 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemPO: Self-Memory Policy Optimization for Long-Horizon Agents
Feb 28, 2026Long-horizon agents face the challenge of growing context size during interaction with environment, which degrades the performance and stability. Existing methods typically introduce the external memory module and look up the relevant information from the stored memory, which prevents the model itself from proactively managing its memory content and aligning with the agent's overarching task objectives. To address these limitations, we propose the self-memory policy optimization algorithm (MemPO), which enables the agent (policy model) to autonomously summarize and manage their memory during interaction with environment. By improving the credit assignment mechanism based on memory effectiveness, the policy model can selectively retain crucial information, significantly reducing token consumption while preserving task performance. Extensive experiments and analyses confirm that MemPO achieves absolute F1 score gains of 25.98% over the base model and 7.1% over the previous SOTA baseline, while reducing token usage by 67.58% and 73.12%.
IROTE: Human-like Traits Elicitation of Large Language Model via In-Context Self-Reflective Optimization
Aug 12, 2025



Trained on various human-authored corpora, Large Language Models (LLMs) have demonstrated a certain capability of reflecting specific human-like traits (e.g., personality or values) by prompting, benefiting applications like personalized LLMs and social simulations. However, existing methods suffer from the superficial elicitation problem: LLMs can only be steered to mimic shallow and unstable stylistic patterns, failing to embody the desired traits precisely and consistently across diverse tasks like humans. To address this challenge, we propose IROTE, a novel in-context method for stable and transferable trait elicitation. Drawing on psychological theories suggesting that traits are formed through identity-related reflection, our method automatically generates and optimizes a textual self-reflection within prompts, which comprises self-perceived experience, to stimulate LLMs' trait-driven behavior. The optimization is performed by iteratively maximizing an information-theoretic objective that enhances the connections between LLMs' behavior and the target trait, while reducing noisy redundancy in reflection without any fine-tuning, leading to evocative and compact trait reflection. Extensive experiments across three human trait systems manifest that one single IROTE-generated self-reflection can induce LLMs' stable impersonation of the target trait across diverse downstream tasks beyond simple questionnaire answering, consistently outperforming existing strong baselines.
Value Compass Leaderboard: A Platform for Fundamental and Validated Evaluation of LLMs Values
Jan 13, 2025As Large Language Models (LLMs) achieve remarkable breakthroughs, aligning their values with humans has become imperative for their responsible development and customized applications. However, there still lack evaluations of LLMs values that fulfill three desirable goals. (1) Value Clarification: We expect to clarify the underlying values of LLMs precisely and comprehensively, while current evaluations focus narrowly on safety risks such as bias and toxicity. (2) Evaluation Validity: Existing static, open-source benchmarks are prone to data contamination and quickly become obsolete as LLMs evolve. Additionally, these discriminative evaluations uncover LLMs' knowledge about values, rather than valid assessments of LLMs' behavioral conformity to values. (3) Value Pluralism: The pluralistic nature of human values across individuals and cultures is largely ignored in measuring LLMs value alignment. To address these challenges, we presents the Value Compass Leaderboard, with three correspondingly designed modules. It (i) grounds the evaluation on motivationally distinct \textit{basic values to clarify LLMs' underlying values from a holistic view; (ii) applies a \textit{generative evolving evaluation framework with adaptive test items for evolving LLMs and direct value recognition from behaviors in realistic scenarios; (iii) propose a metric that quantifies LLMs alignment with a specific value as a weighted sum over multiple dimensions, with weights determined by pluralistic values.
The Road to Artificial SuperIntelligence: A Comprehensive Survey of Superalignment
Dec 24, 2024



The emergence of large language models (LLMs) has sparked the possibility of about Artificial Superintelligence (ASI), a hypothetical AI system surpassing human intelligence. However, existing alignment paradigms struggle to guide such advanced AI systems. Superalignment, the alignment of AI systems with human values and safety requirements at superhuman levels of capability aims to addresses two primary goals -- scalability in supervision to provide high-quality guidance signals and robust governance to ensure alignment with human values. In this survey, we examine scalable oversight methods and potential solutions for superalignment. Specifically, we explore the concept of ASI, the challenges it poses, and the limitations of current alignment paradigms in addressing the superalignment problem. Then we review scalable oversight methods for superalignment. Finally, we discuss the key challenges and propose pathways for the safe and continual improvement of ASI systems. By comprehensively reviewing the current literature, our goal is provide a systematical introduction of existing methods, analyze their strengths and limitations, and discuss potential future directions.
On the Essence and Prospect: An Investigation of Alignment Approaches for Big Models
Mar 07, 2024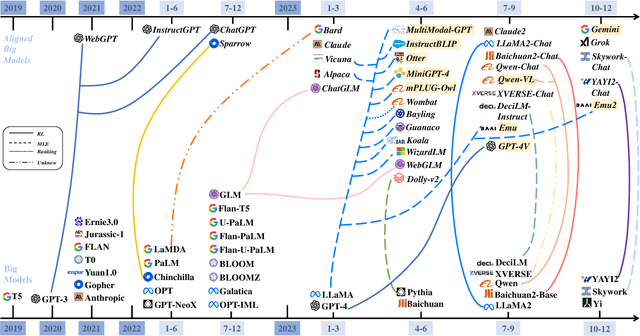
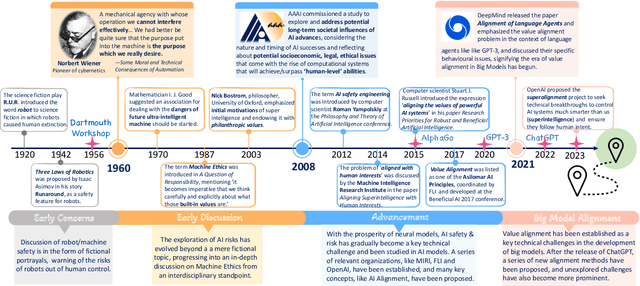
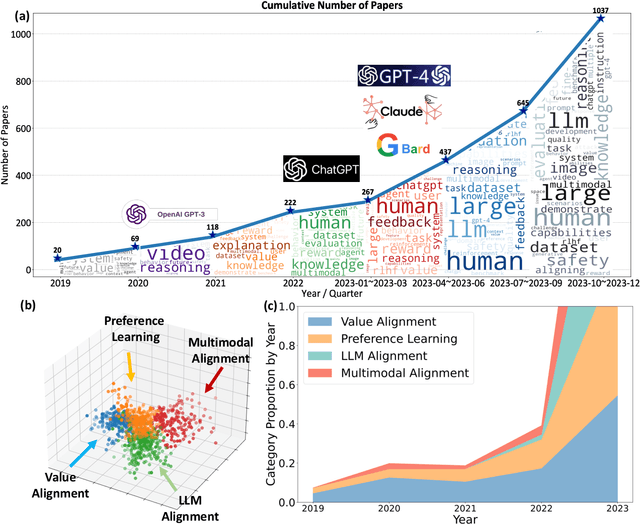
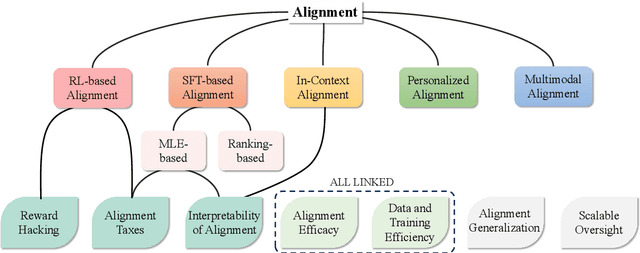
Big models have achieved revolutionary breakthroughs in the field of AI, but they might also pose potential concerns. Addressing such concerns, alignment technologies were introduced to make these models conform to human preferences and values. Despite considerable advancements in the past year, various challenges lie in establishing the optimal alignment strategy, such as data cost and scalable oversight, and how to align remains an open question. In this survey paper, we comprehensively investigate value alignment approaches. We first unpack the historical context of alignment tracing back to the 1920s (where it comes from), then delve into the mathematical essence of alignment (what it is), shedding light on the inherent challenges. Following this foundation, we provide a detailed examination of existing alignment methods, which fall into three categories: Reinforcement Learning, Supervised Fine-Tuning, and In-context Learning, and demonstrate their intrinsic connections, strengths, and limitations, helping readers better understand this research area. In addition, two emerging topics, personal alignment, and multimodal alignment, are also discussed as novel frontiers in this field. Looking forward, we discuss potential alignment paradigms and how they could handle remaining challenges, prospecting where future alignment will go.
Negating Negatives: Alignment without Human Positive Samples via Distributional Dispreference Optimization
Mar 06, 2024



Large language models (LLMs) have revolutionized the role of AI, yet also pose potential risks of propagating unethical content. Alignment technologies have been introduced to steer LLMs towards human preference, gaining increasing attention. Despite notable breakthroughs in this direction, existing methods heavily rely on high-quality positive-negative training pairs, suffering from noisy labels and the marginal distinction between preferred and dispreferred response data. Given recent LLMs' proficiency in generating helpful responses, this work pivots towards a new research focus: achieving alignment using solely human-annotated negative samples, preserving helpfulness while reducing harmfulness. For this purpose, we propose Distributional Dispreference Optimization (D$^2$O), which maximizes the discrepancy between the generated responses and the dispreferred ones to effectively eschew harmful information. We theoretically demonstrate that D$^2$O is equivalent to learning a distributional instead of instance-level preference model reflecting human dispreference against the distribution of negative responses. Besides, D$^2$O integrates an implicit Jeffrey Divergence regularization to balance the exploitation and exploration of reference policies and converges to a non-negative one during training. Extensive experiments demonstrate that our method achieves comparable generation quality and surpasses the latest baselines in producing less harmful and more informative responses with better training stability and faster convergence.
Denevil: Towards Deciphering and Navigating the Ethical Values of Large Language Models via Instruction Learning
Oct 30, 2023



Large Language Models (LLMs) have made unprecedented breakthroughs, yet their increasing integration into everyday life might raise societal risks due to generated unethical content. Despite extensive study on specific issues like bias, the intrinsic values of LLMs remain largely unexplored from a moral philosophy perspective. This work delves into ethical values utilizing Moral Foundation Theory. Moving beyond conventional discriminative evaluations with poor reliability, we propose DeNEVIL, a novel prompt generation algorithm tailored to dynamically exploit LLMs' value vulnerabilities and elicit the violation of ethics in a generative manner, revealing their underlying value inclinations. On such a basis, we construct MoralPrompt, a high-quality dataset comprising 2,397 prompts covering 500+ value principles, and then benchmark the intrinsic values across a spectrum of LLMs. We discovered that most models are essentially misaligned, necessitating further ethical value alignment. In response, we develop VILMO, an in-context alignment method that substantially enhances the value compliance of LLM outputs by learning to generate appropriate value instructions, outperforming existing competitors. Our methods are suitable for black-box and open-source models, offering a promising initial step in studying the ethical values of LLMs.