 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Bidirectional Causal Effects with Large Scale Online Kernel Learning
Nov 07, 2025In this study, a scalable online kernel learning framework is proposed for estimating bidirectional causal effects in systems characterized by mutual dependence and heteroskedasticity. Traditional causal inference often focuses on unidirectional effects, overlooking the common bidirectional relationships in real-world phenomena. Building on heteroskedasticity-based identification, the proposed method integrates a quasi-maximum likelihood estimator for simultaneous equation models with large scale online kernel learning. It employs random Fourier feature approximations to flexibly model nonlinear conditional means and variances, while an adaptive online gradient descent algorithm ensures computational efficiency for streaming and high-dimensional data. Results from extensive simulations demonstrate that the proposed method achieves superior accuracy and stability than single equation and polynomial approximation baselines, exhibiting lower bias and root mean squared error across various data-generating processes. These results confirm that the proposed approach effectively captures complex bidirectional causal effects with near-linear computational scaling. By combining econometric identification with modern machine learning techniques, the proposed framework offers a practical, scalable, and theoretically grounded solution for large scale causal inference in natural/social science, policy making, business, and industrial applications.
GRIN: GRadient-INformed MoE
Sep 18, 2024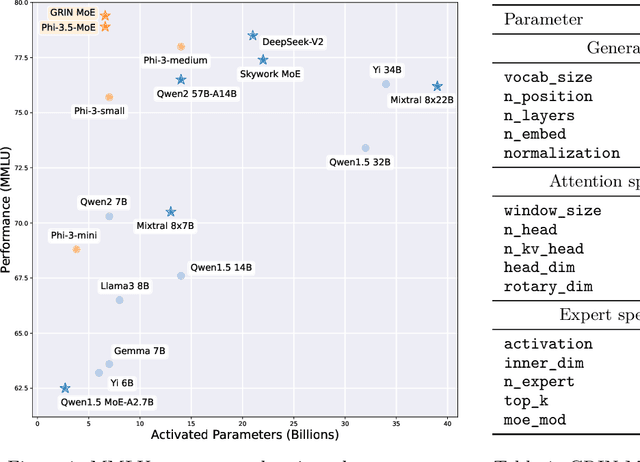
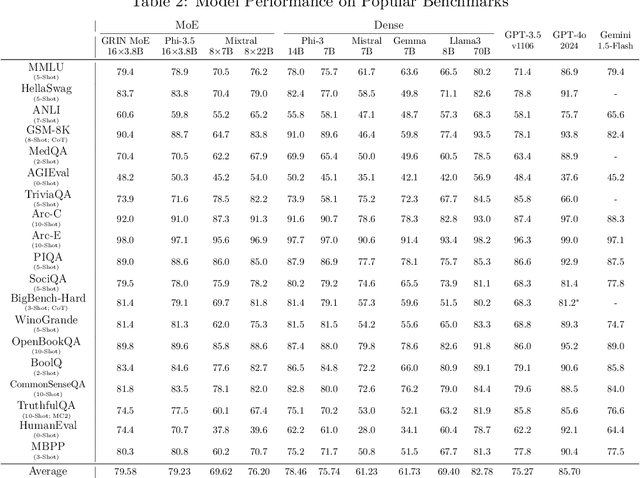
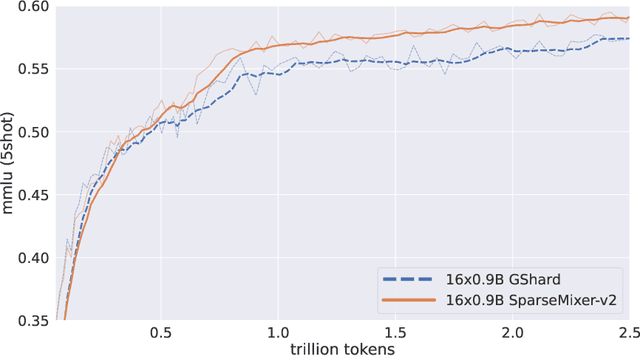

Mixture-of-Experts (MoE) models scale more effectively than dense models due to sparse computation through expert routing, selectively activating only a small subset of expert modules. However, sparse computation challenges traditional training practices, as discrete expert routing hinders standard backpropagation and thus gradient-based optimization, which are the cornerstone of deep learning. To better pursue the scaling power of MoE, we introduce GRIN (GRadient-INformed MoE training), which incorporates sparse gradient estimation for expert routing and configures model parallelism to avoid token dropping. Applying GRIN to autoregressive language modeling, we develop a top-2 16$\times$3.8B MoE model. Our model, with only 6.6B activated parameters, outperforms a 7B dense model and matches the performance of a 14B dense model trained on the same data. Extensive evaluations across diverse tasks demonstrate the potential of GRIN to significantly enhance MoE efficacy, achieving 79.4 on MMLU, 83.7 on HellaSwag, 74.4 on HumanEval, and 58.9 on MATH.
Training Ultra Long Context Language Model with Fully Pipelined Distributed Transformer
Aug 30, 2024
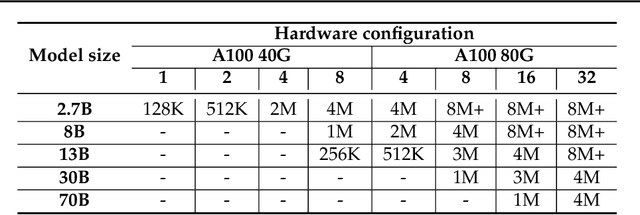
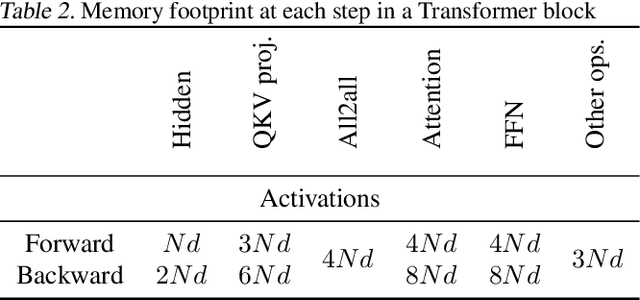

Large Language Models (LLMs) with long context capabilities are integral to complex tasks in natural language processing and computational biology, such as text generation and protein sequence analysis. However, training LLMs directly on extremely long contexts demands considerable GPU resources and increased memory, leading to higher costs and greater complexity. Alternative approaches that introduce long context capabilities via downstream finetuning or adaptations impose significant design limitations. In this paper, we propose Fully Pipelined Distributed Transformer (FPDT) for efficiently training long-context LLMs with extreme hardware efficiency. For GPT and Llama models, we achieve a 16x increase in sequence length that can be trained on the same hardware compared to current state-of-the-art solutions. With our dedicated sequence chunk pipeline design, we can now train 8B LLM with 2 million sequence length on only 4 GPUs, while also maintaining over 55% of MFU. Our proposed FPDT is agnostic to existing training techniques and is proven to work efficiently across different LLM models.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Universal Checkpointing: Efficient and Flexible Checkpointing for Large Scale Distributed Training
Jun 27, 2024



Existing checkpointing approaches seem ill-suited for distributed training even though hardware limitations make model parallelism, i.e., sharding model state across multiple accelerators, a requirement for model scaling. Consolidating distributed model state into a single checkpoint unacceptably slows down training, and is impractical at extreme scales. Distributed checkpoints, in contrast, are tightly coupled to the model parallelism and hardware configurations of the training run, and thus unusable on different configurations. To address this problem, we propose Universal Checkpointing, a technique that enables efficient checkpoint creation while providing the flexibility of resuming on arbitrary parallelism strategy and hardware configurations. Universal Checkpointing unlocks unprecedented capabilities for large-scale training such as improved resilience to hardware failures through continued training on remaining healthy hardware, and reduced training time through opportunistic exploitation of elastic capacity. The key insight of Universal Checkpointing is the selection of the optimal representation in each phase of the checkpointing life cycle: distributed representation for saving, and consolidated representation for loading. This is achieved using two key mechanisms. First, the universal checkpoint format, which consists of a consolidated representation of each model parameter and metadata for mapping parameter fragments into training ranks of arbitrary model-parallelism configuration. Second, the universal checkpoint language, a simple but powerful specification language for converting distributed checkpoints into the universal checkpoint format. Our evaluation demonstrates the effectiveness and generality of Universal Checkpointing on state-of-the-art model architectures and a wide range of parallelism techniques.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference
Jan 09, 2024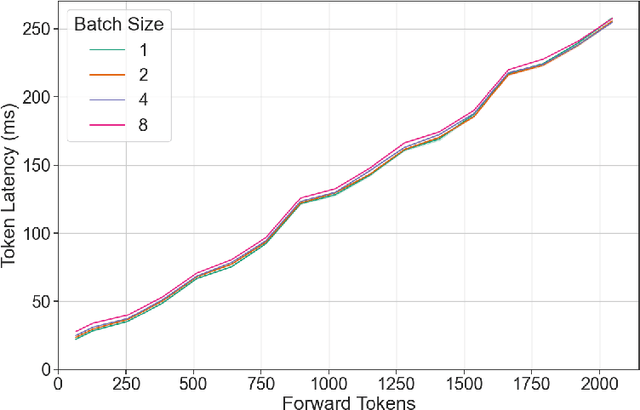
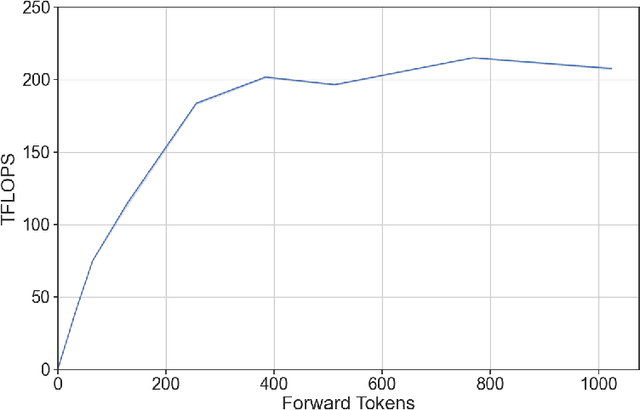
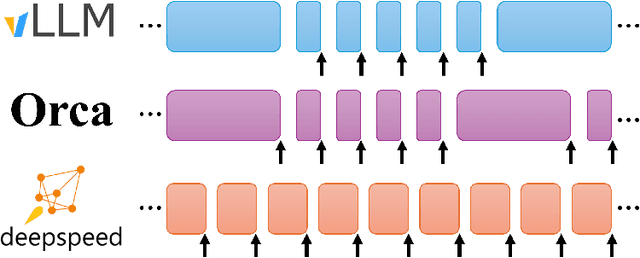
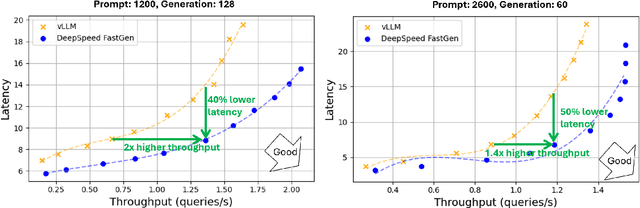
The deployment and scaling of large language models (LLMs) have become critical as they permeate various applications, demanding high-throughput and low-latency serving systems. Existing frameworks struggle to balance these requirements, especially for workloads with long prompts. This paper introduces DeepSpeed-FastGen, a system that employs Dynamic SplitFuse, a novel prompt and generation composition strategy, to deliver up to 2.3x higher effective throughput, 2x lower latency on average, and up to 3.7x lower (token-level) tail latency, compared to state-of-the-art systems like vLLM. We leverage a synergistic combination of DeepSpeed-MII and DeepSpeed-Inference to provide an efficient and easy-to-use serving system for LLMs. DeepSpeed-FastGen's advanced implementation supports a range of models and offers both non-persistent and persistent deployment options, catering to diverse user scenarios from interactive sessions to long-running applications. We present a detailed benchmarking methodology, analyze the performance through latency-throughput curves, and investigate scalability via load balancing. Our evaluations demonstrate substantial improvements in throughput and latency across various models and hardware configurations. We discuss our roadmap for future enhancements, including broader model support and new hardware backends. The DeepSpeed-FastGen code is readily available for community engagement and contribution.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
Sep 25, 2023



Computation in a typical Transformer-based large language model (LLM) can be characterized by batch size, hidden dimension, number of layers, and sequence length. Until now, system works for accelerating LLM training have focused on the first three dimensions: data parallelism for batch size, tensor parallelism for hidden size and pipeline parallelism for model depth or layers. These widely studied forms of parallelism are not targeted or optimized for long sequence Transformer models. Given practical application needs for long sequence LLM, renewed attentions are being drawn to sequence parallelism. However, existing works in sequence parallelism are constrained by memory-communication inefficiency, limiting their scalability to long sequence large models. In this work, we introduce DeepSpeed-Ulysses, a novel, portable and effective methodology for enabling highly efficient and scalable LLM training with extremely long sequence length. DeepSpeed-Ulysses at its core partitions input data along the sequence dimension and employs an efficient all-to-all collective communication for attention computation. Theoretical communication analysis shows that whereas other methods incur communication overhead as sequence length increases, DeepSpeed-Ulysses maintains constant communication volume when sequence length and compute devices are increased proportionally. Furthermore, experimental evaluations show that DeepSpeed-Ulysses trains 2.5X faster with 4X longer sequence length than the existing method SOTA baseline.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023
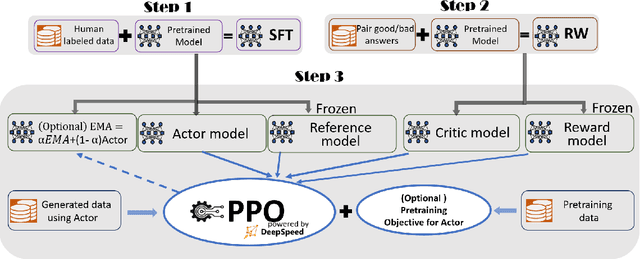

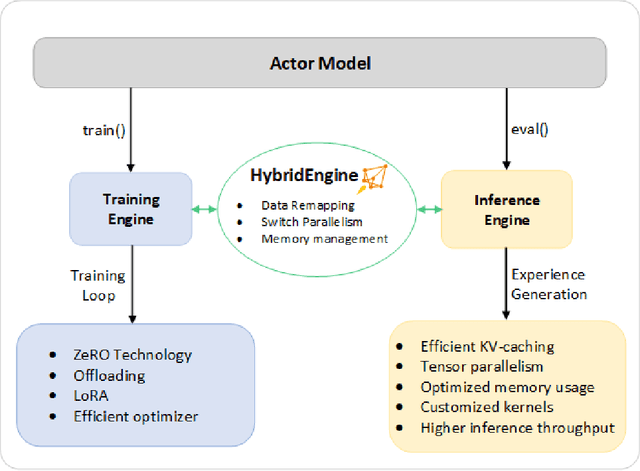
ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.