 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
Jan 09, 2024
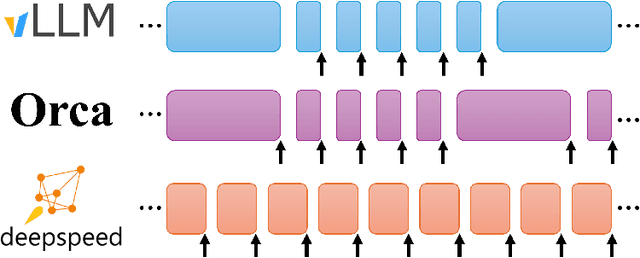
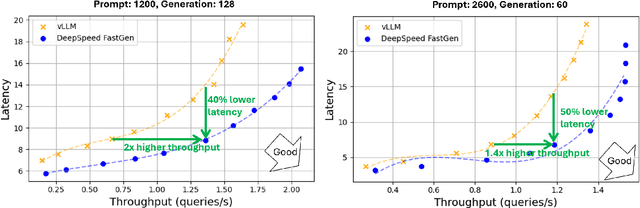
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention
Sep 29, 2023



Most of the existing multi-modal models, hindered by their incapacity to adeptly manage interleaved image-and-text inputs in multi-image, multi-round dialogues, face substantial constraints in resource allocation for training and data accessibility, impacting their adaptability and scalability across varied interaction realms. To address this, we present the DeepSpeed-VisualChat framework, designed to optimize Large Language Models (LLMs) by incorporating multi-modal capabilities, with a focus on enhancing the proficiency of Large Vision and Language Models in handling interleaved inputs. Our framework is notable for (1) its open-source support for multi-round and multi-image dialogues, (2) introducing an innovative multi-modal causal attention mechanism, and (3) utilizing data blending techniques on existing datasets to assure seamless interactions in multi-round, multi-image conversations. Compared to existing frameworks, DeepSpeed-VisualChat shows superior scalability up to 70B parameter language model size, representing a significant advancement in multi-modal language models and setting a solid foundation for future explorations.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023
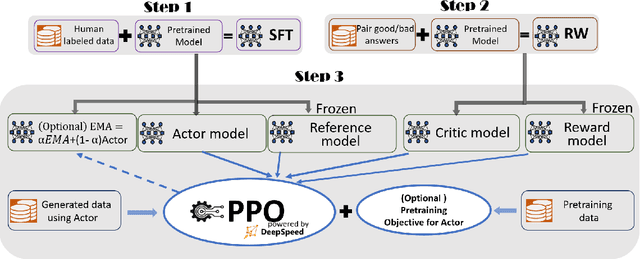

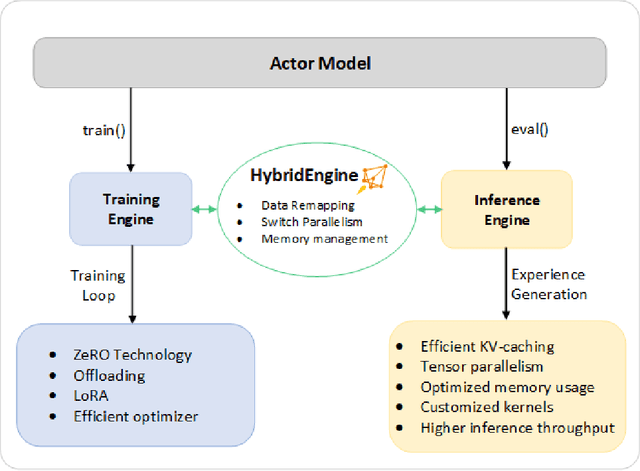
ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.
ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
Jun 16, 2023



Zero Redundancy Optimizer (ZeRO) has been used to train a wide range of large language models on massive GPUs clusters due to its ease of use, efficiency, and good scalability. However, when training on low-bandwidth clusters, or at scale which forces batch size per GPU to be small, ZeRO's effective throughput is limited because of high communication volume from gathering weights in forward pass, backward pass, and averaging gradients. This paper introduces three communication volume reduction techniques, which we collectively refer to as ZeRO++, targeting each of the communication collectives in ZeRO. First is block-quantization based all-gather. Second is data remapping that trades-off communication for more memory. Third is a novel all-to-all based quantized gradient averaging paradigm as replacement of reduce-scatter collective, which preserves accuracy despite communicating low precision data. Collectively, ZeRO++ reduces communication volume of ZeRO by 4x, enabling up to 2.16x better throughput at 384 GPU scale.
The Age of Correlated Features in Supervised Learning based Forecasting
Feb 27, 2021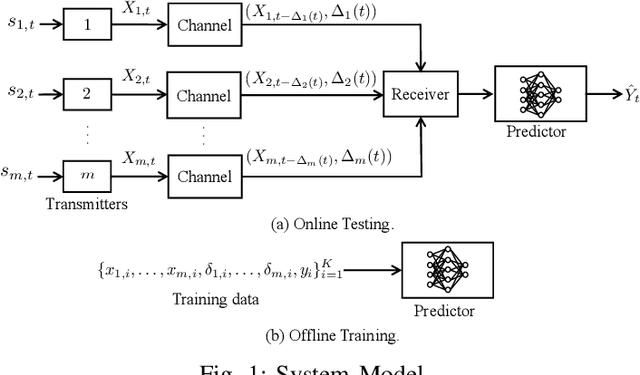
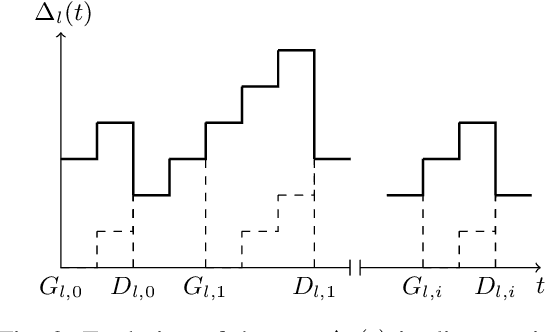
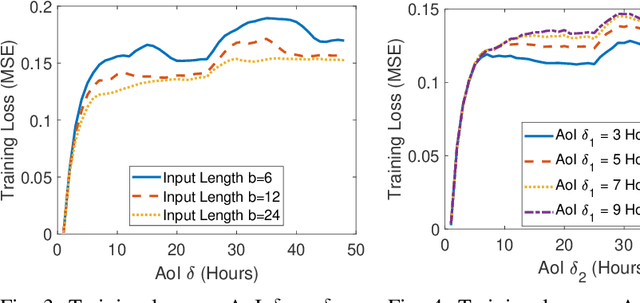
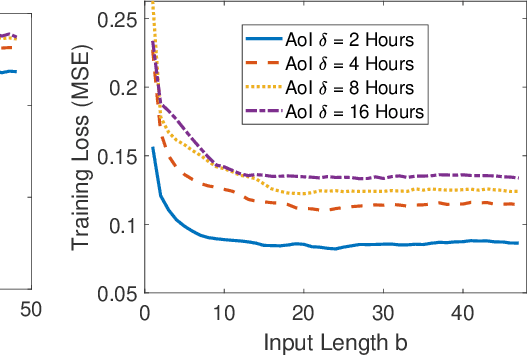
In this paper, we analyze the impact of information freshness on supervised learning based forecasting. In these applications, a neural network is trained to predict a time-varying target (e.g., solar power), based on multiple correlated features (e.g., temperature, humidity, and cloud coverage). The features are collected from different data sources and are subject to heterogeneous and time-varying ages. By using an information-theoretic approach, we prove that the minimum training loss is a function of the ages of the features, where the function is not always monotonic. However, if the empirical distribution of the training data is close to the distribution of a Markov chain, then the training loss is approximately a non-decreasing age function. Both the training loss and testing loss depict similar growth patterns as the age increases. An experiment on solar power prediction is conducted to validate our theory. Our theoretical and experimental results suggest that it is beneficial to (i) combine the training data with different age values into a large training dataset and jointly train the forecasting decisions for these age values, and (ii) feed the age value as a part of the input feature to the neural network.