, a systematic categorization and summary of existing spatiotemporal GNNs are presented to enable domain experts to identify suitable techniques and to support model developers in advancing their research. Moreover, a comprehensive overview of significant applications in the spatiotemporal domain is offered to introduce a broader range of applications to model developers and domain experts, assisting them in exploring potential research topics and enhancing the impact of their work. Finally, open challenges and future directions are discussed.
Membership Inference Attacks Against Recommender Systems
Sep 16, 2021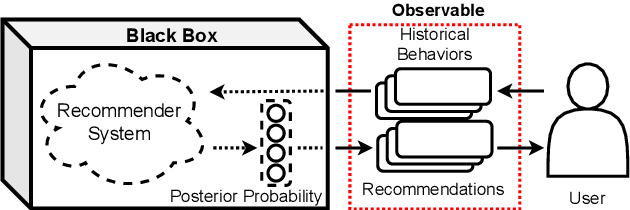
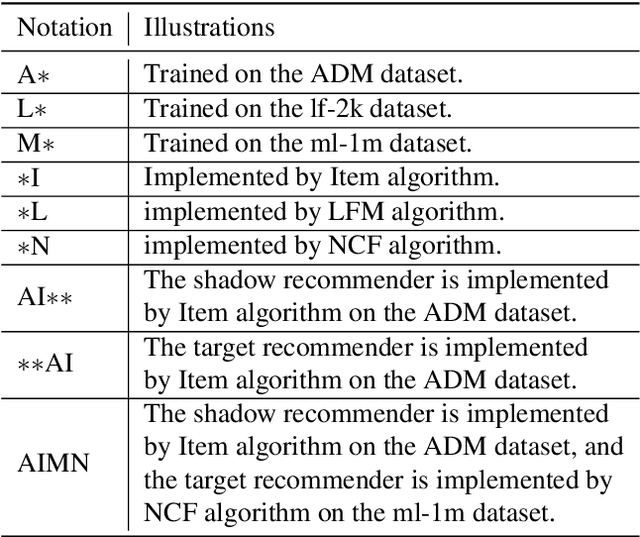


Recently, recommender systems have achieved promising performances and become one of the most widely used web applications. However, recommender systems are often trained on highly sensitive user data, thus potential data leakage from recommender systems may lead to severe privacy problems. In this paper, we make the first attempt on quantifying the privacy leakage of recommender systems through the lens of membership inference. In contrast with traditional membership inference against machine learning classifiers, our attack faces two main differences. First, our attack is on the user-level but not on the data sample-level. Second, the adversary can only observe the ordered recommended items from a recommender system instead of prediction results in the form of posterior probabilities. To address the above challenges, we propose a novel method by representing users from relevant items. Moreover, a shadow recommender is established to derive the labeled training data for training the attack model. Extensive experimental results show that our attack framework achieves a strong performance. In addition, we design a defense mechanism to effectively mitigate the membership inference threat of recommender systems.