 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer-Learning-Based Autotuning Using Gaussian Copula
Jan 09, 2024
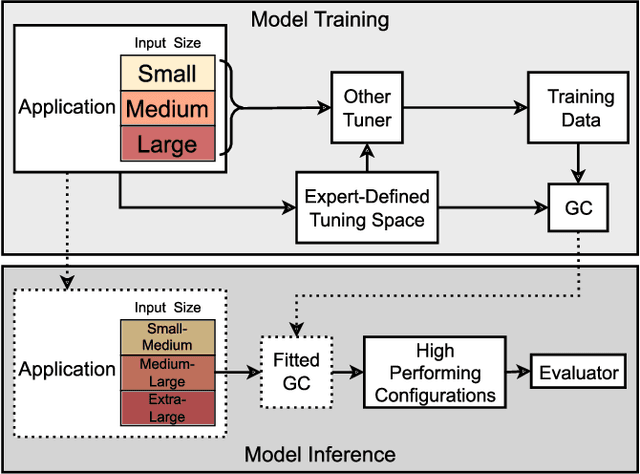


As diverse high-performance computing (HPC) systems are built, many opportunities arise for applications to solve larger problems than ever before. Given the significantly increased complexity of these HPC systems and application tuning, empirical performance tuning, such as autotuning, has emerged as a promising approach in recent years. Despite its effectiveness, autotuning is often a computationally expensive approach. Transfer learning (TL)-based autotuning seeks to address this issue by leveraging the data from prior tuning. Current TL methods for autotuning spend significant time modeling the relationship between parameter configurations and performance, which is ineffective for few-shot (that is, few empirical evaluations) tuning on new tasks. We introduce the first generative TL-based autotuning approach based on the Gaussian copula (GC) to model the high-performing regions of the search space from prior data and then generate high-performing configurations for new tasks. This allows a sampling-based approach that maximizes few-shot performance and provides the first probabilistic estimation of the few-shot budget for effective TL-based autotuning. We compare our generative TL approach with state-of-the-art autotuning techniques on several benchmarks. We find that the GC is capable of achieving 64.37% of peak few-shot performance in its first evaluation. Furthermore, the GC model can determine a few-shot transfer budget that yields up to 33.39$\times$ speedup, a dramatic improvement over the 20.58$\times$ speedup using prior techniques.
* 13 pages, 5 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2023, available at https://dl.acm.org/doi/10.1145/3577193.3593712
ytopt: Autotuning Scientific Applications for Energy Efficiency at Large Scales
Mar 28, 2023



As we enter the exascale computing era, efficiently utilizing power and optimizing the performance of scientific applications under power and energy constraints has become critical and challenging. We propose a low-overhead autotuning framework to autotune performance and energy for various hybrid MPI/OpenMP scientific applications at large scales and to explore the tradeoffs between application runtime and power/energy for energy efficient application execution, then use this framework to autotune four ECP proxy applications -- XSBench, AMG, SWFFT, and SW4lite. Our approach uses Bayesian optimization with a Random Forest surrogate model to effectively search parameter spaces with up to 6 million different configurations on two large-scale production systems, Theta at Argonne National Laboratory and Summit at Oak Ridge National Laboratory. The experimental results show that our autotuning framework at large scales has low overhead and achieves good scalability. Using the proposed autotuning framework to identify the best configurations, we achieve up to 91.59% performance improvement, up to 21.2% energy savings, and up to 37.84% EDP improvement on up to 4,096 nodes.
Customized Monte Carlo Tree Search for LLVM/Polly's Composable Loop Optimization Transformations
May 10, 2021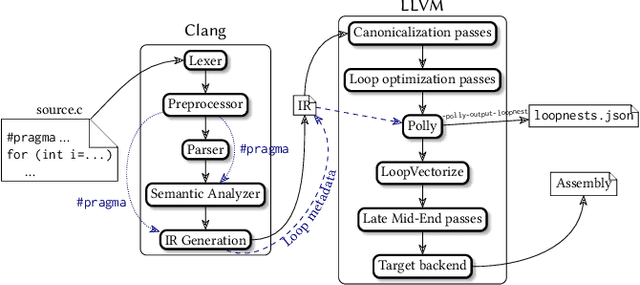
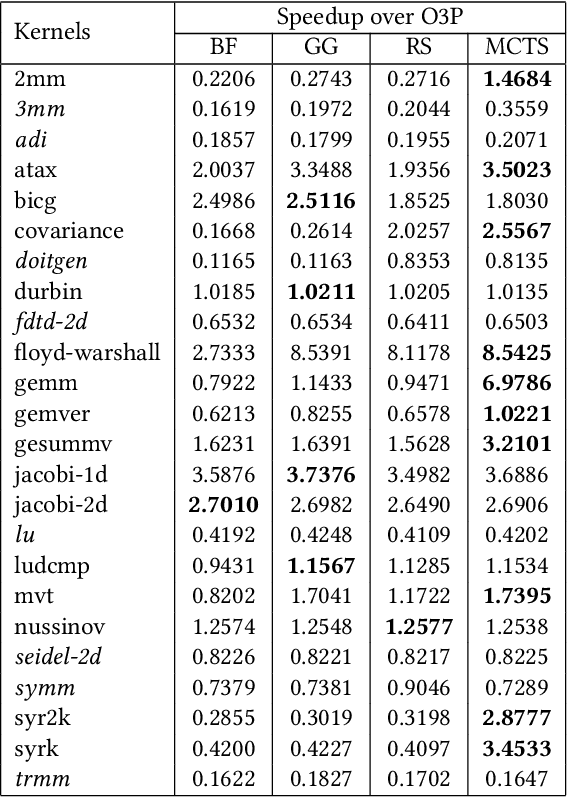
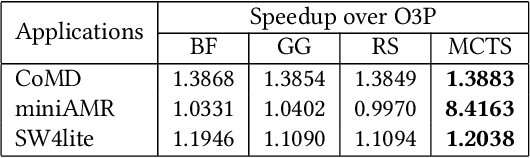
Polly is the LLVM project's polyhedral loop nest optimizer. Recently, user-directed loop transformation pragmas were proposed based on LLVM/Clang and Polly. The search space exposed by the transformation pragmas is a tree, wherein each node represents a specific combination of loop transformations that can be applied to the code resulting from the parent node's loop transformations. We have developed a search algorithm based on Monte Carlo tree search (MCTS) to find the best combination of loop transformations. Our algorithm consists of two phases: exploring loop transformations at different depths of the tree to identify promising regions in the tree search space and exploiting those regions by performing a local search. Moreover, a restart mechanism is used to avoid the MCTS getting trapped in a local solution. The best and worst solutions are transferred from the previous phases of the restarts to leverage the search history. We compare our approach with random, greedy, and breadth-first search methods on PolyBench kernels and ECP proxy applications. Experimental results show that our MCTS algorithm finds pragma combinations with a speedup of 2.3x over Polly's heuristic optimizations on average.
Autotuning PolyBench Benchmarks with LLVM Clang/Polly Loop Optimization Pragmas Using Bayesian Optimization (extended version)
Apr 27, 2021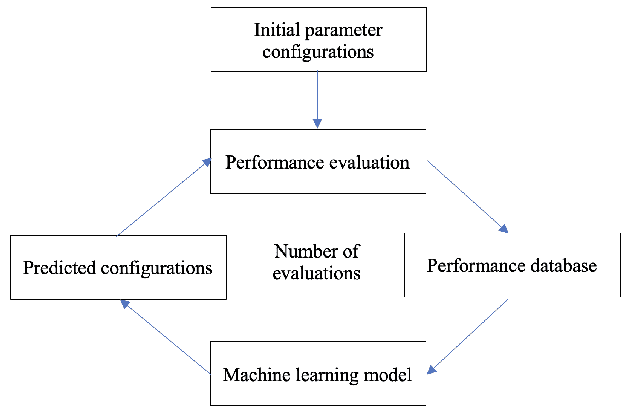


In this paper, we develop a ytopt autotuning framework that leverages Bayesian optimization to explore the parameter space search and compare four different supervised learning methods within Bayesian optimization and evaluate their effectiveness. We select six of the most complex PolyBench benchmarks and apply the newly developed LLVM Clang/Polly loop optimization pragmas to the benchmarks to optimize them. We then use the autotuning framework to optimize the pragma parameters to improve their performance. The experimental results show that our autotuning approach outperforms the other compiling methods to provide the smallest execution time for the benchmarks syr2k, 3mm, heat-3d, lu, and covariance with two large datasets in 200 code evaluations for effectively searching the parameter spaces with up to 170,368 different configurations. We find that the Floyd-Warshall benchmark did not benefit from autotuning because Polly uses heuristics to optimize the benchmark to make it run much slower. To cope with this issue, we provide some compiler option solutions to improve the performance. Then we present loop autotuning without a user's knowledge using a simple mctree autotuning framework to further improve the performance of the Floyd-Warshall benchmark. We also extend the ytopt autotuning framework to tune a deep learning application.
Autotuning PolyBench Benchmarks with LLVM Clang/Polly Loop Optimization Pragmas Using Bayesian Optimization
Oct 15, 2020An autotuning is an approach that explores a search space of possible implementations/configurations of a kernel or an application by selecting and evaluating a subset of implementations/configurations on a target platform and/or use models to identify a high performance implementation/configuration. In this paper, we develop an autotuning framework that leverages Bayesian optimization to explore the parameter space search. We select six of the most complex benchmarks from the application domains of the PolyBench benchmarks (syr2k, 3mm, heat-3d, lu, covariance, and Floyd-Warshall) and apply the newly developed LLVM Clang/Polly loop optimization pragmas to the benchmarks to optimize them. We then use the autotuning framework to optimize the pragma parameters to improve their performance. The experimental results show that our autotuning approach outperforms the other compiling methods to provide the smallest execution time for the benchmarks syr2k, 3mm, heat-3d, lu, and covariance with two large datasets in 200 code evaluations for effectively searching the parameter spaces with up to 170,368 different configurations. We compare four different supervised learning methods within Bayesian optimization and evaluate their effectiveness. We find that the Floyd-Warshall benchmark did not benefit from autotuning because Polly uses heuristics to optimize the benchmark to make it run much slower. To cope with this issue, we provide some compiler option solutions to improve the performance.
Autotuning Search Space for Loop Transformations
Oct 13, 2020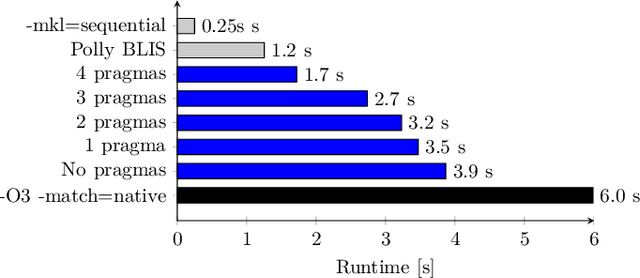


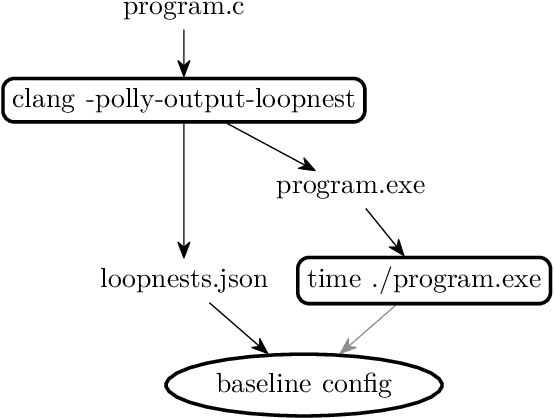
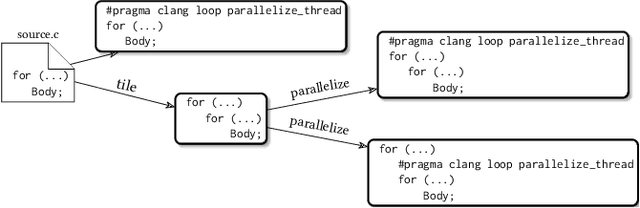
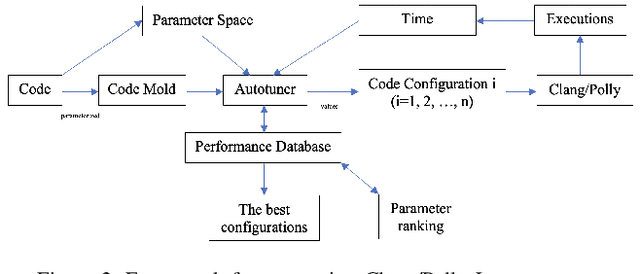
One of the challenges for optimizing compilers is to predict whether applying an optimization will improve its execution speed. Programmers may override the compiler's profitability heuristic using optimization directives such as pragmas in the source code. Machine learning in the form of autotuning can assist users in finding the best optimizations for each platform. In this paper we propose a loop transformation search space that takes the form of a tree, in contrast to previous approaches that usually use vector spaces to represent loop optimization configurations. We implemented a simple autotuner exploring the search space and applied it to a selected set of PolyBench kernels. While the autotuner is capable of representing every possible sequence of loop transformations and their relations, the results motivate the use of better search strategies such as Monte Carlo tree search to find sophisticated loop transformations such as multilevel tiling.
Design and Use of Loop-Transformation Pragmas
Oct 06, 2019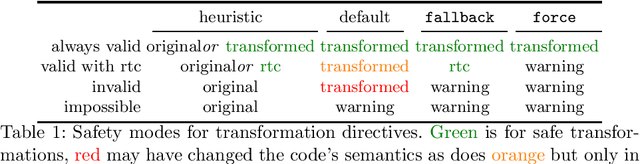
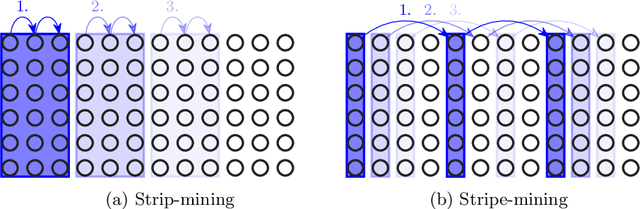

Adding a pragma directive into the source code is arguably easier than rewriting it, for instance for loop unrolling. Moreover, if the application is maintained for multiple platforms, their difference in performance characteristics may require different code transformations. Code transformation directives allow replacing the directives depending on the platform, i.e. separation of code semantics and its performance optimization. In this paper, we explore the design space (syntax and semantics) of adding such directive into a future OpenMP specification. Using a prototype implementation in Clang, we demonstrate the usefulness of such directives on a few benchmarks.