 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciTrust 2.0: A Comprehensive Framework for Evaluating Trustworthiness of Large Language Models in Scientific Applications
Oct 29, 2025Large language models (LLMs) have demonstrated transformative potential in scientific research, yet their deployment in high-stakes contexts raises significant trustworthiness concerns. Here, we introduce SciTrust 2.0, a comprehensive framework for evaluating LLM trustworthiness in scientific applications across four dimensions: truthfulness, adversarial robustness, scientific safety, and scientific ethics. Our framework incorporates novel, open-ended truthfulness benchmarks developed through a verified reflection-tuning pipeline and expert validation, alongside a novel ethics benchmark for scientific research contexts covering eight subcategories including dual-use research and bias. We evaluated seven prominent LLMs, including four science-specialized models and three general-purpose industry models, using multiple evaluation metrics including accuracy, semantic similarity measures, and LLM-based scoring. General-purpose industry models overall outperformed science-specialized models across each trustworthiness dimension, with GPT-o4-mini demonstrating superior performance in truthfulness assessments and adversarial robustness. Science-specialized models showed significant deficiencies in logical and ethical reasoning capabilities, along with concerning vulnerabilities in safety evaluations, particularly in high-risk domains such as biosecurity and chemical weapons. By open-sourcing our framework, we provide a foundation for developing more trustworthy AI systems and advancing research on model safety and ethics in scientific contexts.
Decoding Memories: An Efficient Pipeline for Self-Consistency Hallucination Detection
Aug 28, 2025Large language models (LLMs) have demonstrated impressive performance in both research and real-world applications, but they still struggle with hallucination. Existing hallucination detection methods often perform poorly on sentence-level generation or rely heavily on domain-specific knowledge. While self-consistency approaches help address these limitations, they incur high computational costs due to repeated generation. In this paper, we conduct the first study on identifying redundancy in self-consistency methods, manifested as shared prefix tokens across generations, and observe that non-exact-answer tokens contribute minimally to the semantic content. Based on these insights, we propose a novel Decoding Memory Pipeline (DMP) that accelerates generation through selective inference and annealed decoding. Being orthogonal to the model, dataset, decoding strategy, and self-consistency baseline, our DMP consistently improves the efficiency of multi-response generation and holds promise for extension to alignment and reasoning tasks. Extensive experiments show that our method achieves up to a 3x speedup without sacrificing AUROC performance.
Pixel-Resolved Long-Context Learning for Turbulence at Exascale: Resolving Small-scale Eddies Toward the Viscous Limit
Jul 22, 2025Turbulence plays a crucial role in multiphysics applications, including aerodynamics, fusion, and combustion. Accurately capturing turbulence's multiscale characteristics is essential for reliable predictions of multiphysics interactions, but remains a grand challenge even for exascale supercomputers and advanced deep learning models. The extreme-resolution data required to represent turbulence, ranging from billions to trillions of grid points, pose prohibitive computational costs for models based on architectures like vision transformers. To address this challenge, we introduce a multiscale hierarchical Turbulence Transformer that reduces sequence length from billions to a few millions and a novel RingX sequence parallelism approach that enables scalable long-context learning. We perform scaling and science runs on the Frontier supercomputer. Our approach demonstrates excellent performance up to 1.1 EFLOPS on 32,768 AMD GPUs, with a scaling efficiency of 94%. To our knowledge, this is the first AI model for turbulence that can capture small-scale eddies down to the dissipative range.
A Scalable Real-Time Data Assimilation Framework for Predicting Turbulent Atmosphere Dynamics
Jul 16, 2024



The weather and climate domains are undergoing a significant transformation thanks to advances in AI-based foundation models such as FourCastNet, GraphCast, ClimaX and Pangu-Weather. While these models show considerable potential, they are not ready yet for operational use in weather forecasting or climate prediction. This is due to the lack of a data assimilation method as part of their workflow to enable the assimilation of incoming Earth system observations in real time. This limitation affects their effectiveness in predicting complex atmospheric phenomena such as tropical cyclones and atmospheric rivers. To overcome these obstacles, we introduce a generic real-time data assimilation framework and demonstrate its end-to-end performance on the Frontier supercomputer. This framework comprises two primary modules: an ensemble score filter (EnSF), which significantly outperforms the state-of-the-art data assimilation method, namely, the Local Ensemble Transform Kalman Filter (LETKF); and a vision transformer-based surrogate capable of real-time adaptation through the integration of observational data. The ViT surrogate can represent either physics-based models or AI-based foundation models. We demonstrate both the strong and weak scaling of our framework up to 1024 GPUs on the Exascale supercomputer, Frontier. Our results not only illustrate the framework's exceptional scalability on high-performance computing systems, but also demonstrate the importance of supercomputers in real-time data assimilation for weather and climate predictions. Even though the proposed framework is tested only on a benchmark surface quasi-geostrophic (SQG) turbulence system, it has the potential to be combined with existing AI-based foundation models, making it suitable for future operational implementations.
Scalable Artificial Intelligence for Science: Perspectives, Methods and Exemplars
Jun 24, 2024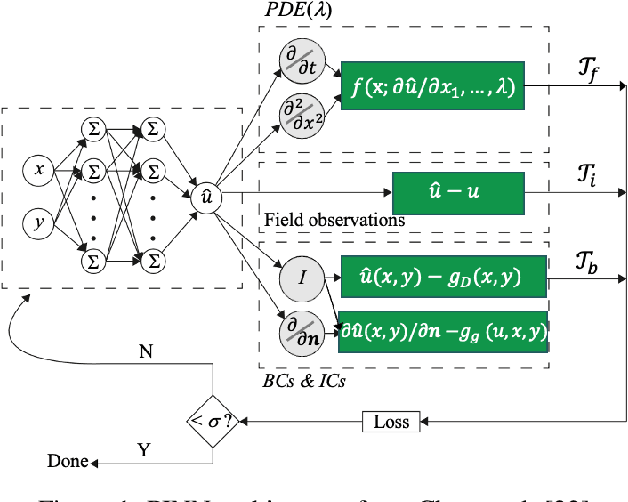
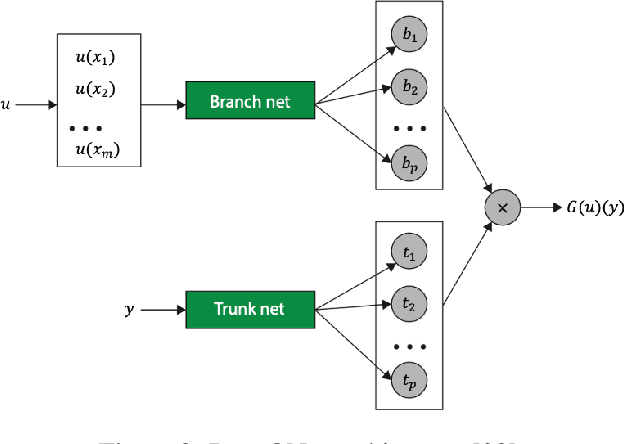
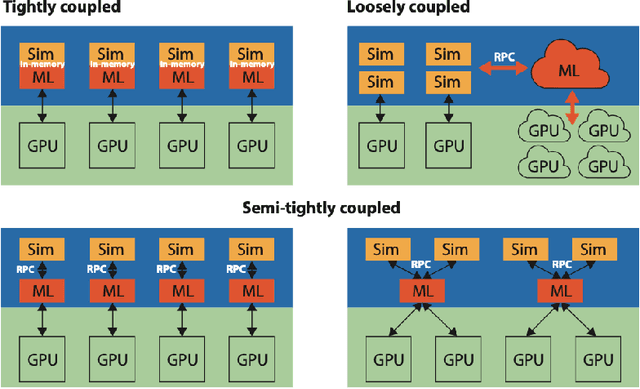
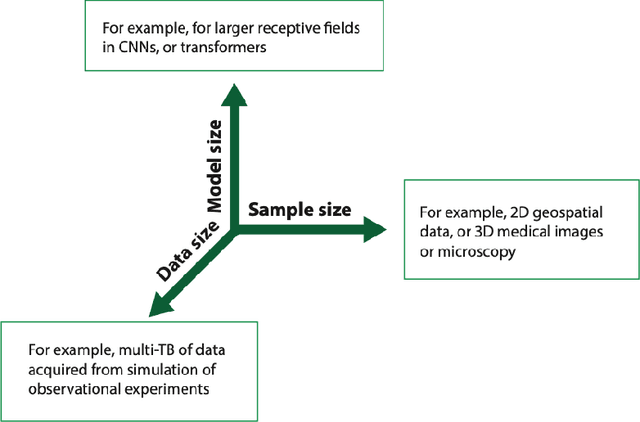
In a post-ChatGPT world, this paper explores the potential of leveraging scalable artificial intelligence for scientific discovery. We propose that scaling up artificial intelligence on high-performance computing platforms is essential to address such complex problems. This perspective focuses on scientific use cases like cognitive simulations, large language models for scientific inquiry, medical image analysis, and physics-informed approaches. The study outlines the methodologies needed to address such challenges at scale on supercomputers or the cloud and provides exemplars of such approaches applied to solve a variety of scientific problems.
ORBIT: Oak Ridge Base Foundation Model for Earth System Predictability
Apr 23, 2024Earth system predictability is challenged by the complexity of environmental dynamics and the multitude of variables involved. Current AI foundation models, although advanced by leveraging large and heterogeneous data, are often constrained by their size and data integration, limiting their effectiveness in addressing the full range of Earth system prediction challenges. To overcome these limitations, we introduce the Oak Ridge Base Foundation Model for Earth System Predictability (ORBIT), an advanced vision-transformer model that scales up to 113 billion parameters using a novel hybrid tensor-data orthogonal parallelism technique. As the largest model of its kind, ORBIT surpasses the current climate AI foundation model size by a thousandfold. Performance scaling tests conducted on the Frontier supercomputer have demonstrated that ORBIT achieves 230 to 707 PFLOPS, with scaling efficiency maintained at 78% to 96% across 24,576 AMD GPUs. These breakthroughs establish new advances in AI-driven climate modeling and demonstrate promise to significantly improve the Earth system predictability.
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Apr 17, 2024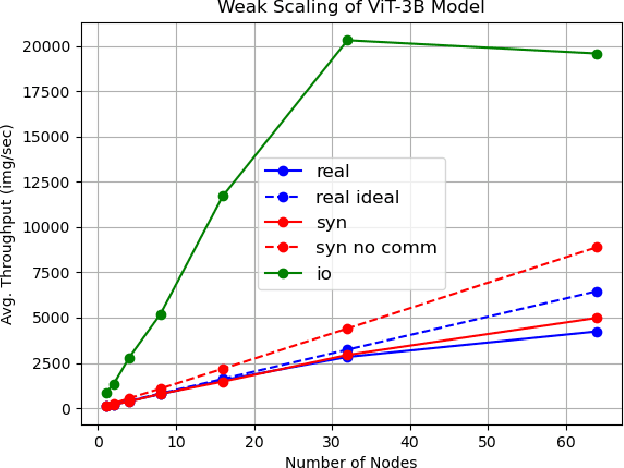
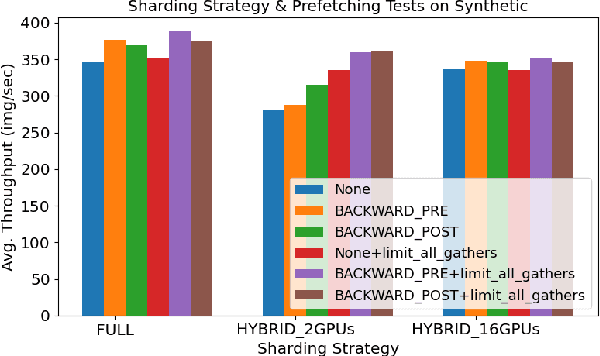
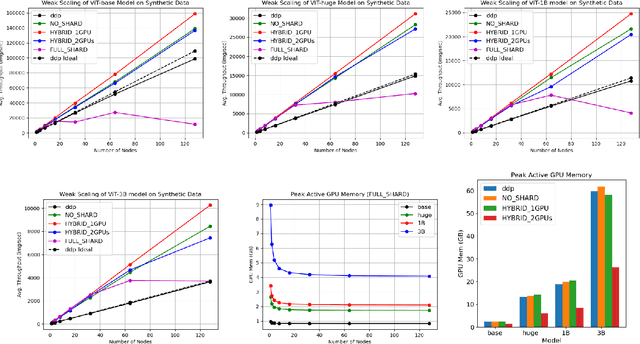
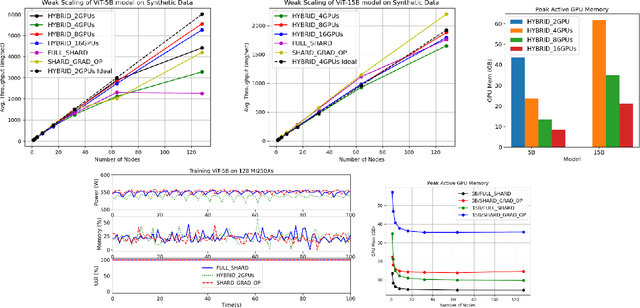
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.
The Case for Co-Designing Model Architectures with Hardware
Jan 30, 2024



While GPUs are responsible for training the vast majority of state-of-the-art deep learning models, the implications of their architecture are often overlooked when designing new deep learning (DL) models. As a consequence, modifying a DL model to be more amenable to the target hardware can significantly improve the runtime performance of DL training and inference. In this paper, we provide a set of guidelines for users to maximize the runtime performance of their transformer models. These guidelines have been created by carefully considering the impact of various model hyperparameters controlling model shape on the efficiency of the underlying computation kernels executed on the GPU. We find the throughput of models with efficient model shapes is up to 39\% higher while preserving accuracy compared to models with a similar number of parameters but with unoptimized shapes.
Optimizing Distributed Training on Frontier for Large Language Models
Dec 21, 2023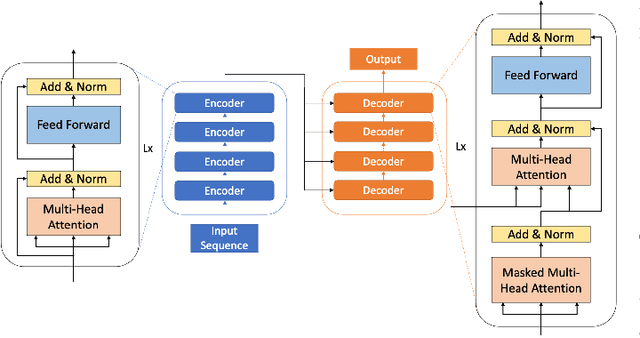
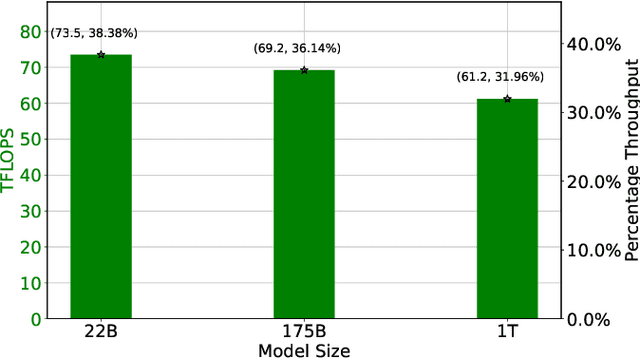
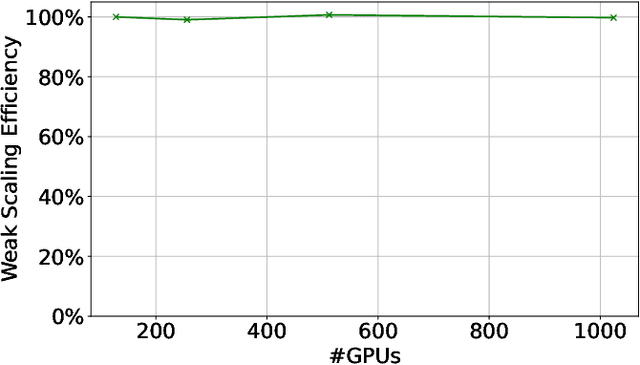
Large language models (LLMs) have demonstrated remarkable success as foundational models, benefiting various downstream applications through fine-tuning. Recent studies on loss scaling have demonstrated the superior performance of larger LLMs compared to their smaller counterparts. Nevertheless, training LLMs with billions of parameters poses significant challenges and requires considerable computational resources. For example, training a one trillion parameter GPT-style model on 20 trillion tokens requires a staggering 120 million exaflops of computation. This research explores efficient distributed training strategies to extract this computation from Frontier, the world's first exascale supercomputer dedicated to open science. We enable and investigate various model and data parallel training techniques, such as tensor parallelism, pipeline parallelism, and sharded data parallelism, to facilitate training a trillion-parameter model on Frontier. We empirically assess these techniques and their associated parameters to determine their impact on memory footprint, communication latency, and GPU's computational efficiency. We analyze the complex interplay among these techniques and find a strategy to combine them to achieve high throughput through hyperparameter tuning. We have identified efficient strategies for training large LLMs of varying sizes through empirical analysis and hyperparameter tuning. For 22 Billion, 175 Billion, and 1 Trillion parameters, we achieved GPU throughputs of $38.38\%$, $36.14\%$, and $31.96\%$, respectively. For the training of the 175 Billion parameter model and the 1 Trillion parameter model, we achieved $100\%$ weak scaling efficiency on 1024 and 3072 MI250X GPUs, respectively. We also achieved strong scaling efficiencies of $89\%$ and $87\%$ for these two models.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.