 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on Superalignment Should Advance Now with Parallel Optimization of Competence and Conformity
Mar 08, 2025The recent leap in AI capabilities, driven by big generative models, has sparked the possibility of achieving Artificial General Intelligence (AGI) and further triggered discussions on Artificial Superintelligence (ASI), a system surpassing all humans across all domains. This gives rise to the critical research question of: If we realize ASI, how do we align it with human values, ensuring it benefits rather than harms human society, a.k.a., the Superalignment problem. Despite ASI being regarded by many as solely a hypothetical concept, in this paper, we argue that superalignment is achievable and research on it should advance immediately, through simultaneous and alternating optimization of task competence and value conformity. We posit that superalignment is not merely a safeguard for ASI but also necessary for its realization. To support this position, we first provide a formal definition of superalignment rooted in the gap between capability and capacity and elaborate on our argument. Then we review existing paradigms, explore their interconnections and limitations, and illustrate a potential path to superalignment centered on two fundamental principles. We hope this work sheds light on a practical approach for developing the value-aligned next-generation AI, garnering greater benefits and reducing potential harms for humanity.
The Road to Artificial SuperIntelligence: A Comprehensive Survey of Superalignment
Dec 24, 2024



The emergence of large language models (LLMs) has sparked the possibility of about Artificial Superintelligence (ASI), a hypothetical AI system surpassing human intelligence. However, existing alignment paradigms struggle to guide such advanced AI systems. Superalignment, the alignment of AI systems with human values and safety requirements at superhuman levels of capability aims to addresses two primary goals -- scalability in supervision to provide high-quality guidance signals and robust governance to ensure alignment with human values. In this survey, we examine scalable oversight methods and potential solutions for superalignment. Specifically, we explore the concept of ASI, the challenges it poses, and the limitations of current alignment paradigms in addressing the superalignment problem. Then we review scalable oversight methods for superalignment. Finally, we discuss the key challenges and propose pathways for the safe and continual improvement of ASI systems. By comprehensively reviewing the current literature, our goal is provide a systematical introduction of existing methods, analyze their strengths and limitations, and discuss potential future directions.
A Temporally Correlated Latent Exploration for Reinforcement Learning
Dec 06, 2024Efficient exploration remains one of the longstanding problems of deep reinforcement learning. Instead of depending solely on extrinsic rewards from the environments, existing methods use intrinsic rewards to enhance exploration. However, we demonstrate that these methods are vulnerable to Noisy TV and stochasticity. To tackle this problem, we propose Temporally Correlated Latent Exploration (TeCLE), which is a novel intrinsic reward formulation that employs an action-conditioned latent space and temporal correlation. The action-conditioned latent space estimates the probability distribution of states, thereby avoiding the assignment of excessive intrinsic rewards to unpredictable states and effectively addressing both problems. Whereas previous works inject temporal correlation for action selection, the proposed method injects it for intrinsic reward computation. We find that the injected temporal correlation determines the exploratory behaviors of agents. Various experiments show that the environment where the agent performs well depends on the amount of temporal correlation. To the best of our knowledge, the proposed TeCLE is the first approach to consider the action conditioned latent space and temporal correlation for curiosity-driven exploration. We prove that the proposed TeCLE can be robust to the Noisy TV and stochasticity in benchmark environments, including Minigrid and Stochastic Atari.
PEMA: Plug-in External Memory Adaptation for Language Models
Nov 14, 2023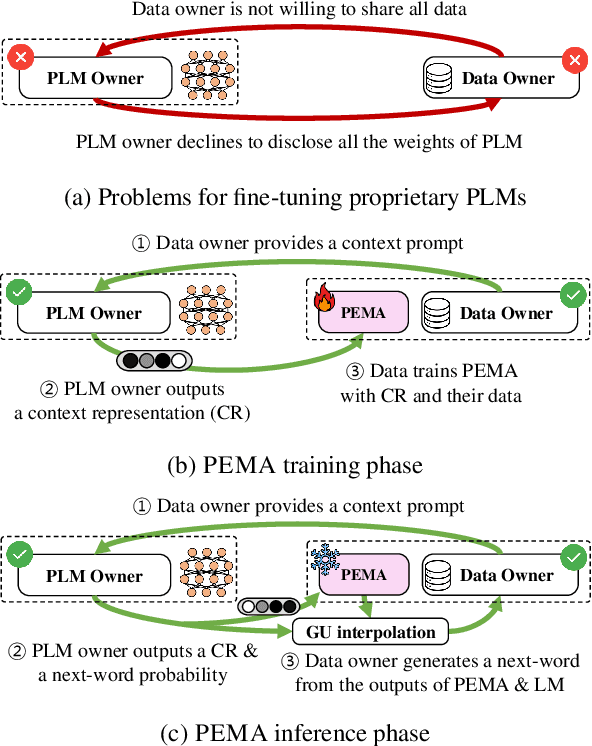
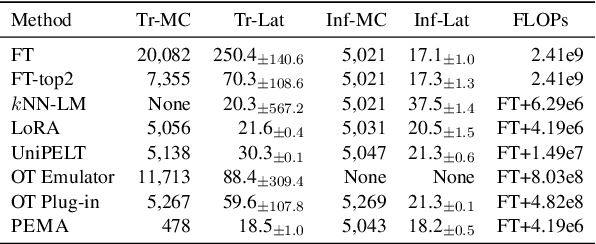
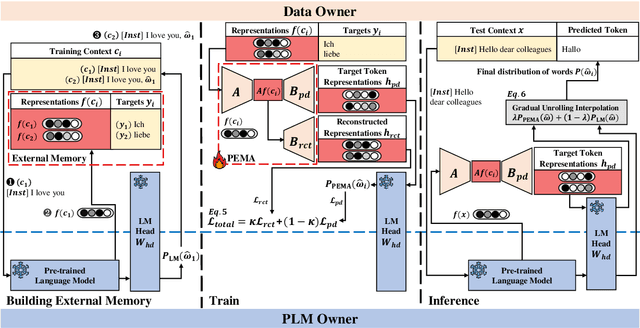
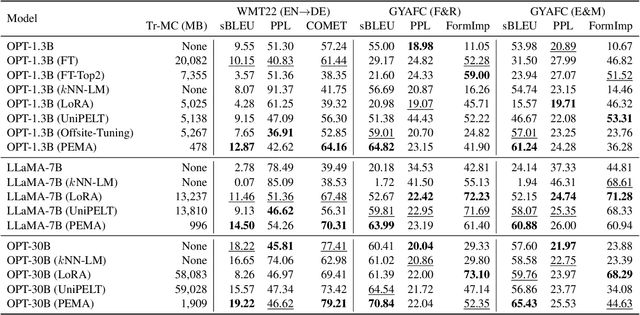
Pre-trained language models (PLMs) have demonstrated impressive performance across various downstream NLP tasks. Nevertheless, the resource requirements of pre-training large language models in terms of memory and training compute pose significant challenges. Furthermore, due to the substantial resources required, many PLM weights are confidential. Consequently, users are compelled to share their data with model owners for fine-tuning on specific tasks. To overcome the limitations, we introduce Plug-in External Memory Adaptation (PEMA), a Parameter-Efficient Fine-Tuning (PEFT) approach designed for fine-tuning PLMs without the need for all weights. PEMA can be integrated into the context representation of test data during inference to execute downstream tasks. It leverages an external memory to store context representations generated by a PLM, mapped with the desired target word. Our method entails training LoRA-based weight matrices within the final layer of the PLM for enhanced efficiency. The probability is then interpolated with the next-word distribution from the PLM to perform downstream tasks. To improve the generation quality, we propose a novel interpolation strategy named Gradual Unrolling. To demonstrate the effectiveness of our proposed method, we conduct experiments to demonstrate the efficacy of PEMA with a syntactic dataset and assess its performance on machine translation and style transfer tasks using real datasets. PEMA outperforms other PEFT methods in terms of memory and latency efficiency for training and inference. Furthermore, it outperforms other baselines in preserving the meaning of sentences while generating appropriate language and styles.
CTMQ: Cyclic Training of Convolutional Neural Networks with Multiple Quantization Steps
Jun 26, 2022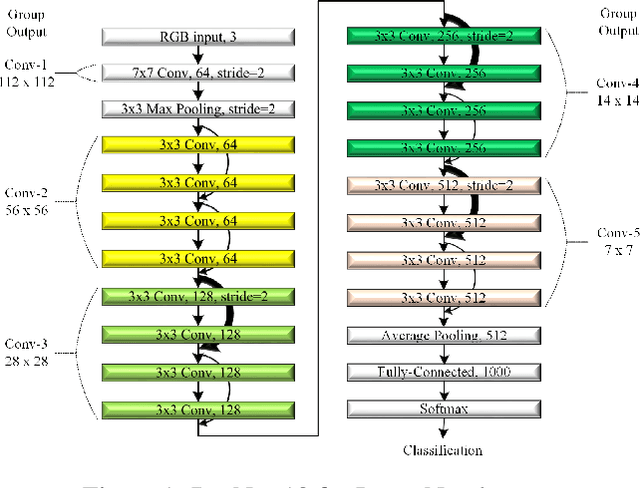
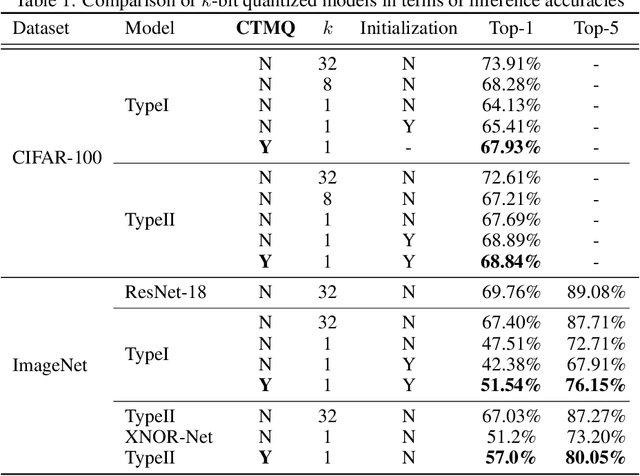
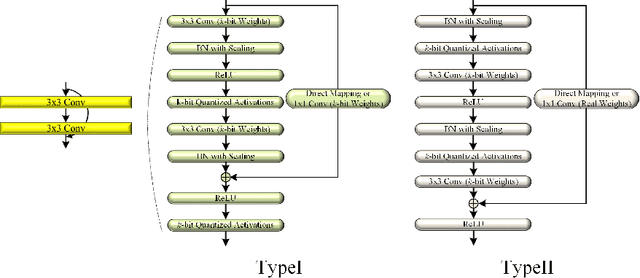
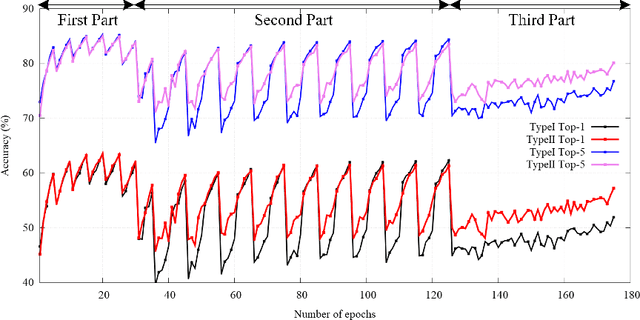
This paper proposes a training method having multiple cyclic training for achieving enhanced performance in low-bit quantized convolutional neural networks (CNNs). Quantization is a popular method for obtaining lightweight CNNs, where the initialization with a pretrained model is widely used to overcome degraded performance in low-resolution quantization. However, large quantization errors between real values and their low-bit quantized ones cause difficulties in achieving acceptable performance for complex networks and large datasets. The proposed training method softly delivers the knowledge of pretrained models to low-bit quantized models in multiple quantization steps. In each quantization step, the trained weights of a model are used to initialize the weights of the next model with the quantization bit depth reduced by one. With small change of the quantization bit depth, the performance gap can be bridged, thus providing better weight initialization. In cyclic training, after training a low-bit quantized model, its trained weights are used in the initialization of its accurate model to be trained. By using better training ability of the accurate model in an iterative manner, the proposed method can produce enhanced trained weights for the low-bit quantized model in each cycle. Notably, the training method can advance Top-1 and Top-5 accuracies of the binarized ResNet-18 on the ImageNet dataset by 5.80% and 6.85%, respectively.
PLAM: a Posit Logarithm-Approximate Multiplier for Power Efficient Posit-based DNNs
Feb 18, 2021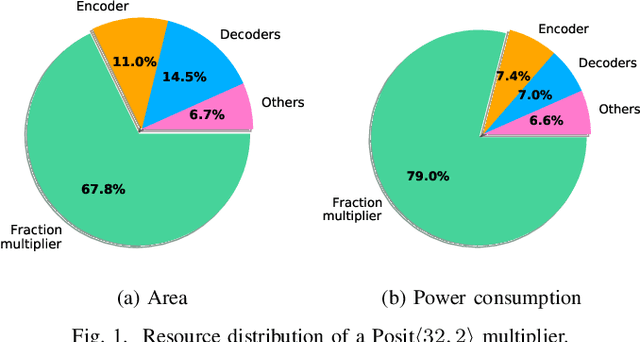

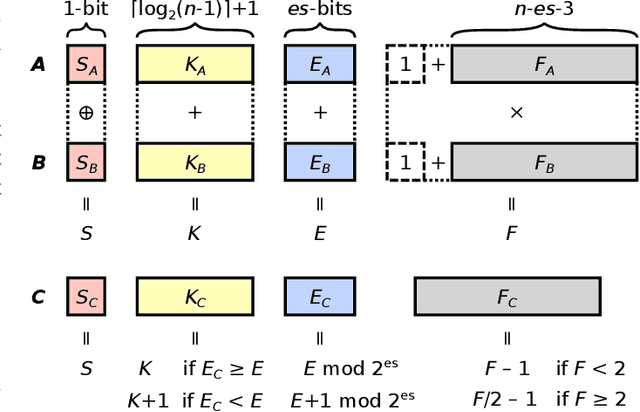
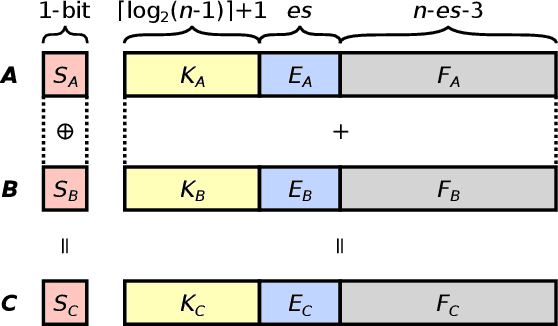
The Posit Number System was introduced in 2017 as a replacement for floating-point numbers. Since then, the community has explored its application in Neural Network related tasks and produced some unit designs which are still far from being competitive with their floating-point counterparts. This paper proposes a Posit Logarithm-Approximate Multiplication (PLAM) scheme to significantly reduce the complexity of posit multipliers, the most power-hungry units within Deep Neural Network architectures. When comparing with state-of-the-art posit multipliers, experiments show that the proposed technique reduces the area, power, and delay of hardware multipliers up to 72.86%, 81.79%, and 17.01%, respectively, without accuracy degradation.
Effects of Approximate Multiplication on Convolutional Neural Networks
Jul 20, 2020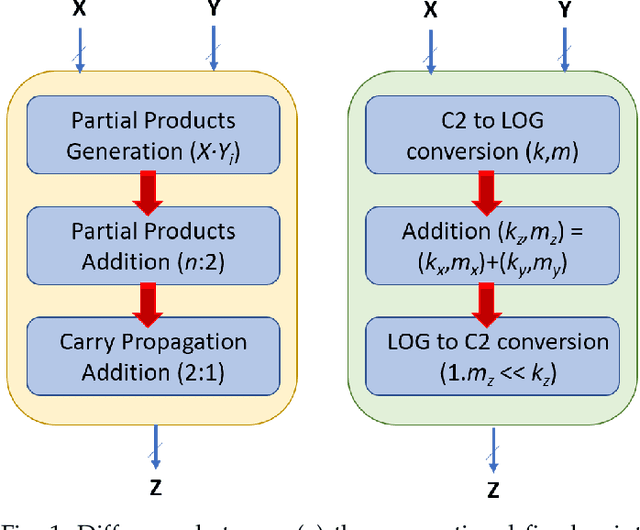
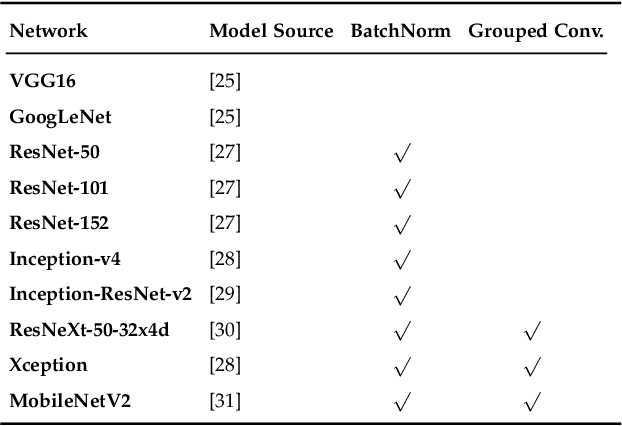
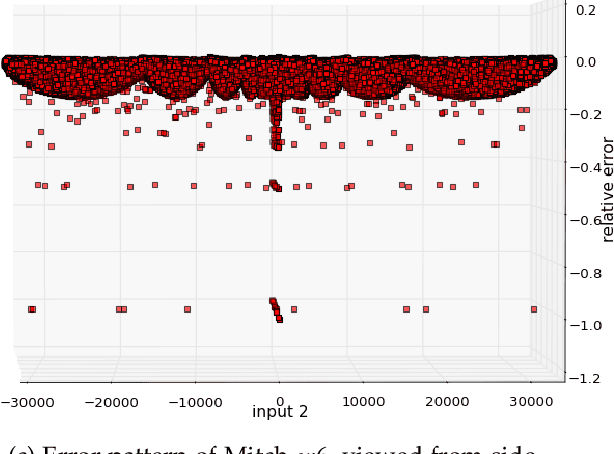

This paper analyzes the effects of approximate multiplication when performing inferences on deep convolutional neural networks (CNNs). The approximate multiplication can reduce the cost of underlying circuits so that CNN inferences can be performed more efficiently in hardware accelerators. The study identifies the critical factors in the convolution, fully-connected, and batch normalization layers that allow more accurate CNN predictions despite the errors from approximate multiplication. The same factors also provide an arithmetic explanation of why bfloat16 multiplication performs well on CNNs. The experiments are performed with recognized network architectures to show that the approximate multipliers can produce predictions that are nearly as accurate as the FP32 references, without additional training. For example, the ResNet and Inception-v4 models with Mitch-$w$6 multiplication produces Top-5 errors that are within 0.2% compared to the FP32 references. A brief cost comparison of Mitch-$w$6 against bfloat16 is presented, where a MAC operation saves up to 80% of energy compared to the bfloat16 arithmetic. The most far-reaching contribution of this paper is the analytical justification that multiplications can be approximated while additions need to be exact in CNN MAC operations.