 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Distributed Training on Frontier for Large Language Models
Paper and Code
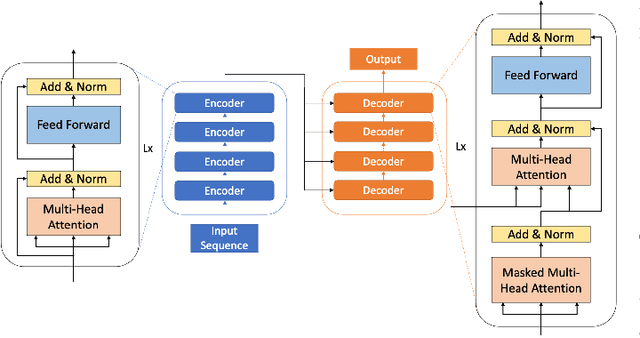
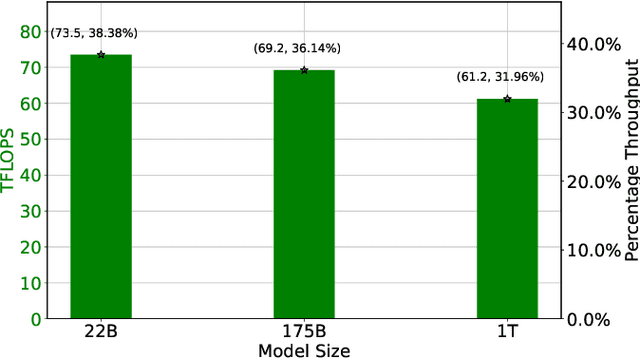
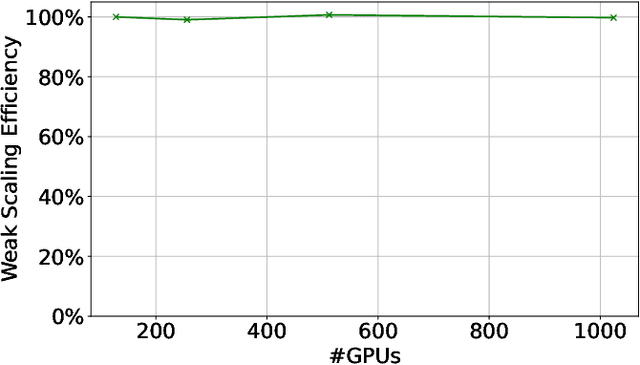
Large language models (LLMs) have demonstrated remarkable success as foundational models, benefiting various downstream applications through fine-tuning. Recent studies on loss scaling have demonstrated the superior performance of larger LLMs compared to their smaller counterparts. Nevertheless, training LLMs with billions of parameters poses significant challenges and requires considerable computational resources. For example, training a one trillion parameter GPT-style model on 20 trillion tokens requires a staggering 120 million exaflops of computation. This research explores efficient distributed training strategies to extract this computation from Frontier, the world's first exascale supercomputer dedicated to open science. We enable and investigate various model and data parallel training techniques, such as tensor parallelism, pipeline parallelism, and sharded data parallelism, to facilitate training a trillion-parameter model on Frontier. We empirically assess these techniques and their associated parameters to determine their impact on memory footprint, communication latency, and GPU's computational efficiency. We analyze the complex interplay among these techniques and find a strategy to combine them to achieve high throughput through hyperparameter tuning. We have identified efficient strategies for training large LLMs of varying sizes through empirical analysis and hyperparameter tuning. For 22 Billion, 175 Billion, and 1 Trillion parameters, we achieved GPU throughputs of $38.38\%$, $36.14\%$, and $31.96\%$, respectively. For the training of the 175 Billion parameter model and the 1 Trillion parameter model, we achieved $100\%$ weak scaling efficiency on 1024 and 3072 MI250X GPUs, respectively. We also achieved strong scaling efficiencies of $89\%$ and $87\%$ for these two models.