 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual, Culture-First Approach to Addressing Misgendering in LLM Applications
Mar 26, 2025Misgendering is the act of referring to someone by a gender that does not match their chosen identity. It marginalizes and undermines a person's sense of self, causing significant harm. English-based approaches have clear-cut approaches to avoiding misgendering, such as the use of the pronoun ``they''. However, other languages pose unique challenges due to both grammatical and cultural constructs. In this work we develop methodologies to assess and mitigate misgendering across 42 languages and dialects using a participatory-design approach to design effective and appropriate guardrails across all languages. We test these guardrails in a standard large language model-based application (meeting transcript summarization), where both the data generation and the annotation steps followed a human-in-the-loop approach. We find that the proposed guardrails are very effective in reducing misgendering rates across all languages in the summaries generated, and without incurring loss of quality. Our human-in-the-loop approach demonstrates a method to feasibly scale inclusive and responsible AI-based solutions across multiple languages and cultures.
WildLong: Synthesizing Realistic Long-Context Instruction Data at Scale
Feb 23, 2025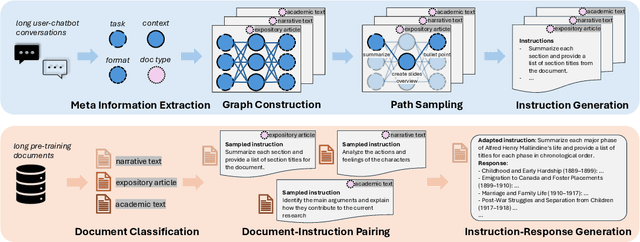
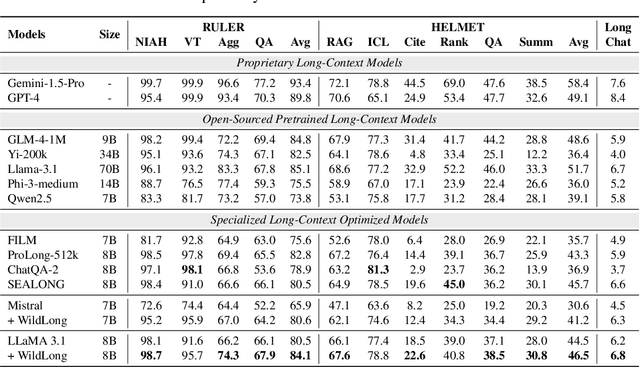
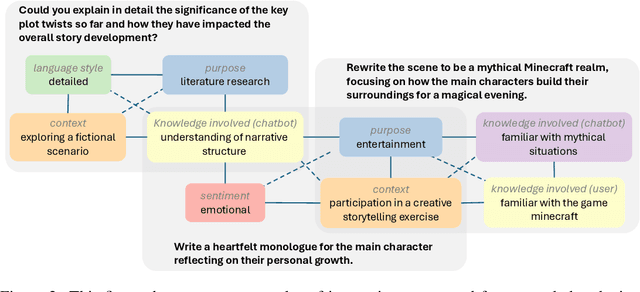
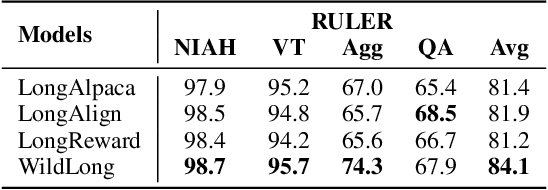
Large language models (LLMs) with extended context windows enable tasks requiring extensive information integration but are limited by the scarcity of high-quality, diverse datasets for long-context instruction tuning. Existing data synthesis methods focus narrowly on objectives like fact retrieval and summarization, restricting their generalizability to complex, real-world tasks. WildLong extracts meta-information from real user queries, models co-occurrence relationships via graph-based methods, and employs adaptive generation to produce scalable data. It extends beyond single-document tasks to support multi-document reasoning, such as cross-document comparison and aggregation. Our models, finetuned on 150K instruction-response pairs synthesized using WildLong, surpasses existing open-source long-context-optimized models across benchmarks while maintaining strong performance on short-context tasks without incorporating supplementary short-context data. By generating a more diverse and realistic long-context instruction dataset, WildLong enhances LLMs' ability to generalize to complex, real-world reasoning over long contexts, establishing a new paradigm for long-context data synthesis.
One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks
Oct 14, 2024


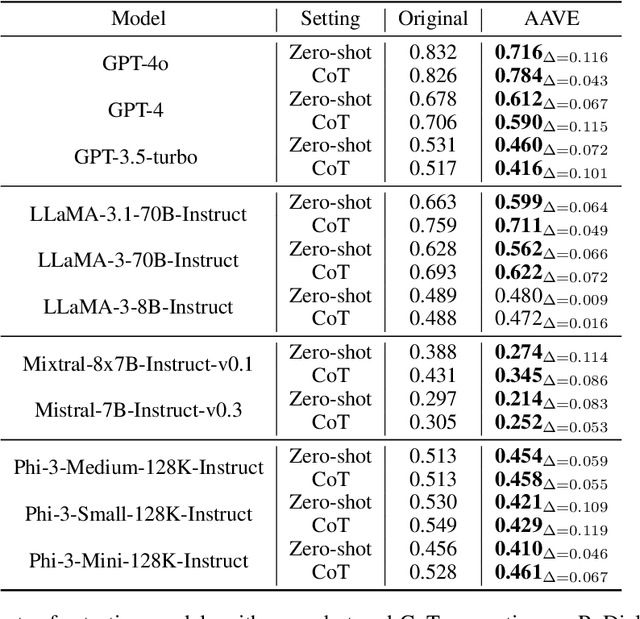
Language is not monolithic. While many benchmarks are used as proxies to systematically estimate Large Language Models' (LLM) performance in real-life tasks, they tend to ignore the nuances of within-language variation and thus fail to model the experience of speakers of minority dialects. Focusing on African American Vernacular English (AAVE), we present the first study on LLMs' fairness and robustness to a dialect in canonical reasoning tasks (algorithm, math, logic, and comprehensive reasoning). We hire AAVE speakers, including experts with computer science backgrounds, to rewrite seven popular benchmarks, such as HumanEval and GSM8K. The result of this effort is ReDial, a dialectal benchmark comprising $1.2K+$ parallel query pairs in Standardized English and AAVE. We use ReDial to evaluate state-of-the-art LLMs, including GPT-4o/4/3.5-turbo, LLaMA-3.1/3, Mistral, and Phi-3. We find that, compared to Standardized English, almost all of these widely used models show significant brittleness and unfairness to queries in AAVE. Furthermore, AAVE queries can degrade performance more substantially than misspelled texts in Standardized English, even when LLMs are more familiar with the AAVE queries. Finally, asking models to rephrase questions in Standardized English does not close the performance gap but generally introduces higher costs. Overall, our findings indicate that LLMs provide unfair service to dialect users in complex reasoning tasks. Code can be found at https://github.com/fangru-lin/redial_dialect_robustness_fairness.git.
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Jul 22, 2024
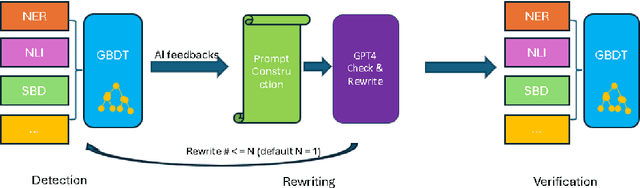
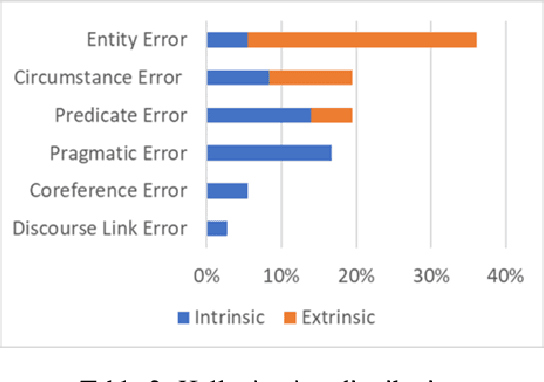
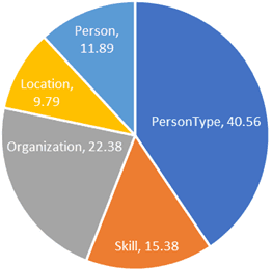
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
xRAG: Extreme Context Compression for Retrieval-augmented Generation with One Token
May 22, 2024
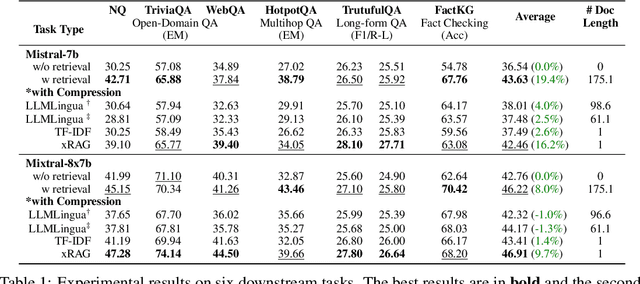
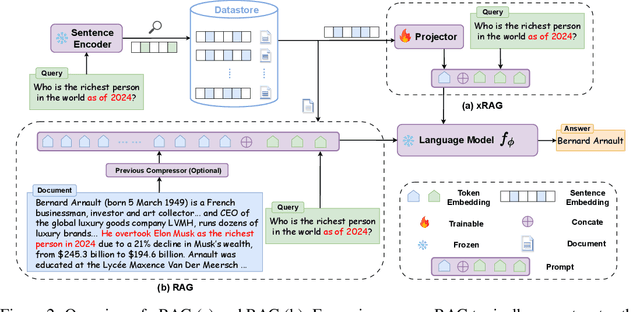
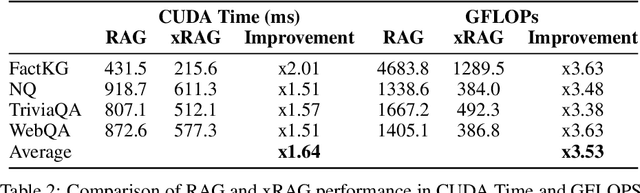
This paper introduces xRAG, an innovative context compression method tailored for retrieval-augmented generation. xRAG reinterprets document embeddings in dense retrieval--traditionally used solely for retrieval--as features from the retrieval modality. By employing a modality fusion methodology, xRAG seamlessly integrates these embeddings into the language model representation space, effectively eliminating the need for their textual counterparts and achieving an extreme compression rate. In xRAG, the only trainable component is the modality bridge, while both the retriever and the language model remain frozen. This design choice allows for the reuse of offline-constructed document embeddings and preserves the plug-and-play nature of retrieval augmentation. Experimental results demonstrate that xRAG achieves an average improvement of over 10% across six knowledge-intensive tasks, adaptable to various language model backbones, ranging from a dense 7B model to an 8x7B Mixture of Experts configuration. xRAG not only significantly outperforms previous context compression methods but also matches the performance of uncompressed models on several datasets, while reducing overall FLOPs by a factor of 3.53. Our work pioneers new directions in retrieval-augmented generation from the perspective of multimodality fusion, and we hope it lays the foundation for future efficient and scalable retrieval-augmented systems
RTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Apr 22, 2024



Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.
On Meta-Prompting
Dec 11, 2023
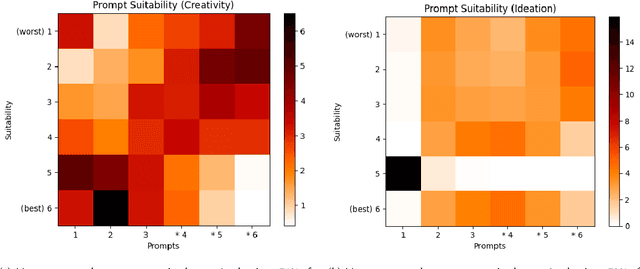
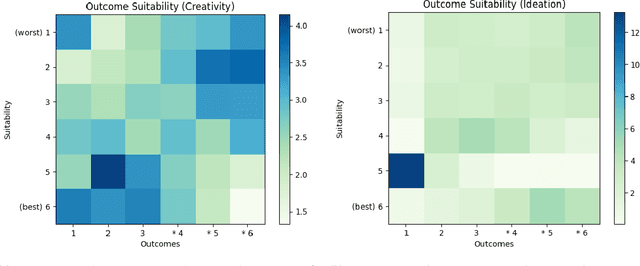
Certain statistical models are capable of interpreting input strings as instructions, or prompts, and carry out tasks based on them. Many approaches to prompting and pre-training these models involve the automated generation of these prompts. We call these approaches meta-prompting, or prompting to obtain prompts. We propose a theoretical framework based on category theory to generalize and describe them. This framework is flexible enough to account for LLM stochasticity; and allows us to obtain formal results around task agnosticity and equivalence of various meta-prompting approaches. We experiment with meta-prompting in two active areas of model research: creativity and ideation. We find that user preference favors (p < 0.01) the prompts generated under meta-prompting, as well as their corresponding outputs, over a series of hardcoded baseline prompts that include the original task prompt. Using our framework, we argue that meta-prompting is more effective than basic prompting at generating desirable outputs.
SCALE: Synergized Collaboration of Asymmetric Language Translation Engines
Sep 29, 2023In this paper, we introduce SCALE, a collaborative framework that connects compact Specialized Translation Models (STMs) and general-purpose Large Language Models (LLMs) as one unified translation engine. By introducing translation from STM into the triplet in-context demonstrations, SCALE unlocks refinement and pivoting ability of LLM, thus mitigating language bias of LLM and parallel data bias of STM, enhancing LLM speciality without sacrificing generality, and facilitating continual learning without expensive LLM fine-tuning. Our comprehensive experiments show that SCALE significantly outperforms both few-shot LLMs (GPT-4) and specialized models (NLLB) in challenging low-resource settings. Moreover, in Xhosa to English translation, SCALE experiences consistent improvement by a 4 BLEURT score without tuning LLM and surpasses few-shot GPT-4 by 2.5 COMET score and 3.8 BLEURT score when equipped with a compact model consisting of merely 600M parameters. SCALE could also effectively exploit the existing language bias of LLMs by using an English-centric STM as a pivot for translation between any language pairs, outperforming few-shot GPT-4 by an average of 6 COMET points across eight translation directions. Furthermore we provide an in-depth analysis of SCALE's robustness, translation characteristics, and latency costs, providing solid foundation for future studies exploring the potential synergy between LLMs and more specialized, task-specific models.
A User-Centered Evaluation of Spanish Text Simplification
Aug 15, 2023We present an evaluation of text simplification (TS) in Spanish for a production system, by means of two corpora focused in both complex-sentence and complex-word identification. We compare the most prevalent Spanish-specific readability scores with neural networks, and show that the latter are consistently better at predicting user preferences regarding TS. As part of our analysis, we find that multilingual models underperform against equivalent Spanish-only models on the same task, yet all models focus too often on spurious statistical features, such as sentence length. We release the corpora in our evaluation to the broader community with the hopes of pushing forward the state-of-the-art in Spanish natural language processing.