 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCaLL: Membership Inference via Relative Conditional Log-Likelihoods
Jun 23, 2024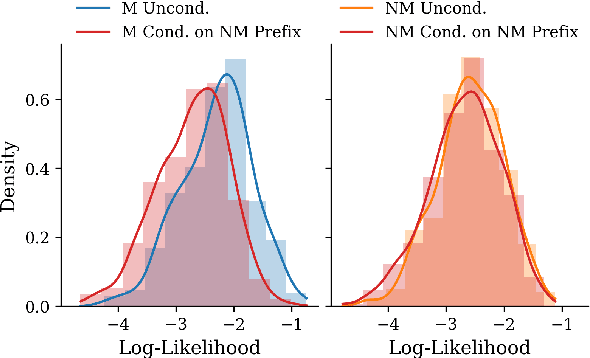
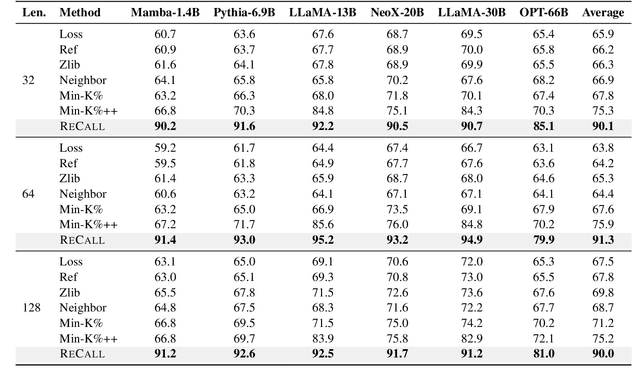
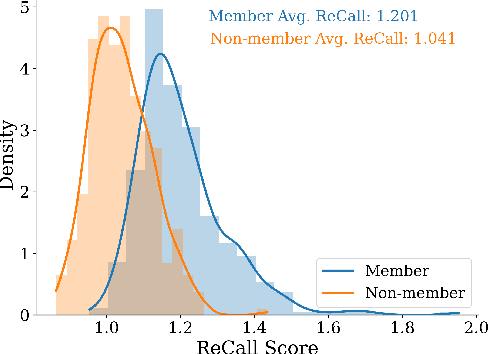
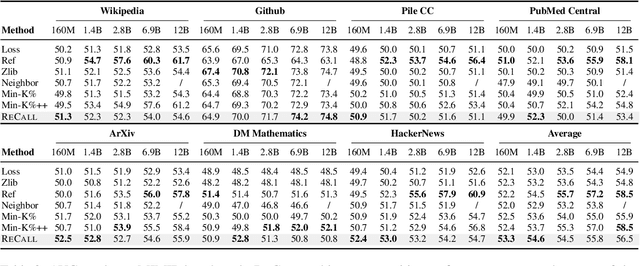
The rapid scaling of large language models (LLMs) has raised concerns about the transparency and fair use of the pretraining data used for training them. Detecting such content is challenging due to the scale of the data and limited exposure of each instance during training. We propose ReCaLL (Relative Conditional Log-Likelihood), a novel membership inference attack (MIA) to detect LLMs' pretraining data by leveraging their conditional language modeling capabilities. ReCaLL examines the relative change in conditional log-likelihoods when prefixing target data points with non-member context. Our empirical findings show that conditioning member data on non-member prefixes induces a larger decrease in log-likelihood compared to non-member data. We conduct comprehensive experiments and show that ReCaLL achieves state-of-the-art performance on the WikiMIA dataset, even with random and synthetic prefixes, and can be further improved using an ensemble approach. Moreover, we conduct an in-depth analysis of LLMs' behavior with different membership contexts, providing insights into how LLMs leverage membership information for effective inference at both the sequence and token level.
Reassessing How to Compare and Improve the Calibration of Machine Learning Models
Jun 06, 2024
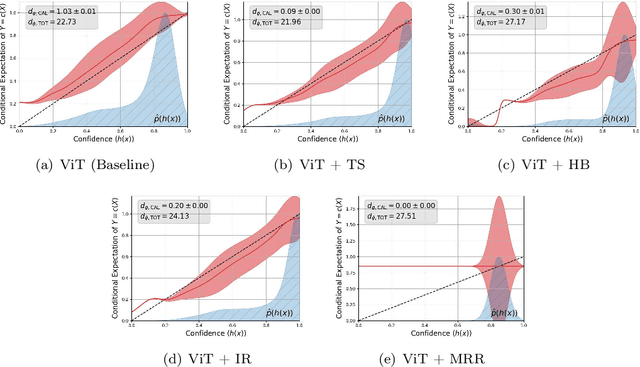
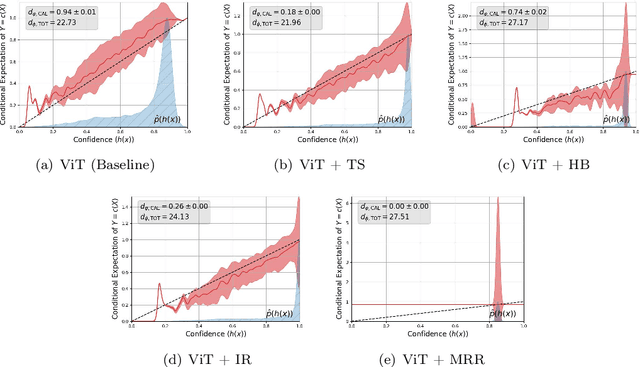
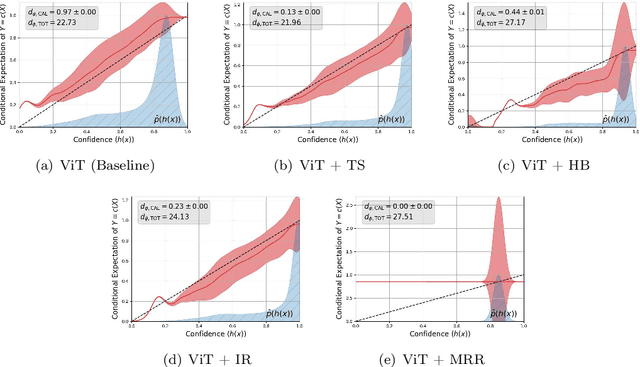
A machine learning model is calibrated if its predicted probability for an outcome matches the observed frequency for that outcome conditional on the model prediction. This property has become increasingly important as the impact of machine learning models has continued to spread to various domains. As a result, there are now a dizzying number of recent papers on measuring and improving the calibration of (specifically deep learning) models. In this work, we reassess the reporting of calibration metrics in the recent literature. We show that there exist trivial recalibration approaches that can appear seemingly state-of-the-art unless calibration and prediction metrics (i.e. test accuracy) are accompanied by additional generalization metrics such as negative log-likelihood. We then derive a calibration-based decomposition of Bregman divergences that can be used to both motivate a choice of calibration metric based on a generalization metric, and to detect trivial calibration. Finally, we apply these ideas to develop a new extension to reliability diagrams that can be used to jointly visualize calibration as well as the estimated generalization error of a model.
How Does Gradient Descent Learn Features -- A Local Analysis for Regularized Two-Layer Neural Networks
Jun 03, 2024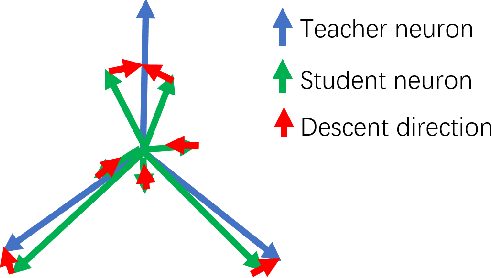
The ability of learning useful features is one of the major advantages of neural networks. Although recent works show that neural network can operate in a neural tangent kernel (NTK) regime that does not allow feature learning, many works also demonstrate the potential for neural networks to go beyond NTK regime and perform feature learning. Recently, a line of work highlighted the feature learning capabilities of the early stages of gradient-based training. In this paper we consider another mechanism for feature learning via gradient descent through a local convergence analysis. We show that once the loss is below a certain threshold, gradient descent with a carefully regularized objective will capture ground-truth directions. Our results demonstrate that feature learning not only happens at the initial gradient steps, but can also occur towards the end of training.
Robust Second-Order Nonconvex Optimization and Its Application to Low Rank Matrix Sensing
Mar 12, 2024Finding an approximate second-order stationary point (SOSP) is a well-studied and fundamental problem in stochastic nonconvex optimization with many applications in machine learning. However, this problem is poorly understood in the presence of outliers, limiting the use of existing nonconvex algorithms in adversarial settings. In this paper, we study the problem of finding SOSPs in the strong contamination model, where a constant fraction of datapoints are arbitrarily corrupted. We introduce a general framework for efficiently finding an approximate SOSP with \emph{dimension-independent} accuracy guarantees, using $\widetilde{O}({D^2}/{\epsilon})$ samples where $D$ is the ambient dimension and $\epsilon$ is the fraction of corrupted datapoints. As a concrete application of our framework, we apply it to the problem of low rank matrix sensing, developing efficient and provably robust algorithms that can tolerate corruptions in both the sensing matrices and the measurements. In addition, we establish a Statistical Query lower bound providing evidence that the quadratic dependence on $D$ in the sample complexity is necessary for computationally efficient algorithms.
Linear Transformers are Versatile In-Context Learners
Feb 21, 2024


Recent research has demonstrated that transformers, particularly linear attention models, implicitly execute gradient-descent-like algorithms on data provided in-context during their forward inference step. However, their capability in handling more complex problems remains unexplored. In this paper, we prove that any linear transformer maintains an implicit linear model and can be interpreted as performing a variant of preconditioned gradient descent. We also investigate the use of linear transformers in a challenging scenario where the training data is corrupted with different levels of noise. Remarkably, we demonstrate that for this problem linear transformers discover an intricate and highly effective optimization algorithm, surpassing or matching in performance many reasonable baselines. We reverse-engineer this algorithm and show that it is a novel approach incorporating momentum and adaptive rescaling based on noise levels. Our findings show that even linear transformers possess the surprising ability to discover sophisticated optimization strategies.
Mean-Field Analysis for Learning Subspace-Sparse Polynomials with Gaussian Input
Feb 14, 2024In this work, we study the mean-field flow for learning subspace-sparse polynomials using stochastic gradient descent and two-layer neural networks, where the input distribution is standard Gaussian and the output only depends on the projection of the input onto a low-dimensional subspace. We propose a basis-free generalization of the merged-staircase property in Abbe et al. (2022) and establish a necessary condition for the SGD-learnability. In addition, we prove that the condition is almost sufficient, in the sense that a condition slightly stronger than the necessary condition can guarantee the exponential decay of the loss functional to zero.
For Better or For Worse? Learning Minimum Variance Features With Label Augmentation
Feb 10, 2024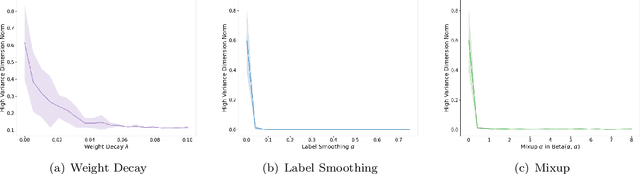
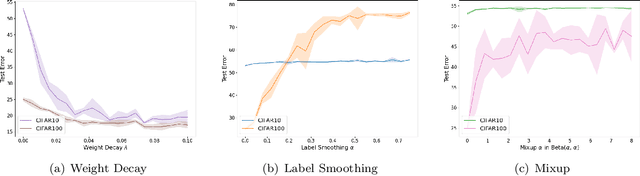
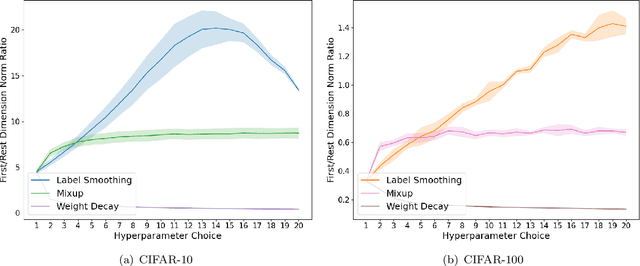
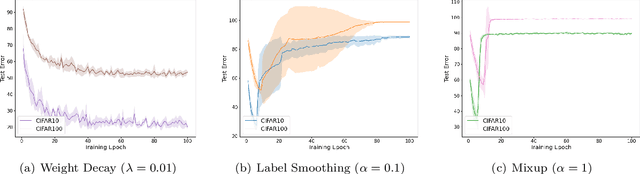
Data augmentation has been pivotal in successfully training deep learning models on classification tasks over the past decade. An important subclass of data augmentation techniques - which includes both label smoothing and Mixup - involves modifying not only the input data but also the input label during model training. In this work, we analyze the role played by the label augmentation aspect of such methods. We prove that linear models on linearly separable data trained with label augmentation learn only the minimum variance features in the data, while standard training (which includes weight decay) can learn higher variance features. An important consequence of our results is negative: label smoothing and Mixup can be less robust to adversarial perturbations of the training data when compared to standard training. We verify that our theory reflects practice via a range of experiments on synthetic data and image classification benchmarks.
Transfer-Learning-Based Autotuning Using Gaussian Copula
Jan 09, 2024
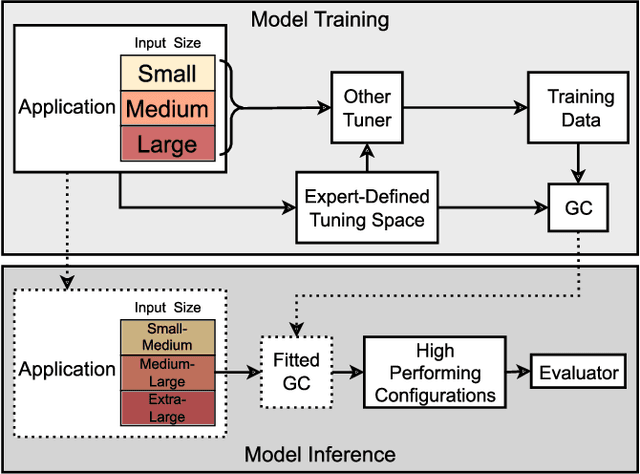


As diverse high-performance computing (HPC) systems are built, many opportunities arise for applications to solve larger problems than ever before. Given the significantly increased complexity of these HPC systems and application tuning, empirical performance tuning, such as autotuning, has emerged as a promising approach in recent years. Despite its effectiveness, autotuning is often a computationally expensive approach. Transfer learning (TL)-based autotuning seeks to address this issue by leveraging the data from prior tuning. Current TL methods for autotuning spend significant time modeling the relationship between parameter configurations and performance, which is ineffective for few-shot (that is, few empirical evaluations) tuning on new tasks. We introduce the first generative TL-based autotuning approach based on the Gaussian copula (GC) to model the high-performing regions of the search space from prior data and then generate high-performing configurations for new tasks. This allows a sampling-based approach that maximizes few-shot performance and provides the first probabilistic estimation of the few-shot budget for effective TL-based autotuning. We compare our generative TL approach with state-of-the-art autotuning techniques on several benchmarks. We find that the GC is capable of achieving 64.37% of peak few-shot performance in its first evaluation. Furthermore, the GC model can determine a few-shot transfer budget that yields up to 33.39$\times$ speedup, a dramatic improvement over the 20.58$\times$ speedup using prior techniques.
* 13 pages, 5 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2023, available at https://dl.acm.org/doi/10.1145/3577193.3593712
FULL-W2V: Fully Exploiting Data Reuse for W2V on GPU-Accelerated Systems
Dec 12, 2023



Word2Vec remains one of the highly-impactful innovations in the field of Natural Language Processing (NLP) that represents latent grammatical and syntactical information in human text with dense vectors in a low dimension. Word2Vec has high computational cost due to the algorithm's inherent sequentiality, intensive memory accesses, and the large vocabularies it represents. While prior studies have investigated technologies to explore parallelism and improve memory system performance, they struggle to effectively gain throughput on powerful GPUs. We identify memory data access and latency as the primary bottleneck in prior works on GPUs, which prevents highly optimized kernels from attaining the architecture's peak performance. We present a novel algorithm, FULL-W2V, which maximally exploits the opportunities for data reuse in the W2V algorithm and leverages GPU architecture and resources to reduce access to low memory levels and improve temporal locality. FULL-W2V is capable of reducing accesses to GPU global memory significantly, e.g., by more than 89\%, compared to prior state-of-the-art GPU implementations, resulting in significant performance improvement that scales across successive hardware generations. Our prototype implementation achieves 2.97X speedup when ported from Nvidia Pascal P100 to Volta V100 cards, and outperforms the state-of-the-art by 5.72X on V100 cards with the same embedding quality. In-depth analysis indicates that the reduction of memory accesses through register and shared memory caching and high-throughput shared memory reduction leads to a significantly improved arithmetic intensity. FULL-W2V can potentially benefit many applications in NLP and other domains.
* 12 pages, 7 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2021, available at https://doi.org/10.1145/3447818.3460373
The Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Oct 04, 2023
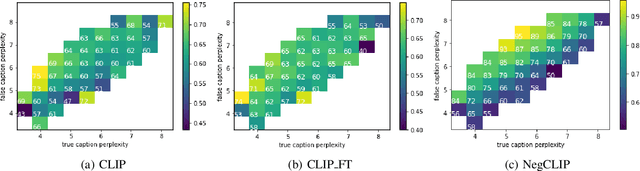


Compositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.