 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPC Storage Service Autotuning Using Variational-Autoencoder-Guided Asynchronous Bayesian Optimization
Paper and Code
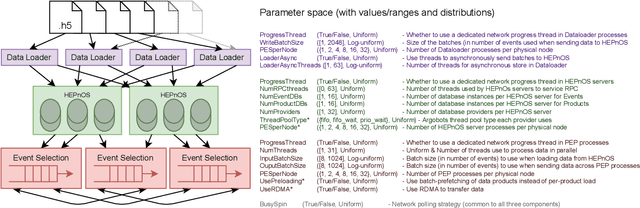
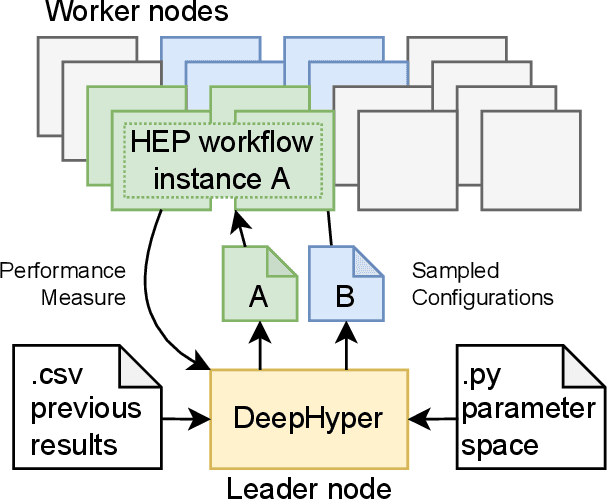
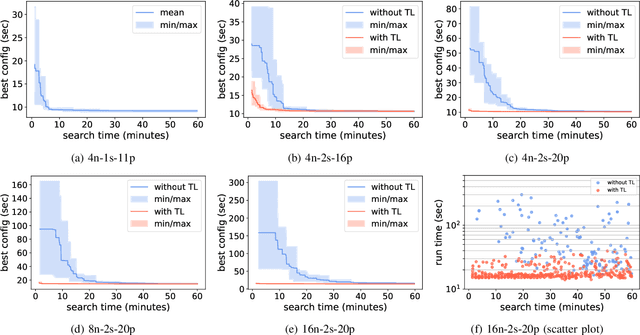
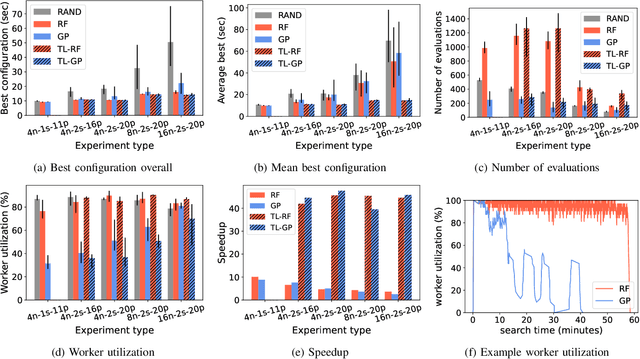
Distributed data storage services tailored to specific applications have grown popular in the high-performance computing (HPC) community as a way to address I/O and storage challenges. These services offer a variety of specific interfaces, semantics, and data representations. They also expose many tuning parameters, making it difficult for their users to find the best configuration for a given workload and platform. To address this issue, we develop a novel variational-autoencoder-guided asynchronous Bayesian optimization method to tune HPC storage service parameters. Our approach uses transfer learning to leverage prior tuning results and use a dynamically updated surrogate model to explore the large parameter search space in a systematic way. We implement our approach within the DeepHyper open-source framework, and apply it to the autotuning of a high-energy physics workflow on Argonne's Theta supercomputer. We show that our transfer-learning approach enables a more than $40\times$ search speedup over random search, compared with a $2.5\times$ to $10\times$ speedup when not using transfer learning. Additionally, we show that our approach is on par with state-of-the-art autotuning frameworks in speed and outperforms them in resource utilization and parallelization capabilities.