 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer-Learning-Based Autotuning Using Gaussian Copula
Jan 09, 2024
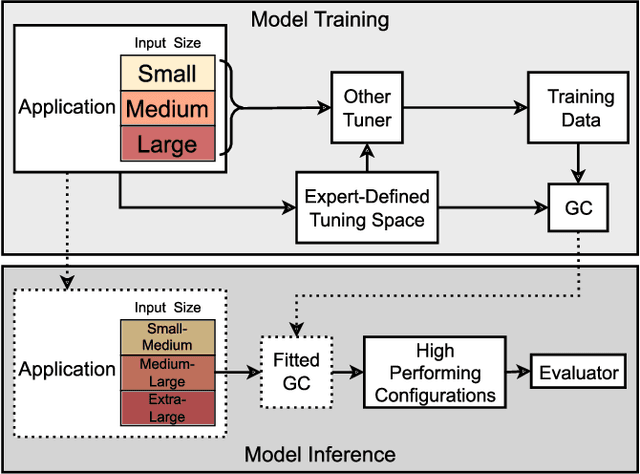


As diverse high-performance computing (HPC) systems are built, many opportunities arise for applications to solve larger problems than ever before. Given the significantly increased complexity of these HPC systems and application tuning, empirical performance tuning, such as autotuning, has emerged as a promising approach in recent years. Despite its effectiveness, autotuning is often a computationally expensive approach. Transfer learning (TL)-based autotuning seeks to address this issue by leveraging the data from prior tuning. Current TL methods for autotuning spend significant time modeling the relationship between parameter configurations and performance, which is ineffective for few-shot (that is, few empirical evaluations) tuning on new tasks. We introduce the first generative TL-based autotuning approach based on the Gaussian copula (GC) to model the high-performing regions of the search space from prior data and then generate high-performing configurations for new tasks. This allows a sampling-based approach that maximizes few-shot performance and provides the first probabilistic estimation of the few-shot budget for effective TL-based autotuning. We compare our generative TL approach with state-of-the-art autotuning techniques on several benchmarks. We find that the GC is capable of achieving 64.37% of peak few-shot performance in its first evaluation. Furthermore, the GC model can determine a few-shot transfer budget that yields up to 33.39$\times$ speedup, a dramatic improvement over the 20.58$\times$ speedup using prior techniques.
* 13 pages, 5 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2023, available at https://dl.acm.org/doi/10.1145/3577193.3593712
FULL-W2V: Fully Exploiting Data Reuse for W2V on GPU-Accelerated Systems
Dec 12, 2023



Word2Vec remains one of the highly-impactful innovations in the field of Natural Language Processing (NLP) that represents latent grammatical and syntactical information in human text with dense vectors in a low dimension. Word2Vec has high computational cost due to the algorithm's inherent sequentiality, intensive memory accesses, and the large vocabularies it represents. While prior studies have investigated technologies to explore parallelism and improve memory system performance, they struggle to effectively gain throughput on powerful GPUs. We identify memory data access and latency as the primary bottleneck in prior works on GPUs, which prevents highly optimized kernels from attaining the architecture's peak performance. We present a novel algorithm, FULL-W2V, which maximally exploits the opportunities for data reuse in the W2V algorithm and leverages GPU architecture and resources to reduce access to low memory levels and improve temporal locality. FULL-W2V is capable of reducing accesses to GPU global memory significantly, e.g., by more than 89\%, compared to prior state-of-the-art GPU implementations, resulting in significant performance improvement that scales across successive hardware generations. Our prototype implementation achieves 2.97X speedup when ported from Nvidia Pascal P100 to Volta V100 cards, and outperforms the state-of-the-art by 5.72X on V100 cards with the same embedding quality. In-depth analysis indicates that the reduction of memory accesses through register and shared memory caching and high-throughput shared memory reduction leads to a significantly improved arithmetic intensity. FULL-W2V can potentially benefit many applications in NLP and other domains.
* 12 pages, 7 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2021, available at https://doi.org/10.1145/3447818.3460373