 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025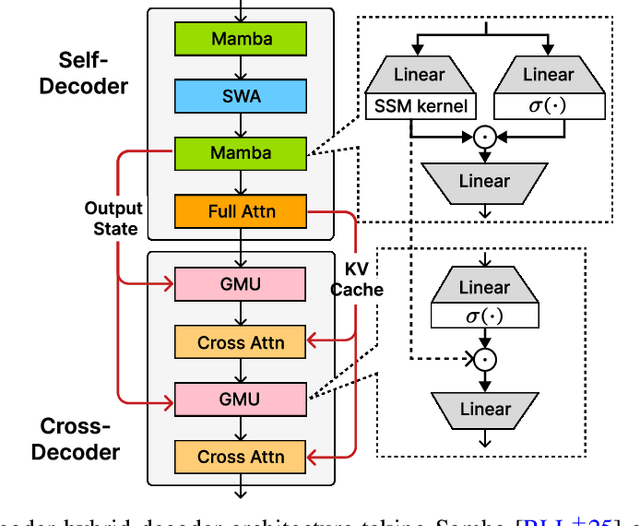
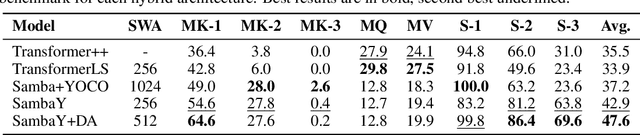
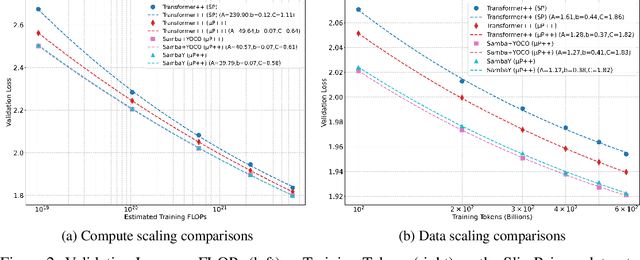
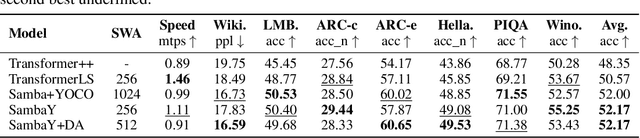
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025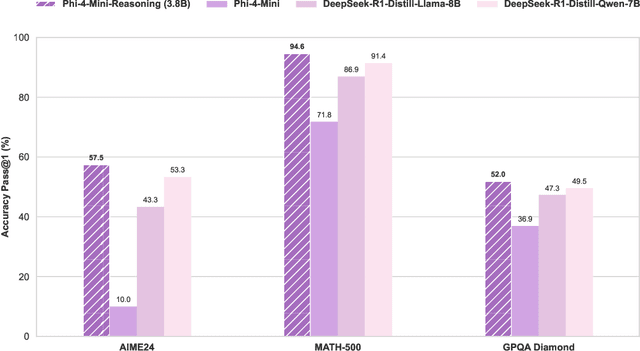
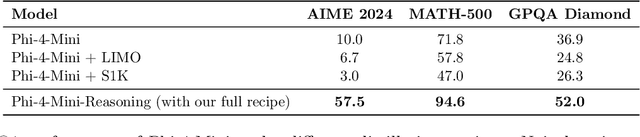

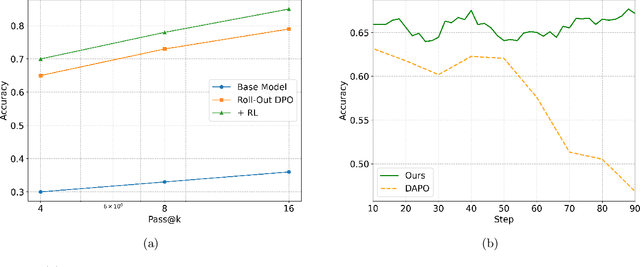
Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
GRIN: GRadient-INformed MoE
Sep 18, 2024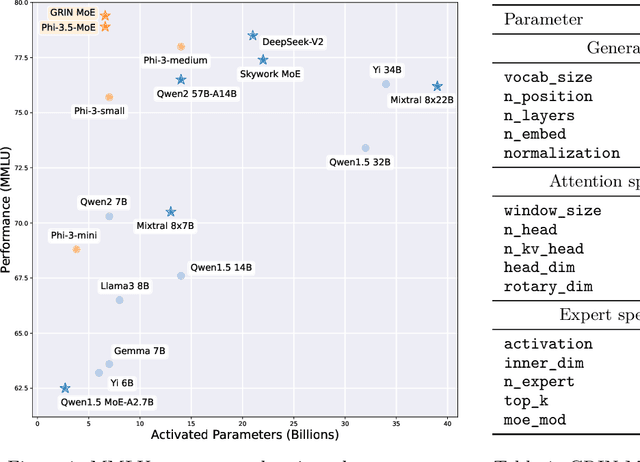
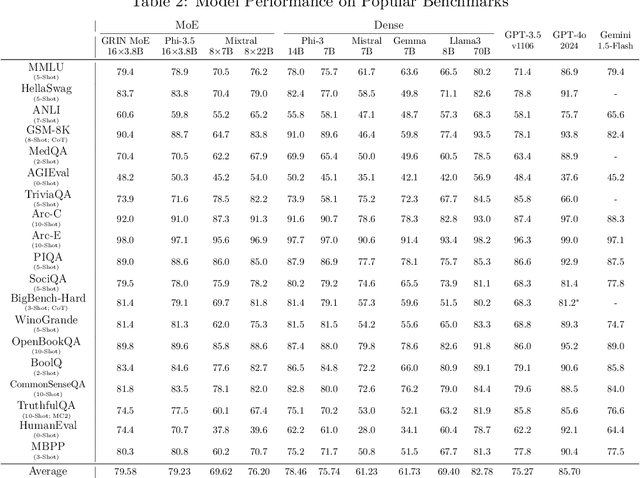
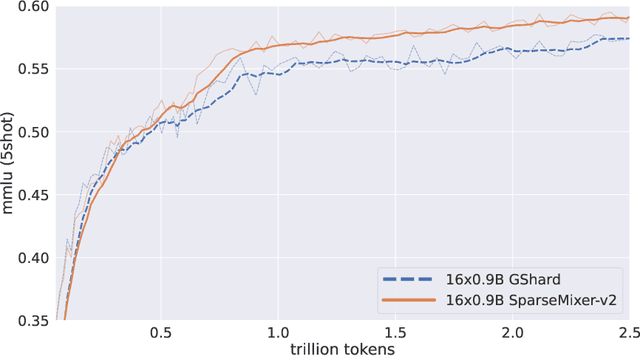

Mixture-of-Experts (MoE) models scale more effectively than dense models due to sparse computation through expert routing, selectively activating only a small subset of expert modules. However, sparse computation challenges traditional training practices, as discrete expert routing hinders standard backpropagation and thus gradient-based optimization, which are the cornerstone of deep learning. To better pursue the scaling power of MoE, we introduce GRIN (GRadient-INformed MoE training), which incorporates sparse gradient estimation for expert routing and configures model parallelism to avoid token dropping. Applying GRIN to autoregressive language modeling, we develop a top-2 16$\times$3.8B MoE model. Our model, with only 6.6B activated parameters, outperforms a 7B dense model and matches the performance of a 14B dense model trained on the same data. Extensive evaluations across diverse tasks demonstrate the potential of GRIN to significantly enhance MoE efficacy, achieving 79.4 on MMLU, 83.7 on HellaSwag, 74.4 on HumanEval, and 58.9 on MATH.
Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation
Feb 02, 2024



Moderate-sized large language models (LLMs) -- those with 7B or 13B parameters -- exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation models, like ALMA, does not match the performance of state-of-the-art conventional encoder-decoder translation models or larger-scale LLMs such as GPT-4. In this study, we bridge this performance gap. We first assess the shortcomings of supervised fine-tuning for LLMs in the MT task, emphasizing the quality issues present in the reference data, despite being human-generated. Then, in contrast to SFT which mimics reference translations, we introduce Contrastive Preference Optimization (CPO), a novel approach that trains models to avoid generating adequate but not perfect translations. Applying CPO to ALMA models with only 22K parallel sentences and 12M parameters yields significant improvements. The resulting model, called ALMA-R, can match or exceed the performance of the WMT competition winners and GPT-4 on WMT'21, WMT'22 and WMT'23 test datasets.
PEMA: Plug-in External Memory Adaptation for Language Models
Nov 14, 2023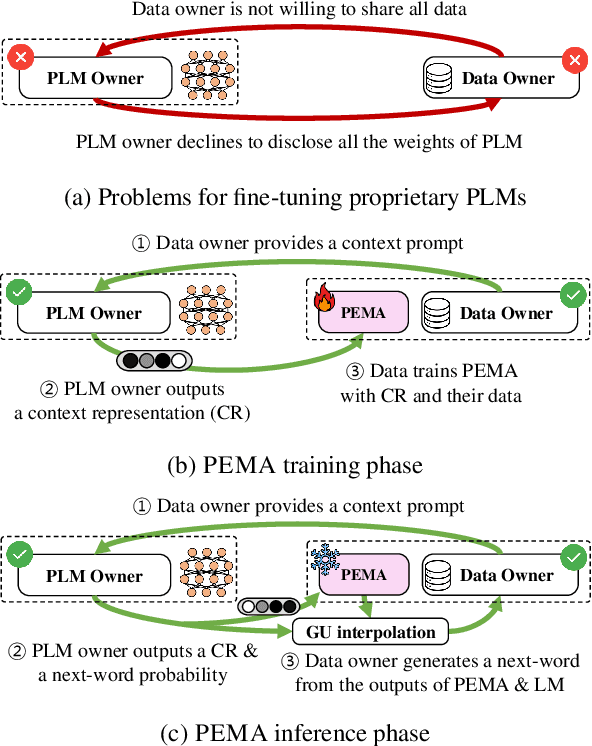
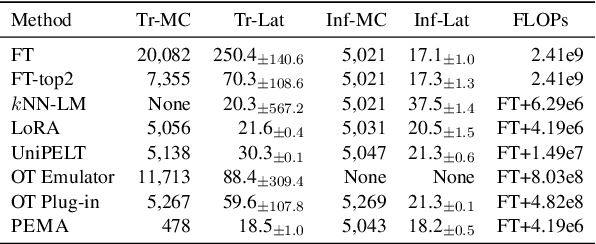
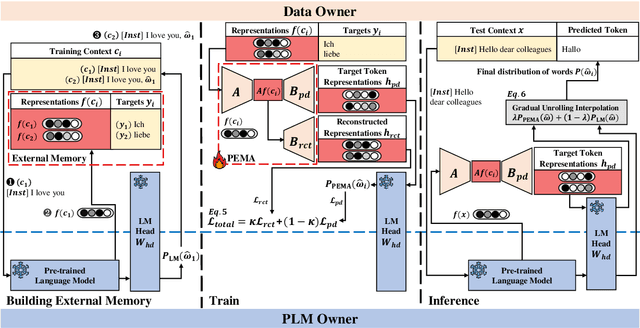
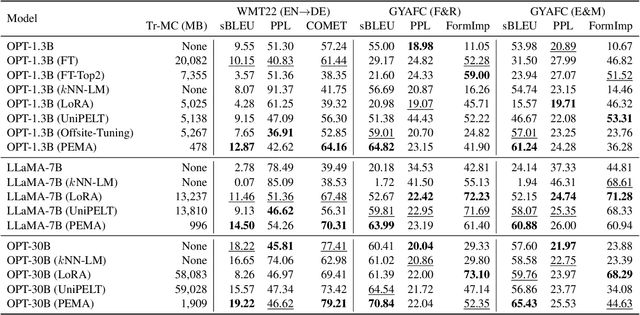
Pre-trained language models (PLMs) have demonstrated impressive performance across various downstream NLP tasks. Nevertheless, the resource requirements of pre-training large language models in terms of memory and training compute pose significant challenges. Furthermore, due to the substantial resources required, many PLM weights are confidential. Consequently, users are compelled to share their data with model owners for fine-tuning on specific tasks. To overcome the limitations, we introduce Plug-in External Memory Adaptation (PEMA), a Parameter-Efficient Fine-Tuning (PEFT) approach designed for fine-tuning PLMs without the need for all weights. PEMA can be integrated into the context representation of test data during inference to execute downstream tasks. It leverages an external memory to store context representations generated by a PLM, mapped with the desired target word. Our method entails training LoRA-based weight matrices within the final layer of the PLM for enhanced efficiency. The probability is then interpolated with the next-word distribution from the PLM to perform downstream tasks. To improve the generation quality, we propose a novel interpolation strategy named Gradual Unrolling. To demonstrate the effectiveness of our proposed method, we conduct experiments to demonstrate the efficacy of PEMA with a syntactic dataset and assess its performance on machine translation and style transfer tasks using real datasets. PEMA outperforms other PEFT methods in terms of memory and latency efficiency for training and inference. Furthermore, it outperforms other baselines in preserving the meaning of sentences while generating appropriate language and styles.
Mixture of Quantized Experts (MoQE): Complementary Effect of Low-bit Quantization and Robustness
Oct 03, 2023

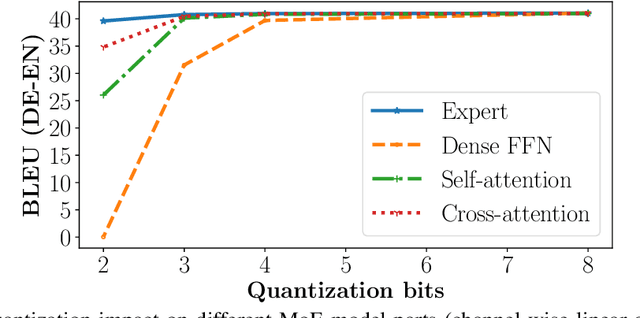

Large Mixture of Experts (MoE) models could achieve state-of-the-art quality on various language tasks, including machine translation task, thanks to the efficient model scaling capability with expert parallelism. However, it has brought a fundamental issue of larger memory consumption and increased memory bandwidth bottleneck at deployment time. In this paper, we propose Mixture of Quantized Experts (MoQE) which is a simple weight-only quantization method applying ultra low-bit down to 2-bit quantizations only to expert weights for mitigating the increased memory and latency issues of MoE models. We show that low-bit quantization together with the MoE architecture delivers a reliable model performance while reducing the memory size significantly even without any additional training in most cases. In particular, expert layers in MoE models are much more robust to the quantization than conventional feedforward networks (FFN) layers. In our comprehensive analysis, we show that MoE models with 2-bit expert weights can deliver better model performance than the dense model trained on the same dataset. As a result of low-bit quantization, we show the model size can be reduced by 79.6% of the original half precision floating point (fp16) MoE model. Combined with an optimized GPU runtime implementation, it also achieves 1.24X speed-up on A100 GPUs.
A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models
Sep 20, 2023Generative Large Language Models (LLMs) have achieved remarkable advancements in various NLP tasks. However, these advances have not been reflected in the translation task, especially those with moderate model sizes (i.e., 7B or 13B parameters), which still lag behind conventional supervised encoder-decoder translation models. Previous studies have attempted to improve the translation capabilities of these moderate LLMs, but their gains have been limited. In this study, we propose a novel fine-tuning approach for LLMs that is specifically designed for the translation task, eliminating the need for the abundant parallel data that traditional translation models usually depend on. Our approach consists of two fine-tuning stages: initial fine-tuning on monolingual data followed by subsequent fine-tuning on a small set of high-quality parallel data. We introduce the LLM developed through this strategy as Advanced Language Model-based trAnslator (ALMA). Based on LLaMA-2 as our underlying model, our results show that the model can achieve an average improvement of more than 12 BLEU and 12 COMET over its zero-shot performance across 10 translation directions from the WMT'21 (2 directions) and WMT'22 (8 directions) test datasets. The performance is significantly better than all prior work and even superior to the NLLB-54B model and GPT-3.5-text-davinci-003, with only 7B or 13B parameters. This method establishes the foundation for a novel training paradigm in machine translation.
Task-Based MoE for Multitask Multilingual Machine Translation
Sep 11, 2023Mixture-of-experts (MoE) architecture has been proven a powerful method for diverse tasks in training deep models in many applications. However, current MoE implementations are task agnostic, treating all tokens from different tasks in the same manner. In this work, we instead design a novel method that incorporates task information into MoE models at different granular levels with shared dynamic task-based adapters. Our experiments and analysis show the advantages of our approaches over the dense and canonical MoE models on multi-task multilingual machine translations. With task-specific adapters, our models can additionally generalize to new tasks efficiently.
FineQuant: Unlocking Efficiency with Fine-Grained Weight-Only Quantization for LLMs
Aug 16, 2023Large Language Models (LLMs) have achieved state-of-the-art performance across various language tasks but pose challenges for practical deployment due to their substantial memory requirements. Furthermore, the latest generative models suffer from high inference costs caused by the memory bandwidth bottleneck in the auto-regressive decoding process. To address these issues, we propose an efficient weight-only quantization method that reduces memory consumption and accelerates inference for LLMs. To ensure minimal quality degradation, we introduce a simple and effective heuristic approach that utilizes only the model weights of a pre-trained model. This approach is applicable to both Mixture-of-Experts (MoE) and dense models without requiring additional fine-tuning. To demonstrate the effectiveness of our proposed method, we first analyze the challenges and issues associated with LLM quantization. Subsequently, we present our heuristic approach, which adaptively finds the granularity of quantization, effectively addressing these problems. Furthermore, we implement highly efficient GPU GEMMs that perform on-the-fly matrix multiplication and dequantization, supporting the multiplication of fp16 or bf16 activations with int8 or int4 weights. We evaluate our approach on large-scale open source models such as OPT-175B and internal MoE models, showcasing minimal accuracy loss while achieving up to 3.65 times higher throughput on the same number of GPUs.