 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer-Learning-Based Autotuning Using Gaussian Copula
Jan 09, 2024
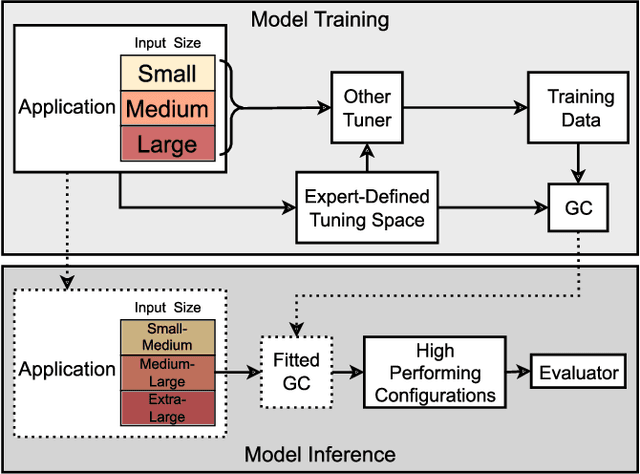


As diverse high-performance computing (HPC) systems are built, many opportunities arise for applications to solve larger problems than ever before. Given the significantly increased complexity of these HPC systems and application tuning, empirical performance tuning, such as autotuning, has emerged as a promising approach in recent years. Despite its effectiveness, autotuning is often a computationally expensive approach. Transfer learning (TL)-based autotuning seeks to address this issue by leveraging the data from prior tuning. Current TL methods for autotuning spend significant time modeling the relationship between parameter configurations and performance, which is ineffective for few-shot (that is, few empirical evaluations) tuning on new tasks. We introduce the first generative TL-based autotuning approach based on the Gaussian copula (GC) to model the high-performing regions of the search space from prior data and then generate high-performing configurations for new tasks. This allows a sampling-based approach that maximizes few-shot performance and provides the first probabilistic estimation of the few-shot budget for effective TL-based autotuning. We compare our generative TL approach with state-of-the-art autotuning techniques on several benchmarks. We find that the GC is capable of achieving 64.37% of peak few-shot performance in its first evaluation. Furthermore, the GC model can determine a few-shot transfer budget that yields up to 33.39$\times$ speedup, a dramatic improvement over the 20.58$\times$ speedup using prior techniques.
* 13 pages, 5 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2023, available at https://dl.acm.org/doi/10.1145/3577193.3593712
ytopt: Autotuning Scientific Applications for Energy Efficiency at Large Scales
Mar 28, 2023



As we enter the exascale computing era, efficiently utilizing power and optimizing the performance of scientific applications under power and energy constraints has become critical and challenging. We propose a low-overhead autotuning framework to autotune performance and energy for various hybrid MPI/OpenMP scientific applications at large scales and to explore the tradeoffs between application runtime and power/energy for energy efficient application execution, then use this framework to autotune four ECP proxy applications -- XSBench, AMG, SWFFT, and SW4lite. Our approach uses Bayesian optimization with a Random Forest surrogate model to effectively search parameter spaces with up to 6 million different configurations on two large-scale production systems, Theta at Argonne National Laboratory and Summit at Oak Ridge National Laboratory. The experimental results show that our autotuning framework at large scales has low overhead and achieves good scalability. Using the proposed autotuning framework to identify the best configurations, we achieve up to 91.59% performance improvement, up to 21.2% energy savings, and up to 37.84% EDP improvement on up to 4,096 nodes.
HPC Storage Service Autotuning Using Variational-Autoencoder-Guided Asynchronous Bayesian Optimization
Oct 03, 2022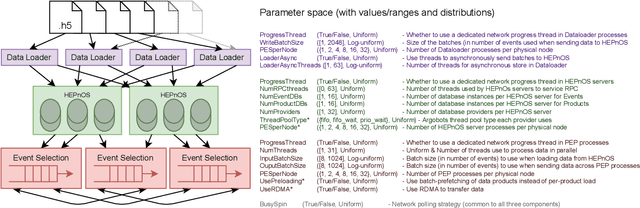
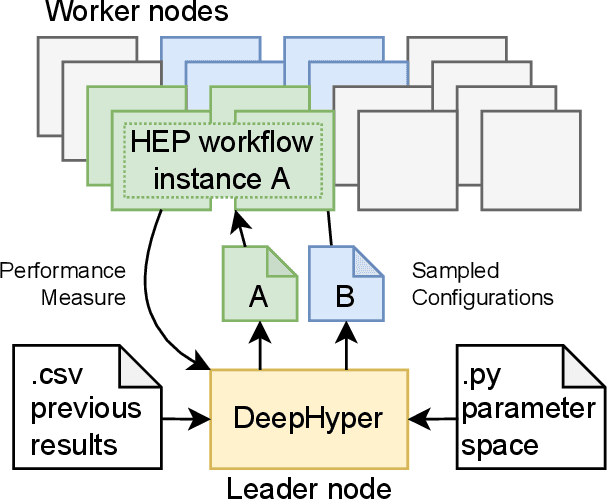
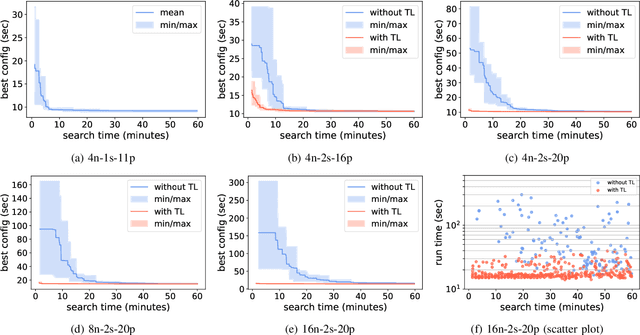
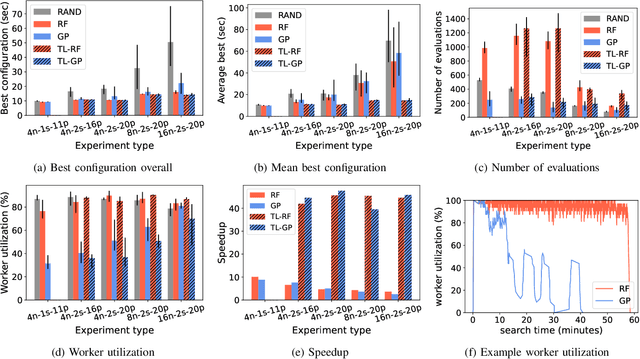
Distributed data storage services tailored to specific applications have grown popular in the high-performance computing (HPC) community as a way to address I/O and storage challenges. These services offer a variety of specific interfaces, semantics, and data representations. They also expose many tuning parameters, making it difficult for their users to find the best configuration for a given workload and platform. To address this issue, we develop a novel variational-autoencoder-guided asynchronous Bayesian optimization method to tune HPC storage service parameters. Our approach uses transfer learning to leverage prior tuning results and use a dynamically updated surrogate model to explore the large parameter search space in a systematic way. We implement our approach within the DeepHyper open-source framework, and apply it to the autotuning of a high-energy physics workflow on Argonne's Theta supercomputer. We show that our transfer-learning approach enables a more than $40\times$ search speedup over random search, compared with a $2.5\times$ to $10\times$ speedup when not using transfer learning. Additionally, we show that our approach is on par with state-of-the-art autotuning frameworks in speed and outperforms them in resource utilization and parallelization capabilities.
Customized Monte Carlo Tree Search for LLVM/Polly's Composable Loop Optimization Transformations
May 10, 2021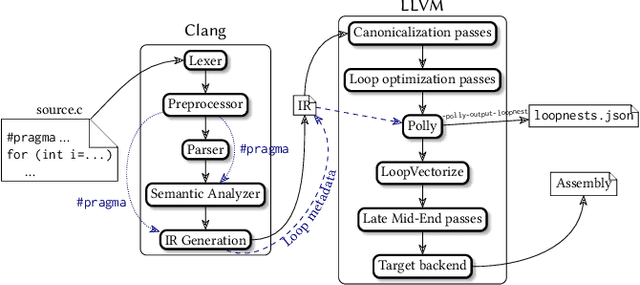
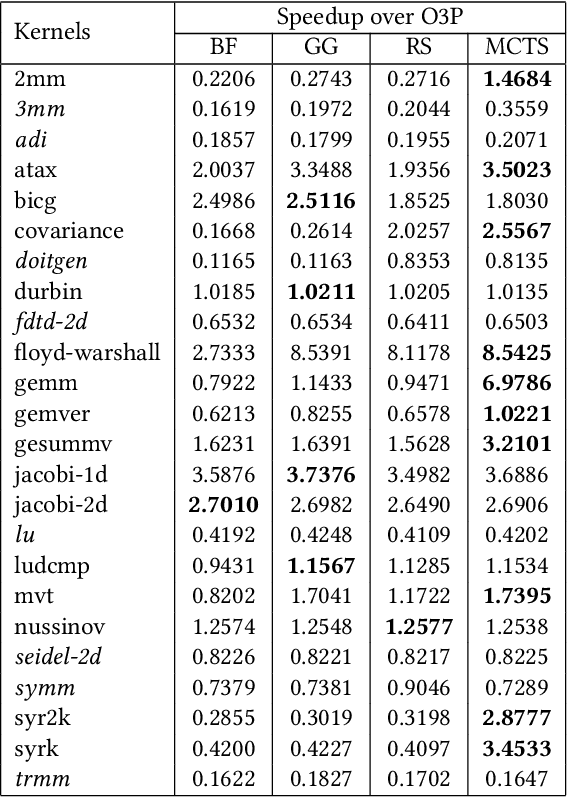
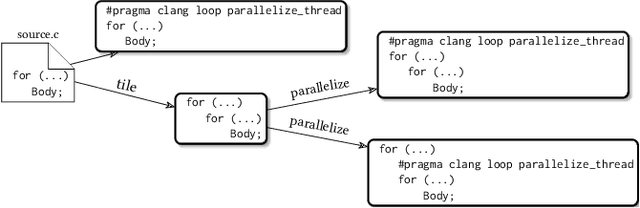
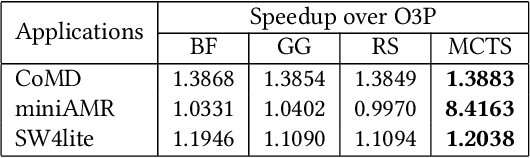
Polly is the LLVM project's polyhedral loop nest optimizer. Recently, user-directed loop transformation pragmas were proposed based on LLVM/Clang and Polly. The search space exposed by the transformation pragmas is a tree, wherein each node represents a specific combination of loop transformations that can be applied to the code resulting from the parent node's loop transformations. We have developed a search algorithm based on Monte Carlo tree search (MCTS) to find the best combination of loop transformations. Our algorithm consists of two phases: exploring loop transformations at different depths of the tree to identify promising regions in the tree search space and exploiting those regions by performing a local search. Moreover, a restart mechanism is used to avoid the MCTS getting trapped in a local solution. The best and worst solutions are transferred from the previous phases of the restarts to leverage the search history. We compare our approach with random, greedy, and breadth-first search methods on PolyBench kernels and ECP proxy applications. Experimental results show that our MCTS algorithm finds pragma combinations with a speedup of 2.3x over Polly's heuristic optimizations on average.
Inverse Classification with Limited Budget and Maximum Number of Perturbed Samples
Sep 29, 2020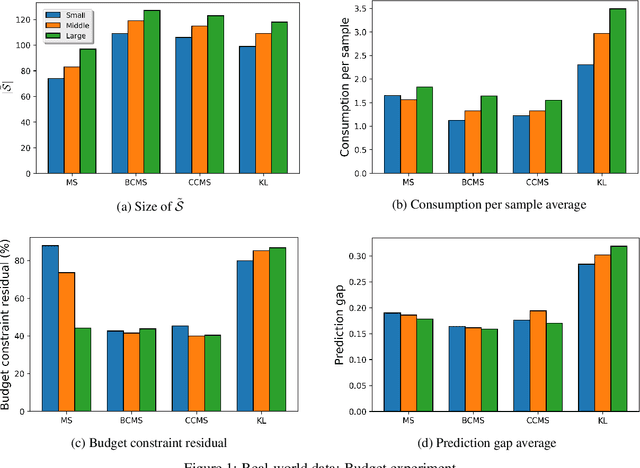

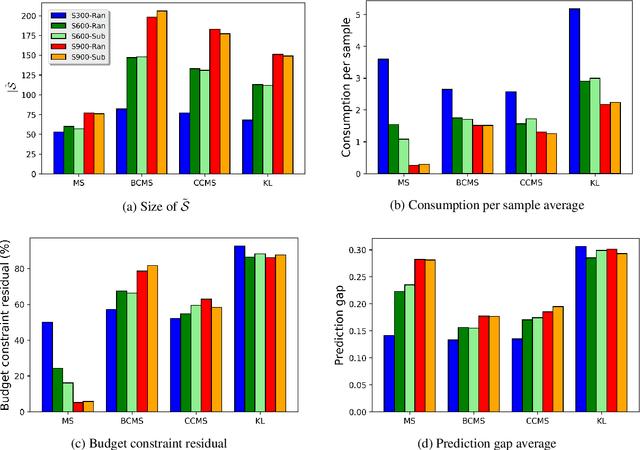
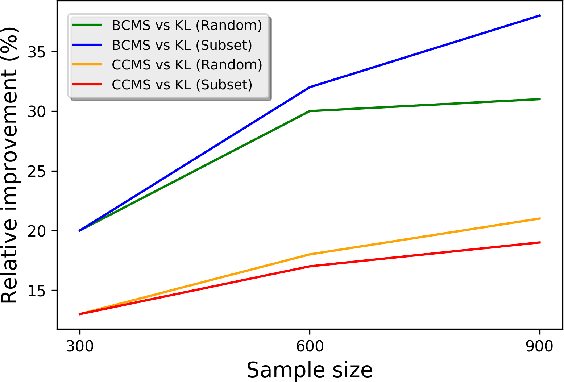
Most recent machine learning research focuses on developing new classifiers for the sake of improving classification accuracy. With many well-performing state-of-the-art classifiers available, there is a growing need for understanding interpretability of a classifier necessitated by practical purposes such as to find the best diet recommendation for a diabetes patient. Inverse classification is a post modeling process to find changes in input features of samples to alter the initially predicted class. It is useful in many business applications to determine how to adjust a sample input data such that the classifier predicts it to be in a desired class. In real world applications, a budget on perturbations of samples corresponding to customers or patients is usually considered, and in this setting, the number of successfully perturbed samples is key to increase benefits. In this study, we propose a new framework to solve inverse classification that maximizes the number of perturbed samples subject to a per-feature-budget limits and favorable classification classes of the perturbed samples. We design algorithms to solve this optimization problem based on gradient methods, stochastic processes, Lagrangian relaxations, and the Gumbel trick. In experiments, we find that our algorithms based on stochastic processes exhibit an excellent performance in different budget settings and they scale well.
Combined convolutional and recurrent neural networks for hierarchical classification of images
Oct 03, 2018

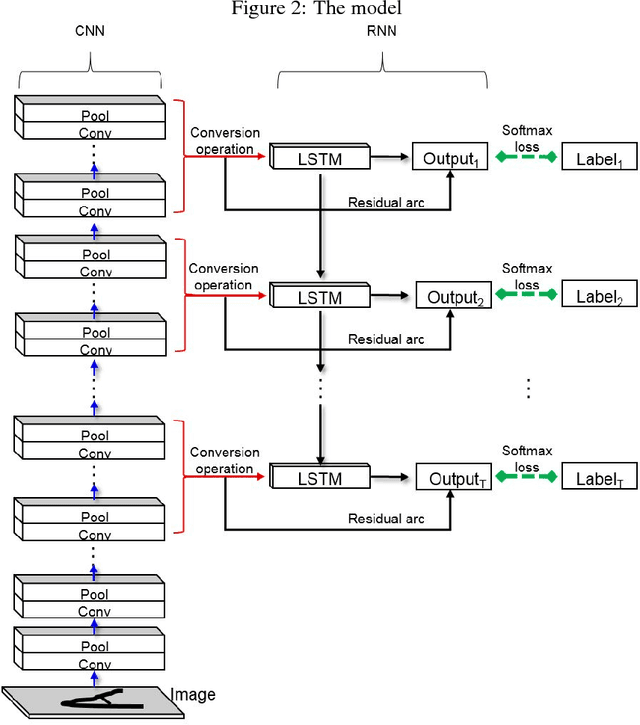

Deep learning models based on CNNs are predominantly used in image classification tasks. Such approaches, assuming independence of object categories, normally use a CNN as a feature learner and apply a flat classifier on top of it. Object classes in many settings have hierarchical relations, and classifiers exploiting these relations should perform better. We propose hierarchical classification models combining a CNN to extract hierarchical representations of images, and an RNN or sequence-to-sequence model to capture a hierarchical tree of classes. In addition, we apply residual learning to the RNN part in oder to facilitate training our compound model and improve generalization of the model. Experimental results on a real world proprietary dataset of images show that our hierarchical networks perform better than state-of-the-art CNNs.
Improved Classification Based on Deep Belief Networks
Apr 25, 2018
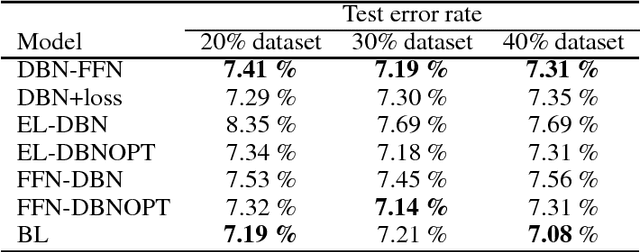
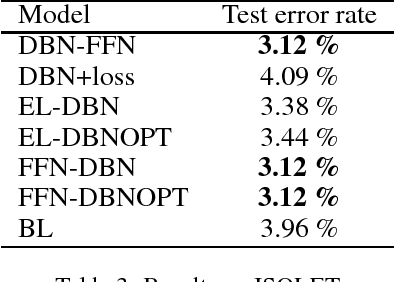
For better classification generative models are used to initialize the model and model features before training a classifier. Typically it is needed to solve separate unsupervised and supervised learning problems. Generative restricted Boltzmann machines and deep belief networks are widely used for unsupervised learning. We developed several supervised models based on DBN in order to improve this two-phase strategy. Modifying the loss function to account for expectation with respect to the underlying generative model, introducing weight bounds, and multi-level programming are applied in model development. The proposed models capture both unsupervised and supervised objectives effectively. The computational study verifies that our models perform better than the two-phase training approach.