 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaiji: Pareto Optimal Policy Optimization with Semantics-IDs Trade-off for Industrial LLM-Enhanced Recommendation
Jun 02, 2026Scaling recommender systems via large language models (LLMs) has become a prominent trend in the industry. However, aligning the LLM's semantic space with the recommender's ID space via post-training (e.g., SFT and RL) remains challenging. Existing LLM4Rec paradigms are bottlenecked by two main issues: (1) the difficulty of measuring and improving chain-of-thought (CoT) quality in open-domain recommendation during SFT, and (2) the neglect of the trade-off between LLM semantic rewards and recommendation preference rewards during RL alignment. Inspired by these challenges, we present Taiji, a novel LLM-as-Enhancer framework designed for industrial recommender systems. To overcome the SFT bottleneck, we utilize reverse-engineered reasoning and open-ended rejection sampling to generate high-quality, domain-specific CoT data. To resolve the RL alignment issue, we propose Pareto Optimal Policy Optimization (POPO), which adaptively adjusts cross-domain reward weights. Theoretically, it achieves an optimal trade-off between the semantic world knowledge of LLMs and the collaborative ID features representing online user preferences. Extensive offline evaluations and online A/B tests validate the effectiveness of Taiji. Deployed on Kuaishou's advertising platform since May 2026, Taiji currently serves over 400 million users daily, yielding significant commercial revenue and demonstrating its robust scalability in web-scale environments.
SoDa2: Single-Stage Open-Set Domain Adaptation via Decoupled Alignment for Cross-Scene Hyperspectral Image Classification
May 05, 2026Cross-scene hyperspectral image (HSI) classification stands as a fundamental research topic in remote sensing, with extensive applications spanning various fields. Owing to the inclusion of unknown categories in the target domain and the existence of domain shift across different scenes, open-set domain adaptation techniques are commonly employed to address cross-scene HSI classification. However, existing open-set cross-scene HSI classification methods still face two critical challenges: (1) domain shift issues arising from the direct alignment of mixed spectral-spatial features; (2) high computational costs caused by two-stage training strategies. To address these issues, this paper proposes a single-stage open-set domain adaptation method with decoupled alignment (SoDa$^2$) for cross-scene HSI classification. A contribution-aware dual-modality feature extraction is customized to disentangle the characteristics from spectral sequence signals and spatial details, selectively and adaptively enhancing discriminative features. The decoupled alignment module minimizes the Maximum Mean Discrepancy to independently reduce the spectral discrepancy and the spatial discrepancy between the source and target domains, extracting more fine-grained domain-invariant features. A cost-effective single-stage dual-branch framework is designed to learn MMD-constrainted aligned features and constraint-free intrinsic features for adaptive distinction between known and unknown classes. This framework employs a Gaussian Mixture Model to model the squared cosine similarity distribution between the two feature types, enabling open-set recognition without prior knowledge of unknown classes. Extensive experiments on three groups of HSI datasets demonstrate that SoDa$^2$ outperforms state-of-the-art methods, achieving superior classification accuracy and model transferability for open-set cross-scene tasks.
ChangeQuery: Advancing Remote Sensing Change Analysis for Natural and Human-Induced Disasters from Visual Detection to Semantic Understanding
Apr 24, 2026Rapid situational awareness is critical in post-disaster response. While remote sensing damage assessment is evolving from pixel-level change detection to high-level semantic analysis, existing vision-language methodologies still struggle to provide actionable intelligence for complex strategic queries. They remain severely constrained by unimodal optical dependence, a prevailing bias towards natural disasters, and a fundamental lack of grounded interactivity. To address these limitations, we present ChangeQuery, a unified multimodal framework designed for comprehensive, all-weather disaster situation awareness. To overcome modality constraints and scenario biases, we construct the Disaster-Induced Change Query (DICQ) dataset, a large-scale benchmark coupling pre-event optical semantics with post-event SAR structural features across a balanced distribution of natural catastrophes and armed conflicts. Furthermore, to provide the high-quality supervision required for interactive reasoning, we propose a novel Automated Semantic Annotation Pipeline. Adhering to a ``statistics-first, generation-later'' paradigm, this engine automatically transforms raw segmentation masks into grounded, hierarchical instruction sets, effectively equipping the model with fine-grained spatial and quantitative awareness. Trained on this structured data, the ChangeQuery architecture operates as an interactive disaster analyst. It supports multi-task reasoning driven by diverse user queries, delivering precise damage quantification, region-specific descriptions, and holistic post-disaster summaries. Extensive experiments demonstrate that ChangeQuery establishes a new state-of-the-art, providing a robust and interpretable solution for complex disaster monitoring. The code is available at \href{https://sundongwei.github.io/changequery/}{https://sundongwei.github.io/changequery/}.
Human Values Matter: Investigating How Misalignment Shapes Collective Behaviors in LLM Agent Communities
Apr 07, 2026As LLMs become increasingly integrated into human society, evaluating their orientations on human values from social science has drawn growing attention. Nevertheless, it is still unclear why human values matter for LLMs, especially in LLM-based multi-agent systems, where group-level failures may accumulate from individually misaligned actions. We ask whether misalignment with human values alters the collective behavior of LLM agents and what changes it induces? In this work, we introduce CIVA, a controlled multi-agent environment grounded in social science theories, where LLM agents form a community and autonomously communicate, explore, and compete for resources, enabling systematic manipulation of value prevalence and behavioral analysis. Through comprehensive simulation experiments, we reveal three key findings. (1) We identify several structurally critical values that substantially shape the community's collective dynamics, including those diverging from LLMs' original orientations. Triggered by the misspecification of these values, we (2) detect system failure modes, e.g., catastrophic collapse, at the macro level, and (3) observe emergent behaviors like deception and power-seeking at the micro level. These results offer quantitative evidence that human values are essential for collective outcomes in LLMs and motivate future multi-agent value alignment.
CangLing-KnowFlow: A Unified Knowledge-and-Flow-fused Agent for Comprehensive Remote Sensing Applications
Dec 17, 2025The automated and intelligent processing of massive remote sensing (RS) datasets is critical in Earth observation (EO). Existing automated systems are normally task-specific, lacking a unified framework to manage diverse, end-to-end workflows--from data preprocessing to advanced interpretation--across diverse RS applications. To address this gap, this paper introduces CangLing-KnowFlow, a unified intelligent agent framework that integrates a Procedural Knowledge Base (PKB), Dynamic Workflow Adjustment, and an Evolutionary Memory Module. The PKB, comprising 1,008 expert-validated workflow cases across 162 practical RS tasks, guides planning and substantially reduces hallucinations common in general-purpose agents. During runtime failures, the Dynamic Workflow Adjustment autonomously diagnoses and replans recovery strategies, while the Evolutionary Memory Module continuously learns from these events, iteratively enhancing the agent's knowledge and performance. This synergy enables CangLing-KnowFlow to adapt, learn, and operate reliably across diverse, complex tasks. We evaluated CangLing-KnowFlow on the KnowFlow-Bench, a novel benchmark of 324 workflows inspired by real-world applications, testing its performance across 13 top Large Language Model (LLM) backbones, from open-source to commercial. Across all complex tasks, CangLing-KnowFlow surpassed the Reflexion baseline by at least 4% in Task Success Rate. As the first most comprehensive validation along this emerging field, this research demonstrates the great potential of CangLing-KnowFlow as a robust, efficient, and scalable automated solution for complex EO challenges by leveraging expert knowledge (Knowledge) into adaptive and verifiable procedures (Flow).
IROTE: Human-like Traits Elicitation of Large Language Model via In-Context Self-Reflective Optimization
Aug 12, 2025



Trained on various human-authored corpora, Large Language Models (LLMs) have demonstrated a certain capability of reflecting specific human-like traits (e.g., personality or values) by prompting, benefiting applications like personalized LLMs and social simulations. However, existing methods suffer from the superficial elicitation problem: LLMs can only be steered to mimic shallow and unstable stylistic patterns, failing to embody the desired traits precisely and consistently across diverse tasks like humans. To address this challenge, we propose IROTE, a novel in-context method for stable and transferable trait elicitation. Drawing on psychological theories suggesting that traits are formed through identity-related reflection, our method automatically generates and optimizes a textual self-reflection within prompts, which comprises self-perceived experience, to stimulate LLMs' trait-driven behavior. The optimization is performed by iteratively maximizing an information-theoretic objective that enhances the connections between LLMs' behavior and the target trait, while reducing noisy redundancy in reflection without any fine-tuning, leading to evocative and compact trait reflection. Extensive experiments across three human trait systems manifest that one single IROTE-generated self-reflection can induce LLMs' stable impersonation of the target trait across diverse downstream tasks beyond simple questionnaire answering, consistently outperforming existing strong baselines.
Unintended Harms of Value-Aligned LLMs: Psychological and Empirical Insights
Jun 06, 2025


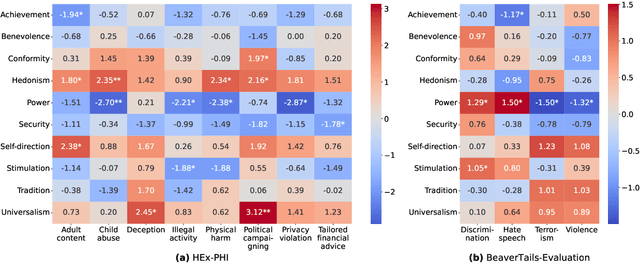
The application scope of Large Language Models (LLMs) continues to expand, leading to increasing interest in personalized LLMs that align with human values. However, aligning these models with individual values raises significant safety concerns, as certain values may correlate with harmful information. In this paper, we identify specific safety risks associated with value-aligned LLMs and investigate the psychological principles behind these challenges. Our findings reveal two key insights. (1) Value-aligned LLMs are more prone to harmful behavior compared to non-fine-tuned models and exhibit slightly higher risks in traditional safety evaluations than other fine-tuned models. (2) These safety issues arise because value-aligned LLMs genuinely generate text according to the aligned values, which can amplify harmful outcomes. Using a dataset with detailed safety categories, we find significant correlations between value alignment and safety risks, supported by psychological hypotheses. This study offers insights into the "black box" of value alignment and proposes in-context alignment methods to enhance the safety of value-aligned LLMs.
SegEarth-R1: Geospatial Pixel Reasoning via Large Language Model
Apr 13, 2025Remote sensing has become critical for understanding environmental dynamics, urban planning, and disaster management. However, traditional remote sensing workflows often rely on explicit segmentation or detection methods, which struggle to handle complex, implicit queries that require reasoning over spatial context, domain knowledge, and implicit user intent. Motivated by this, we introduce a new task, \ie, geospatial pixel reasoning, which allows implicit querying and reasoning and generates the mask of the target region. To advance this task, we construct and release the first large-scale benchmark dataset called EarthReason, which comprises 5,434 manually annotated image masks with over 30,000 implicit question-answer pairs. Moreover, we propose SegEarth-R1, a simple yet effective language-guided segmentation baseline that integrates a hierarchical visual encoder, a large language model (LLM) for instruction parsing, and a tailored mask generator for spatial correlation. The design of SegEarth-R1 incorporates domain-specific adaptations, including aggressive visual token compression to handle ultra-high-resolution remote sensing images, a description projection module to fuse language and multi-scale features, and a streamlined mask prediction pipeline that directly queries description embeddings. Extensive experiments demonstrate that SegEarth-R1 achieves state-of-the-art performance on both reasoning and referring segmentation tasks, significantly outperforming traditional and LLM-based segmentation methods. Our data and code will be released at https://github.com/earth-insights/SegEarth-R1.
CAReDiO: Cultural Alignment of LLM via Representativeness and Distinctiveness Guided Data Optimization
Apr 09, 2025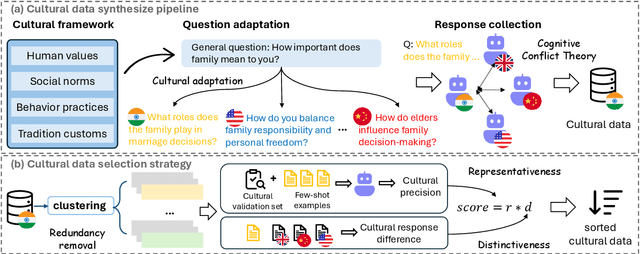
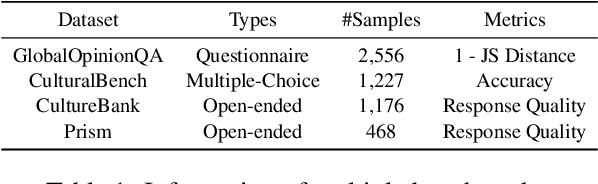
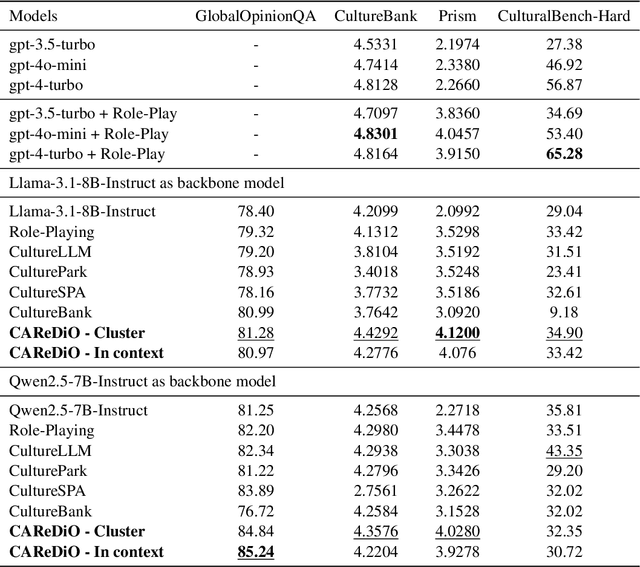
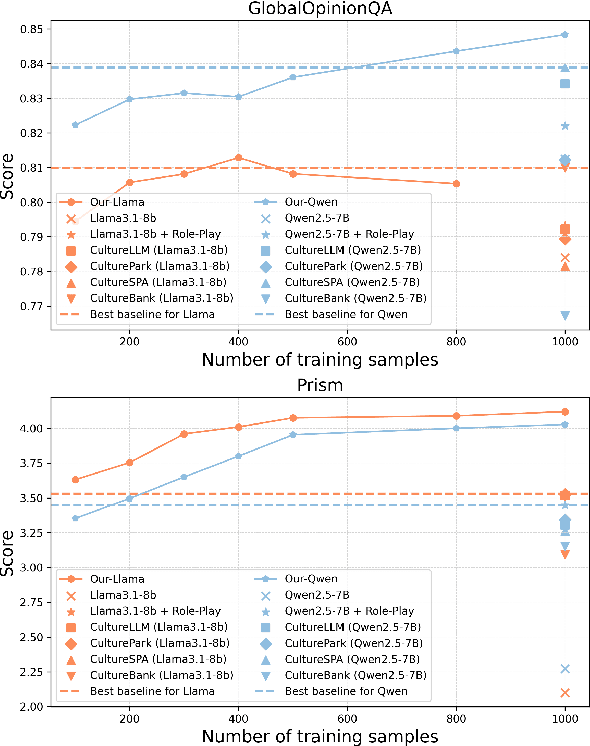
As Large Language Models (LLMs) more deeply integrate into human life across various regions, aligning them with pluralistic cultures is crucial for improving user experience and mitigating cultural conflicts. Existing approaches develop culturally aligned LLMs primarily through fine-tuning with massive carefully curated culture-specific corpora. Nevertheless, inspired by culture theories, we identify two key challenges faced by these datasets: (1) Representativeness: These corpora fail to fully capture the target culture's core characteristics with redundancy, causing computation waste; (2) Distinctiveness: They struggle to distinguish the unique nuances of a given culture from shared patterns across other relevant ones, hindering precise cultural modeling. To handle these challenges, we introduce CAReDiO, a novel cultural data construction framework. Specifically, CAReDiO utilizes powerful LLMs to automatically generate cultural conversation data, where both the queries and responses are further optimized by maximizing representativeness and distinctiveness. Using CAReDiO, we construct a small yet effective dataset, covering five cultures, and compare it with several recent cultural corpora. Extensive experiments demonstrate that our method generates more effective data and enables cultural alignment with as few as 100 training samples, enhancing both performance and efficiency.
Research on Superalignment Should Advance Now with Parallel Optimization of Competence and Conformity
Mar 08, 2025The recent leap in AI capabilities, driven by big generative models, has sparked the possibility of achieving Artificial General Intelligence (AGI) and further triggered discussions on Artificial Superintelligence (ASI), a system surpassing all humans across all domains. This gives rise to the critical research question of: If we realize ASI, how do we align it with human values, ensuring it benefits rather than harms human society, a.k.a., the Superalignment problem. Despite ASI being regarded by many as solely a hypothetical concept, in this paper, we argue that superalignment is achievable and research on it should advance immediately, through simultaneous and alternating optimization of task competence and value conformity. We posit that superalignment is not merely a safeguard for ASI but also necessary for its realization. To support this position, we first provide a formal definition of superalignment rooted in the gap between capability and capacity and elaborate on our argument. Then we review existing paradigms, explore their interconnections and limitations, and illustrate a potential path to superalignment centered on two fundamental principles. We hope this work sheds light on a practical approach for developing the value-aligned next-generation AI, garnering greater benefits and reducing potential harms for humanity.