 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention
Sep 29, 2023



Most of the existing multi-modal models, hindered by their incapacity to adeptly manage interleaved image-and-text inputs in multi-image, multi-round dialogues, face substantial constraints in resource allocation for training and data accessibility, impacting their adaptability and scalability across varied interaction realms. To address this, we present the DeepSpeed-VisualChat framework, designed to optimize Large Language Models (LLMs) by incorporating multi-modal capabilities, with a focus on enhancing the proficiency of Large Vision and Language Models in handling interleaved inputs. Our framework is notable for (1) its open-source support for multi-round and multi-image dialogues, (2) introducing an innovative multi-modal causal attention mechanism, and (3) utilizing data blending techniques on existing datasets to assure seamless interactions in multi-round, multi-image conversations. Compared to existing frameworks, DeepSpeed-VisualChat shows superior scalability up to 70B parameter language model size, representing a significant advancement in multi-modal language models and setting a solid foundation for future explorations.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023
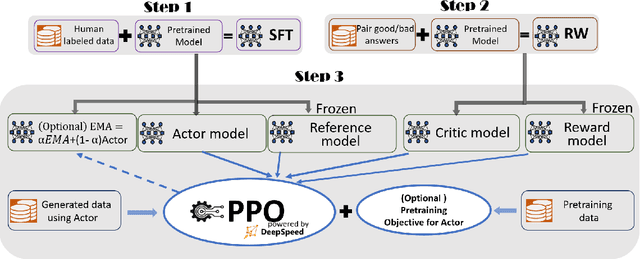

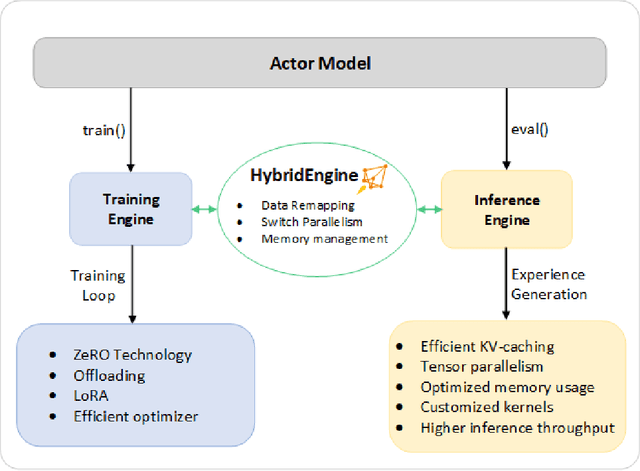
ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.
DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing
Dec 07, 2022



Recent advances on deep learning models come at the price of formidable training cost. The increasing model size is one of the root cause, but another less-emphasized fact is that data scale is actually increasing at a similar speed as model scale, and the training cost is proportional to both of them. Compared to the rapidly evolving model architecture, how to efficiently use the training data (especially for the expensive foundation model pertaining) is both less explored and difficult to realize due to the lack of a convenient framework that focus on data efficiency capabilities. To this end, we present DeepSpeed Data Efficiency library, a framework that makes better use of data, increases training efficiency, and improves model quality. Specifically, it provides efficient data sampling via curriculum learning, and efficient data routing via random layerwise token dropping. DeepSpeed Data Efficiency takes extensibility, flexibility and composability into consideration, so that users can easily utilize the framework to compose multiple techniques and apply customized strategies. By applying our solution to GPT-3 1.3B and BERT-Large language model pretraining, we can achieve similar model quality with up to 2x less data and 2x less time, or achieve better model quality under similar amount of data and time.
Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers
Nov 17, 2022

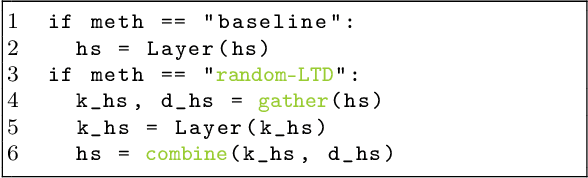
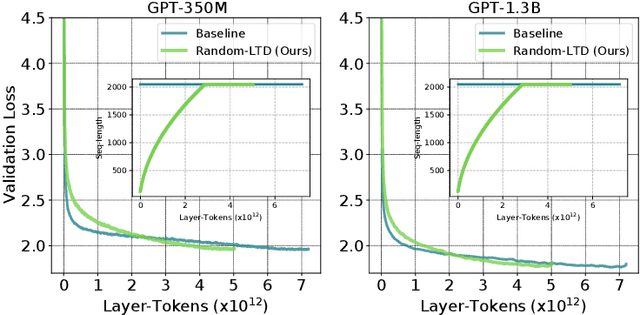
Large-scale transformer models have become the de-facto architectures for various machine learning applications, e.g., CV and NLP. However, those large models also introduce prohibitive training costs. To mitigate this issue, we propose a novel random and layerwise token dropping method (random-LTD), which skips the computation of a subset of the input tokens at all middle layers. Particularly, random-LTD achieves considerable speedups and comparable accuracy as the standard training baseline. Compared to other token dropping methods, random-LTD does not require (1) any importance score-based metrics, (2) any special token treatment (e.g., [CLS]), and (3) many layers in full sequence length training except the first and the last layers. Besides, a new LayerToken learning rate schedule is proposed for pretraining problems that resolve the heavy tuning requirement for our proposed training mechanism. Finally, we demonstrate that random-LTD can be applied to broader applications, including GPT and BERT pretraining as well as ViT and GPT finetuning tasks. Our results show that random-LTD can save about 33.3% theoretical compute cost and 25.6% wall-clock training time while achieving similar zero-shot evaluations on GPT-31.3B as compared to baseline.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
Jun 04, 2022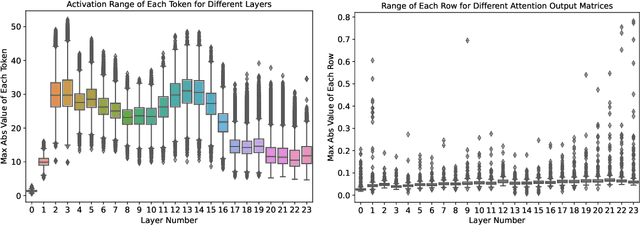



How to efficiently serve ever-larger trained natural language models in practice has become exceptionally challenging even for powerful cloud servers due to their prohibitive memory/computation requirements. In this work, we present an efficient and affordable post-training quantization approach to compress large Transformer-based models, termed as ZeroQuant. ZeroQuant is an end-to-end quantization and inference pipeline with three main components: (1) a fine-grained hardware-friendly quantization scheme for both weight and activations; (2) a novel affordable layer-by-layer knowledge distillation algorithm (LKD) even without the access to the original training data; (3) a highly-optimized quantization system backend support to remove the quantization/dequantization overhead. As such, we are able to show that: (1) ZeroQuant can reduce the precision for weights and activations to INT8 in a cost-free way for both BERT and GPT3-style models with minimal accuracy impact, which leads to up to 5.19x/4.16x speedup on those models compared to FP16 inference; (2) ZeroQuant plus LKD affordably quantize the weights in the fully-connected module to INT4 along with INT8 weights in the attention module and INT8 activations, resulting in 3x memory footprint reduction compared to the FP16 model; (3) ZeroQuant can be directly applied to two of the largest open-sourced language models, including GPT-J6B and GPT-NeoX20, for which our INT8 model achieves similar accuracy as the FP16 model but achieves up to 5.2x better efficiency.
Extreme Compression for Pre-trained Transformers Made Simple and Efficient
Jun 04, 2022

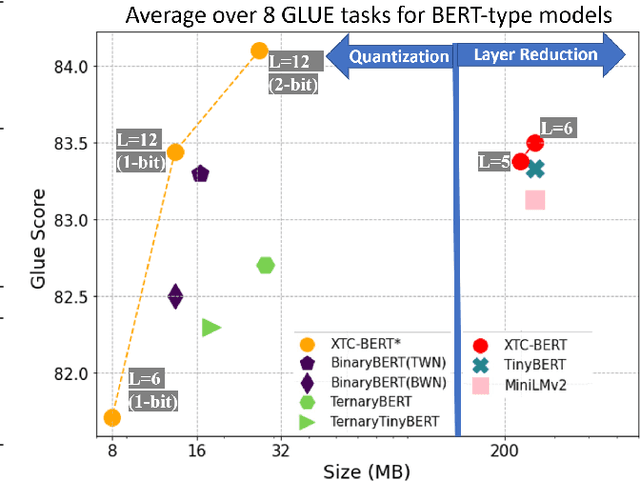

Extreme compression, particularly ultra-low bit precision (binary/ternary) quantization, has been proposed to fit large NLP models on resource-constraint devices. However, to preserve the accuracy for such aggressive compression schemes, cutting-edge methods usually introduce complicated compression pipelines, e.g., multi-stage expensive knowledge distillation with extensive hyperparameter tuning. Also, they oftentimes focus less on smaller transformer models that have already been heavily compressed via knowledge distillation and lack a systematic study to show the effectiveness of their methods. In this paper, we perform a very comprehensive systematic study to measure the impact of many key hyperparameters and training strategies from previous works. As a result, we find out that previous baselines for ultra-low bit precision quantization are significantly under-trained. Based on our study, we propose a simple yet effective compression pipeline for extreme compression, named XTC. XTC demonstrates that (1) we can skip the pre-training knowledge distillation to obtain a 5-layer BERT while achieving better performance than previous state-of-the-art methods, e.g., the 6-layer TinyBERT; (2) extreme quantization plus layer reduction is able to reduce the model size by 50x, resulting in new state-of-the-art results on GLUE tasks.
Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
Feb 12, 2022



1-bit communication is an effective method to scale up model training, and has been studied extensively on SGD. Its benefits, however, remain an open question on Adam-based model training (e.g. BERT and GPT). In this paper, we propose 0/1 Adam, which improves upon the state-of-the-art 1-bit Adam via two novel designs: (1) adaptive variance state freezing, which eliminates the requirement of running expensive full-precision communication at early stage of training; (2) 1-bit sync, which allows skipping communication rounds with bit-free synchronization over Adam's optimizer states, momentum and variance. In theory, we provide convergence analysis for 0/1 Adam on smooth non-convex objectives, and show the complexity bound is better than original Adam under certain conditions. On various benchmarks such as BERT-Base/Large pretraining and ImageNet, we demonstrate on up to 128 GPUs that 0/1 Adam is able to reduce up to 90% of data volume, 54% of communication rounds, and achieve up to 2X higher throughput compared to the state-of-the-art 1-bit Adam while enjoying the same statistical convergence speed and end-to-end model accuracy on GLUE dataset and ImageNet validation set.