 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Competitions and Benchmarks: Dataset Development
Apr 15, 2024



Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Streamlining Ocean Dynamics Modeling with Fourier Neural Operators: A Multiobjective Hyperparameter and Architecture Optimization Approach
Apr 10, 2024



Training an effective deep learning model to learn ocean processes involves careful choices of various hyperparameters. We leverage the advanced search algorithms for multiobjective optimization in DeepHyper, a scalable hyperparameter optimization software, to streamline the development of neural networks tailored for ocean modeling. The focus is on optimizing Fourier neural operators (FNOs), a data-driven model capable of simulating complex ocean behaviors. Selecting the correct model and tuning the hyperparameters are challenging tasks, requiring much effort to ensure model accuracy. DeepHyper allows efficient exploration of hyperparameters associated with data preprocessing, FNO architecture-related hyperparameters, and various model training strategies. We aim to obtain an optimal set of hyperparameters leading to the most performant model. Moreover, on top of the commonly used mean squared error for model training, we propose adopting the negative anomaly correlation coefficient as the additional loss term to improve model performance and investigate the potential trade-off between the two terms. The experimental results show that the optimal set of hyperparameters enhanced model performance in single timestepping forecasting and greatly exceeded the baseline configuration in the autoregressive rollout for long-horizon forecasting up to 30 days. Utilizing DeepHyper, we demonstrate an approach to enhance the use of FNOs in ocean dynamics forecasting, offering a scalable solution with improved precision.
The Unreasonable Effectiveness Of Early Discarding After One Epoch In Neural Network Hyperparameter Optimization
Apr 05, 2024



To reach high performance with deep learning, hyperparameter optimization (HPO) is essential. This process is usually time-consuming due to costly evaluations of neural networks. Early discarding techniques limit the resources granted to unpromising candidates by observing the empirical learning curves and canceling neural network training as soon as the lack of competitiveness of a candidate becomes evident. Despite two decades of research, little is understood about the trade-off between the aggressiveness of discarding and the loss of predictive performance. Our paper studies this trade-off for several commonly used discarding techniques such as successive halving and learning curve extrapolation. Our surprising finding is that these commonly used techniques offer minimal to no added value compared to the simple strategy of discarding after a constant number of epochs of training. The chosen number of epochs depends mostly on the available compute budget. We call this approach i-Epoch (i being the constant number of epochs with which neural networks are trained) and suggest to assess the quality of early discarding techniques by comparing how their Pareto-Front (in consumed training epochs and predictive performance) complement the Pareto-Front of i-Epoch.
Optimizing Distributed Training on Frontier for Large Language Models
Dec 21, 2023
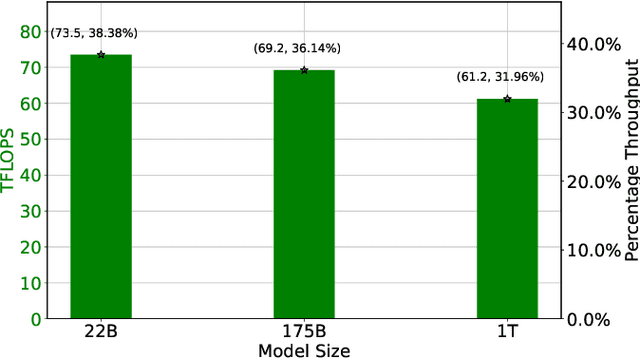
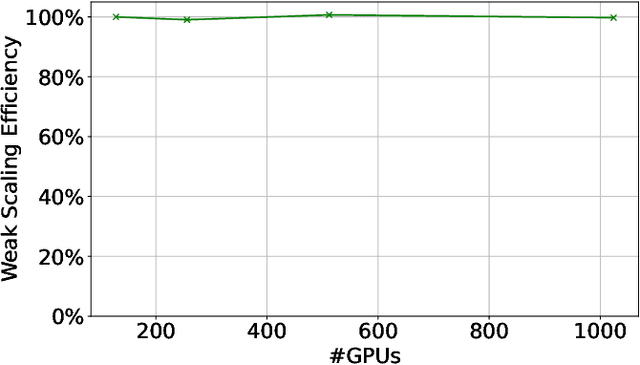
Large language models (LLMs) have demonstrated remarkable success as foundational models, benefiting various downstream applications through fine-tuning. Recent studies on loss scaling have demonstrated the superior performance of larger LLMs compared to their smaller counterparts. Nevertheless, training LLMs with billions of parameters poses significant challenges and requires considerable computational resources. For example, training a one trillion parameter GPT-style model on 20 trillion tokens requires a staggering 120 million exaflops of computation. This research explores efficient distributed training strategies to extract this computation from Frontier, the world's first exascale supercomputer dedicated to open science. We enable and investigate various model and data parallel training techniques, such as tensor parallelism, pipeline parallelism, and sharded data parallelism, to facilitate training a trillion-parameter model on Frontier. We empirically assess these techniques and their associated parameters to determine their impact on memory footprint, communication latency, and GPU's computational efficiency. We analyze the complex interplay among these techniques and find a strategy to combine them to achieve high throughput through hyperparameter tuning. We have identified efficient strategies for training large LLMs of varying sizes through empirical analysis and hyperparameter tuning. For 22 Billion, 175 Billion, and 1 Trillion parameters, we achieved GPU throughputs of $38.38\%$, $36.14\%$, and $31.96\%$, respectively. For the training of the 175 Billion parameter model and the 1 Trillion parameter model, we achieved $100\%$ weak scaling efficiency on 1024 and 3072 MI250X GPUs, respectively. We also achieved strong scaling efficiencies of $89\%$ and $87\%$ for these two models.
Parallel Multi-Objective Hyperparameter Optimization with Uniform Normalization and Bounded Objectives
Sep 26, 2023



Machine learning (ML) methods offer a wide range of configurable hyperparameters that have a significant influence on their performance. While accuracy is a commonly used performance objective, in many settings, it is not sufficient. Optimizing the ML models with respect to multiple objectives such as accuracy, confidence, fairness, calibration, privacy, latency, and memory consumption is becoming crucial. To that end, hyperparameter optimization, the approach to systematically optimize the hyperparameters, which is already challenging for a single objective, is even more challenging for multiple objectives. In addition, the differences in objective scales, the failures, and the presence of outlier values in objectives make the problem even harder. We propose a multi-objective Bayesian optimization (MoBO) algorithm that addresses these problems through uniform objective normalization and randomized weights in scalarization. We increase the efficiency of our approach by imposing constraints on the objective to avoid exploring unnecessary configurations (e.g., insufficient accuracy). Finally, we leverage an approach to parallelize the MoBO which results in a 5x speed-up when using 16x more workers.
Is One Epoch All You Need For Multi-Fidelity Hyperparameter Optimization?
Jul 28, 2023



Hyperparameter optimization (HPO) is crucial for fine-tuning machine learning models but can be computationally expensive. To reduce costs, Multi-fidelity HPO (MF-HPO) leverages intermediate accuracy levels in the learning process and discards low-performing models early on. We compared various representative MF-HPO methods against a simple baseline on classical benchmark data. The baseline involved discarding all models except the Top-K after training for only one epoch, followed by further training to select the best model. Surprisingly, this baseline achieved similar results to its counterparts, while requiring an order of magnitude less computation. Upon analyzing the learning curves of the benchmark data, we observed a few dominant learning curves, which explained the success of our baseline. This suggests that researchers should (1) always use the suggested baseline in benchmarks and (2) broaden the diversity of MF-HPO benchmarks to include more complex cases.
Quantifying uncertainty for deep learning based forecasting and flow-reconstruction using neural architecture search ensembles
Feb 20, 2023



Classical problems in computational physics such as data-driven forecasting and signal reconstruction from sparse sensors have recently seen an explosion in deep neural network (DNN) based algorithmic approaches. However, most DNN models do not provide uncertainty estimates, which are crucial for establishing the trustworthiness of these techniques in downstream decision making tasks and scenarios. In recent years, ensemble-based methods have achieved significant success for the uncertainty quantification in DNNs on a number of benchmark problems. However, their performance on real-world applications remains under-explored. In this work, we present an automated approach to DNN discovery and demonstrate how this may also be utilized for ensemble-based uncertainty quantification. Specifically, we propose the use of a scalable neural and hyperparameter architecture search for discovering an ensemble of DNN models for complex dynamical systems. We highlight how the proposed method not only discovers high-performing neural network ensembles for our tasks, but also quantifies uncertainty seamlessly. This is achieved by using genetic algorithms and Bayesian optimization for sampling the search space of neural network architectures and hyperparameters. Subsequently, a model selection approach is used to identify candidate models for an ensemble set construction. Afterwards, a variance decomposition approach is used to estimate the uncertainty of the predictions from the ensemble. We demonstrate the feasibility of this framework for two tasks - forecasting from historical data and flow reconstruction from sparse sensors for the sea-surface temperature. We demonstrate superior performance from the ensemble in contrast with individual high-performing models and other benchmarks.
HPC Storage Service Autotuning Using Variational-Autoencoder-Guided Asynchronous Bayesian Optimization
Oct 03, 2022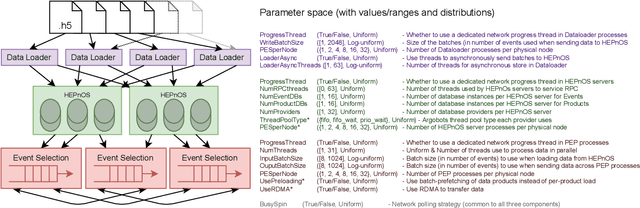
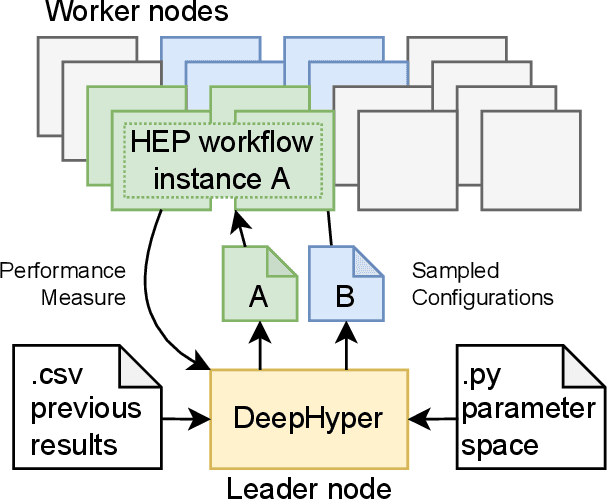
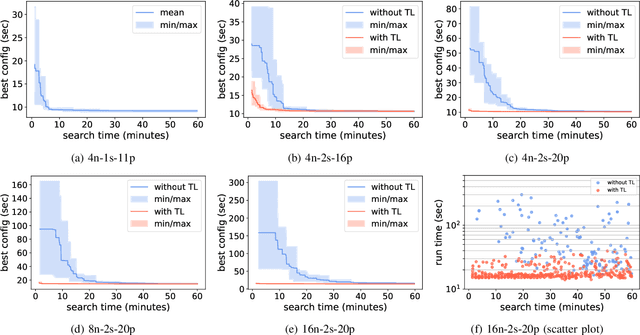
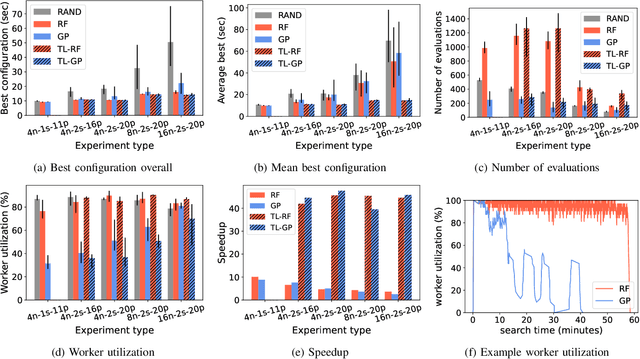
Distributed data storage services tailored to specific applications have grown popular in the high-performance computing (HPC) community as a way to address I/O and storage challenges. These services offer a variety of specific interfaces, semantics, and data representations. They also expose many tuning parameters, making it difficult for their users to find the best configuration for a given workload and platform. To address this issue, we develop a novel variational-autoencoder-guided asynchronous Bayesian optimization method to tune HPC storage service parameters. Our approach uses transfer learning to leverage prior tuning results and use a dynamically updated surrogate model to explore the large parameter search space in a systematic way. We implement our approach within the DeepHyper open-source framework, and apply it to the autotuning of a high-energy physics workflow on Argonne's Theta supercomputer. We show that our transfer-learning approach enables a more than $40\times$ search speedup over random search, compared with a $2.5\times$ to $10\times$ speedup when not using transfer learning. Additionally, we show that our approach is on par with state-of-the-art autotuning frameworks in speed and outperforms them in resource utilization and parallelization capabilities.
Asynchronous Distributed Bayesian Optimization at HPC Scale
Jul 04, 2022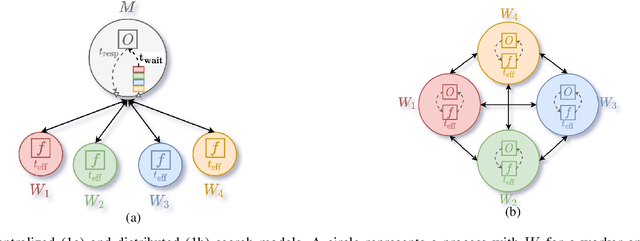
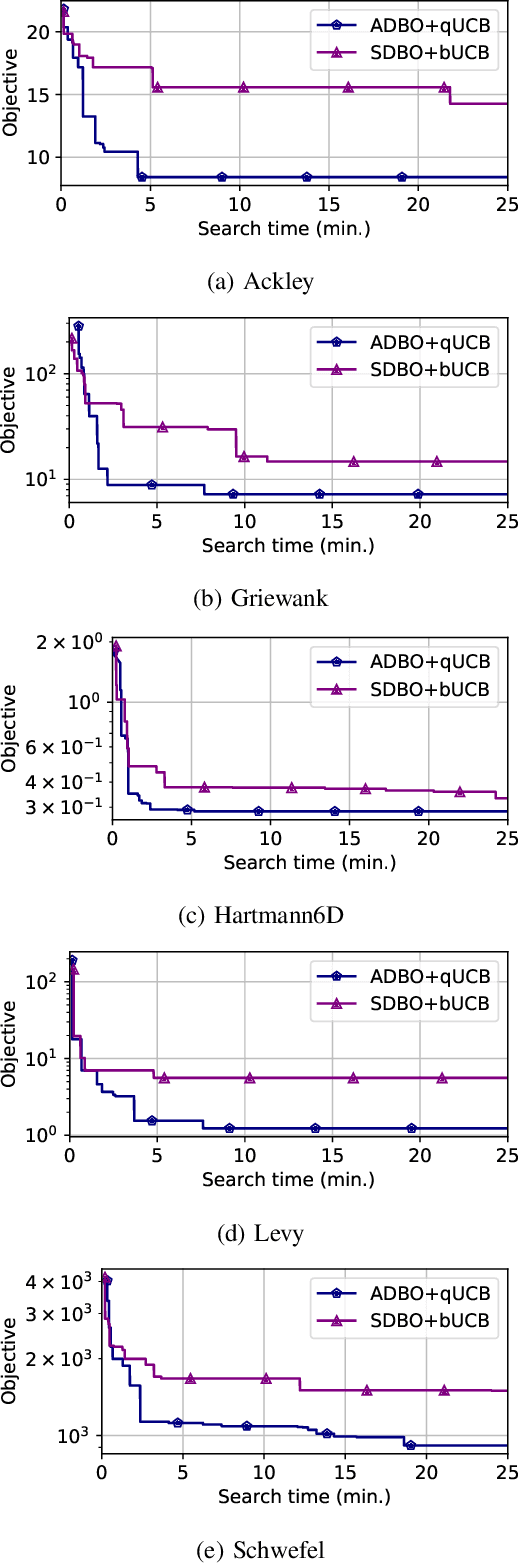
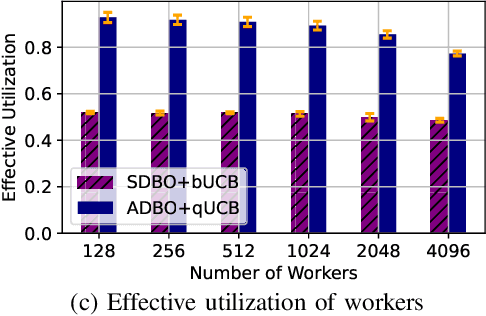
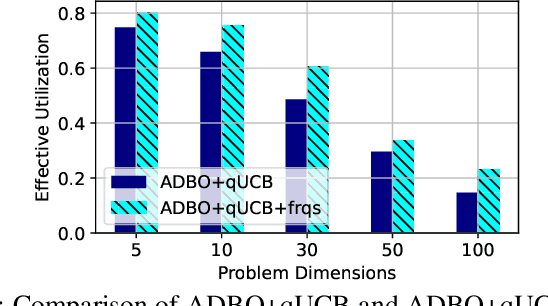
Bayesian optimization (BO) is a widely used approach for computationally expensive black-box optimization such as simulator calibration and hyperparameter optimization of deep learning methods. In BO, a dynamically updated computationally cheap surrogate model is employed to learn the input-output relationship of the black-box function; this surrogate model is used to explore and exploit the promising regions of the input space. Multipoint BO methods adopt a single manager/multiple workers strategy to achieve high-quality solutions in shorter time. However, the computational overhead in multipoint generation schemes is a major bottleneck in designing BO methods that can scale to thousands of workers. We present an asynchronous-distributed BO (ADBO) method wherein each worker runs a search and asynchronously communicates the input-output values of black-box evaluations from all other workers without the manager. We scale our method up to 4,096 workers and demonstrate improvement in the quality of the solution and faster convergence. We demonstrate the effectiveness of our approach for tuning the hyperparameters of neural networks from the Exascale computing project CANDLE benchmarks.
AutoDEUQ: Automated Deep Ensemble with Uncertainty Quantification
Oct 26, 2021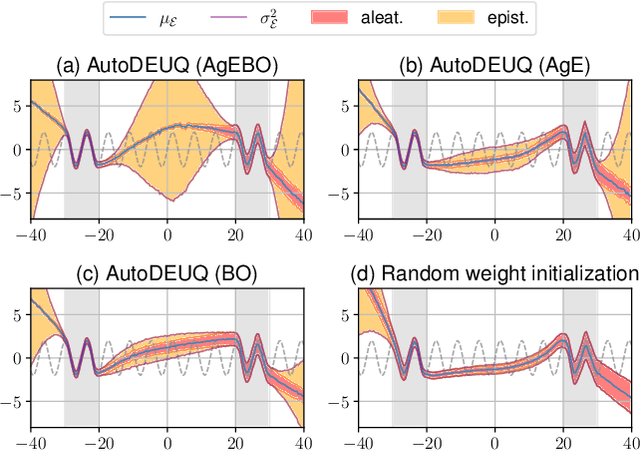
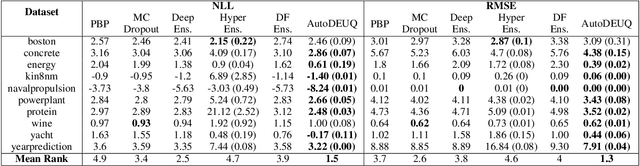
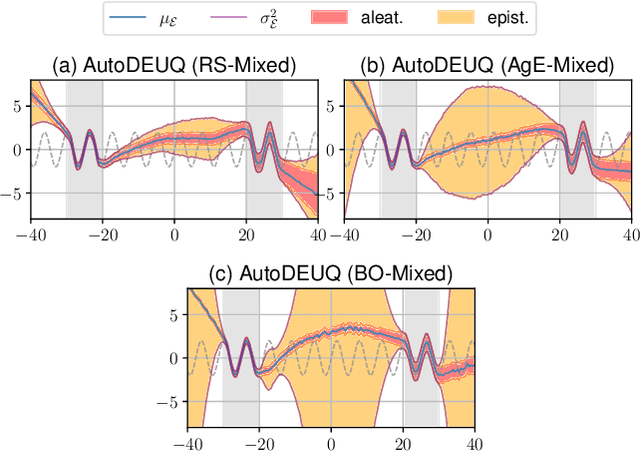
Deep neural networks are powerful predictors for a variety of tasks. However, they do not capture uncertainty directly. Using neural network ensembles to quantify uncertainty is competitive with approaches based on Bayesian neural networks while benefiting from better computational scalability. However, building ensembles of neural networks is a challenging task because, in addition to choosing the right neural architecture or hyperparameters for each member of the ensemble, there is an added cost of training each model. We propose AutoDEUQ, an automated approach for generating an ensemble of deep neural networks. Our approach leverages joint neural architecture and hyperparameter search to generate ensembles. We use the law of total variance to decompose the predictive variance of deep ensembles into aleatoric (data) and epistemic (model) uncertainties. We show that AutoDEUQ outperforms probabilistic backpropagation, Monte Carlo dropout, deep ensemble, distribution-free ensembles, and hyper ensemble methods on a number of regression benchmarks.