 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Pathways to Truthfulness: On the Intrinsic Encoding of LLM Hallucinations
Jan 12, 2026Despite their impressive capabilities, large language models (LLMs) frequently generate hallucinations. Previous work shows that their internal states encode rich signals of truthfulness, yet the origins and mechanisms of these signals remain unclear. In this paper, we demonstrate that truthfulness cues arise from two distinct information pathways: (1) a Question-Anchored pathway that depends on question-answer information flow, and (2) an Answer-Anchored pathway that derives self-contained evidence from the generated answer itself. First, we validate and disentangle these pathways through attention knockout and token patching. Afterwards, we uncover notable and intriguing properties of these two mechanisms. Further experiments reveal that (1) the two mechanisms are closely associated with LLM knowledge boundaries; and (2) internal representations are aware of their distinctions. Finally, building on these insightful findings, two applications are proposed to enhance hallucination detection performance. Overall, our work provides new insight into how LLMs internally encode truthfulness, offering directions for more reliable and self-aware generative systems.
Error Bound Analysis of Physics-Informed Neural Networks-Driven T2 Quantification in Cardiac Magnetic Resonance Imaging
Dec 16, 2025



Physics-Informed Neural Networks (PINN) are emerging as a promising approach for quantitative parameter estimation of Magnetic Resonance Imaging (MRI). While existing deep learning methods can provide an accurate quantitative estimation of the T2 parameter, they still require large amounts of training data and lack theoretical support and a recognized gold standard. Thus, given the absence of PINN-based approaches for T2 estimation, we propose embedding the fundamental physics of MRI, the Bloch equation, in the loss of PINN, which is solely based on target scan data and does not require a pre-defined training database. Furthermore, by deriving rigorous upper bounds for both the T2 estimation error and the generalization error of the Bloch equation solution, we establish a theoretical foundation for evaluating the PINN's quantitative accuracy. Even without access to the ground truth or a gold standard, this theory enables us to estimate the error with respect to the real quantitative parameter T2. The accuracy of T2 mapping and the validity of the theoretical analysis are demonstrated on a numerical cardiac model and a water phantom, where our method exhibits excellent quantitative precision in the myocardial T2 range. Clinical applicability is confirmed in 94 acute myocardial infarction (AMI) patients, achieving low-error quantitative T2 estimation under the theoretical error bound, highlighting the robustness and potential of PINN.
Continual Action Quality Assessment via Adaptive Manifold-Aligned Graph Regularization
Oct 08, 2025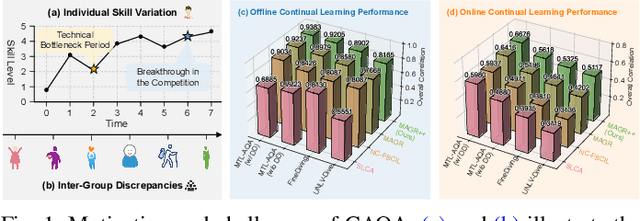
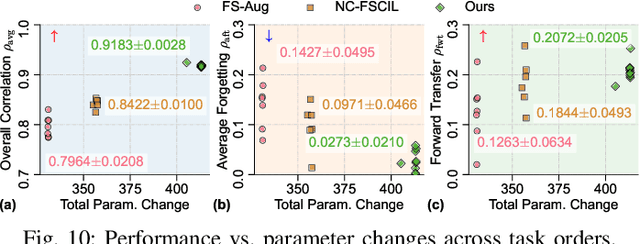
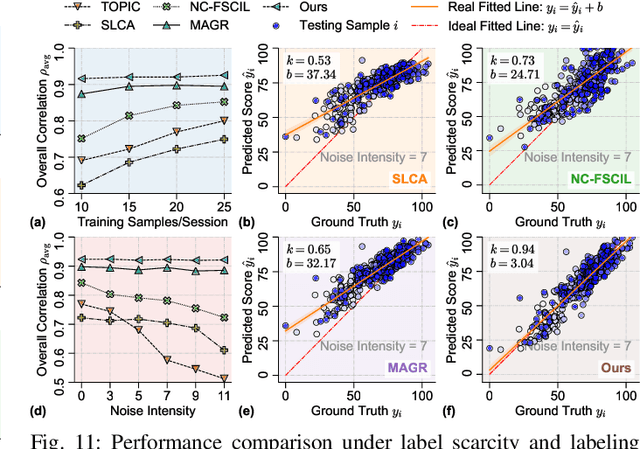
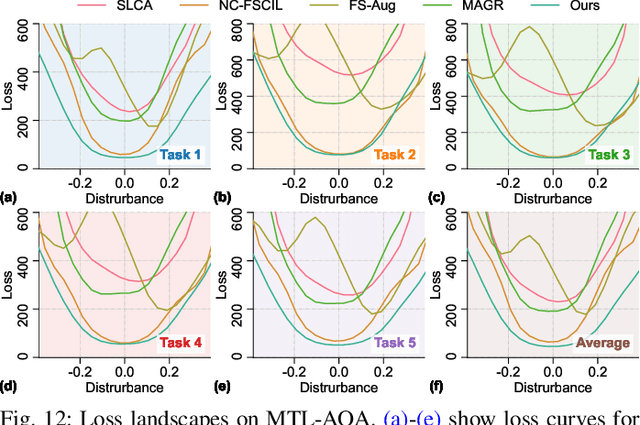
Action Quality Assessment (AQA) quantifies human actions in videos, supporting applications in sports scoring, rehabilitation, and skill evaluation. A major challenge lies in the non-stationary nature of quality distributions in real-world scenarios, which limits the generalization ability of conventional methods. We introduce Continual AQA (CAQA), which equips AQA with Continual Learning (CL) capabilities to handle evolving distributions while mitigating catastrophic forgetting. Although parameter-efficient fine-tuning of pretrained models has shown promise in CL for image classification, we find it insufficient for CAQA. Our empirical and theoretical analyses reveal two insights: (i) Full-Parameter Fine-Tuning (FPFT) is necessary for effective representation learning; yet (ii) uncontrolled FPFT induces overfitting and feature manifold shift, thereby aggravating forgetting. To address this, we propose Adaptive Manifold-Aligned Graph Regularization (MAGR++), which couples backbone fine-tuning that stabilizes shallow layers while adapting deeper ones with a two-step feature rectification pipeline: a manifold projector to translate deviated historical features into the current representation space, and a graph regularizer to align local and global distributions. We construct four CAQA benchmarks from three datasets with tailored evaluation protocols and strong baselines, enabling systematic cross-dataset comparison. Extensive experiments show that MAGR++ achieves state-of-the-art performance, with average correlation gains of 3.6% offline and 12.2% online over the strongest baseline, confirming its robustness and effectiveness. Our code is available at https://github.com/ZhouKanglei/MAGRPP.
PHI: Bridging Domain Shift in Long-Term Action Quality Assessment via Progressive Hierarchical Instruction
May 26, 2025Long-term Action Quality Assessment (AQA) aims to evaluate the quantitative performance of actions in long videos. However, existing methods face challenges due to domain shifts between the pre-trained large-scale action recognition backbones and the specific AQA task, thereby hindering their performance. This arises since fine-tuning resource-intensive backbones on small AQA datasets is impractical. We address this by identifying two levels of domain shift: task-level, regarding differences in task objectives, and feature-level, regarding differences in important features. For feature-level shifts, which are more detrimental, we propose Progressive Hierarchical Instruction (PHI) with two strategies. First, Gap Minimization Flow (GMF) leverages flow matching to progressively learn a fast flow path that reduces the domain gap between initial and desired features across shallow to deep layers. Additionally, a temporally-enhanced attention module captures long-range dependencies essential for AQA. Second, List-wise Contrastive Regularization (LCR) facilitates coarse-to-fine alignment by comprehensively comparing batch pairs to learn fine-grained cues while mitigating domain shift. Integrating these modules, PHI offers an effective solution. Experiments demonstrate that PHI achieves state-of-the-art performance on three representative long-term AQA datasets, proving its superiority in addressing the domain shift for long-term AQA.
Think Only When You Need with Large Hybrid-Reasoning Models
May 21, 2025Recent Large Reasoning Models (LRMs) have shown substantially improved reasoning capabilities over traditional Large Language Models (LLMs) by incorporating extended thinking processes prior to producing final responses. However, excessively lengthy thinking introduces substantial overhead in terms of token consumption and latency, which is particularly unnecessary for simple queries. In this work, we introduce Large Hybrid-Reasoning Models (LHRMs), the first kind of model capable of adaptively determining whether to perform thinking based on the contextual information of user queries. To achieve this, we propose a two-stage training pipeline comprising Hybrid Fine-Tuning (HFT) as a cold start, followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select the appropriate thinking mode. Furthermore, we introduce a metric called Hybrid Accuracy to quantitatively assess the model's capability for hybrid thinking. Extensive experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and type. It outperforms existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency. Together, our work advocates for a reconsideration of the appropriate use of extended thinking processes and provides a solid starting point for building hybrid thinking systems.
BitNet b1.58 2B4T Technical Report
Apr 16, 2025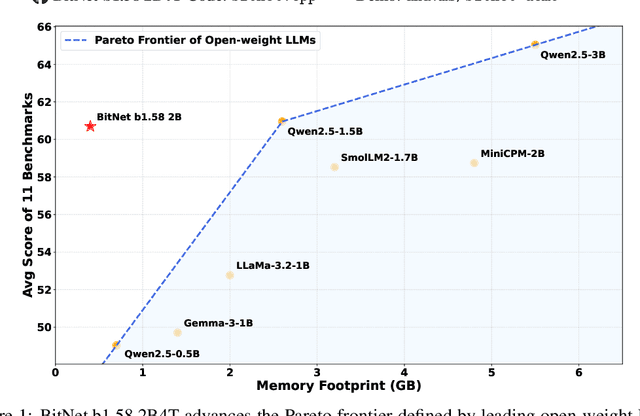
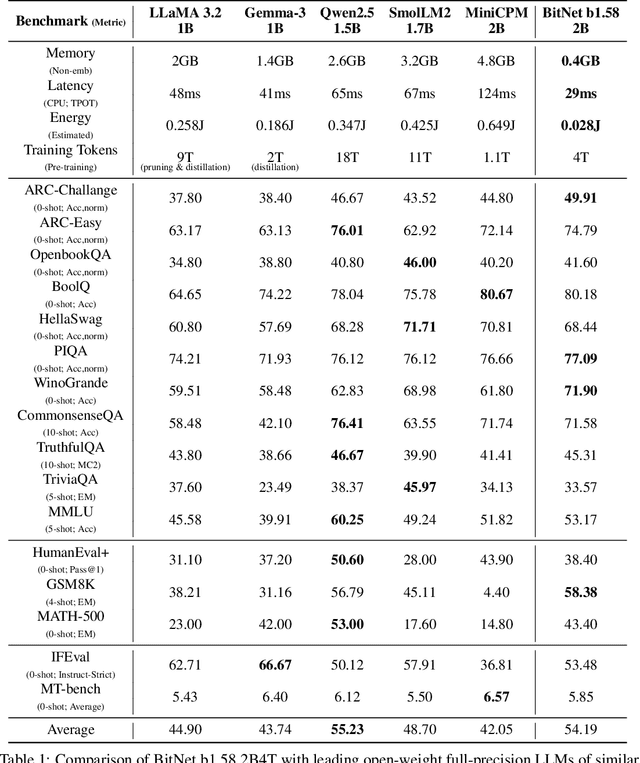
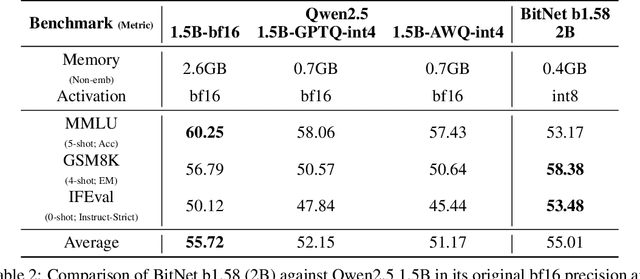
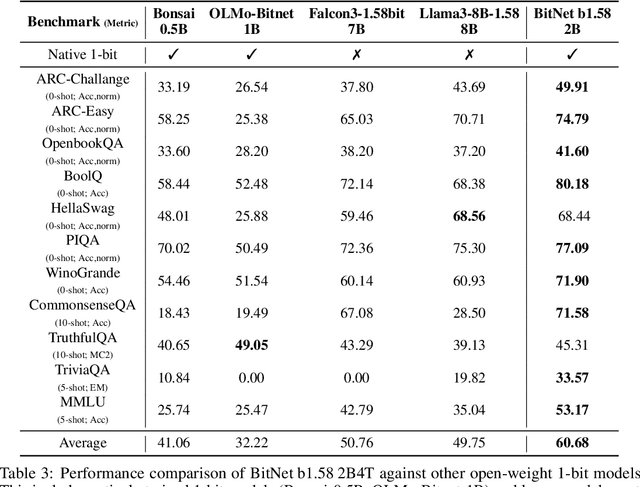
We introduce BitNet b1.58 2B4T, the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale. Trained on a corpus of 4 trillion tokens, the model has been rigorously evaluated across benchmarks covering language understanding, mathematical reasoning, coding proficiency, and conversational ability. Our results demonstrate that BitNet b1.58 2B4T achieves performance on par with leading open-weight, full-precision LLMs of similar size, while offering significant advantages in computational efficiency, including substantially reduced memory footprint, energy consumption, and decoding latency. To facilitate further research and adoption, the model weights are released via Hugging Face along with open-source inference implementations for both GPU and CPU architectures.
Scaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
One-shot In-context Part Segmentation
Mar 03, 2025



In this paper, we present the One-shot In-context Part Segmentation (OIParts) framework, designed to tackle the challenges of part segmentation by leveraging visual foundation models (VFMs). Existing training-based one-shot part segmentation methods that utilize VFMs encounter difficulties when faced with scenarios where the one-shot image and test image exhibit significant variance in appearance and perspective, or when the object in the test image is partially visible. We argue that training on the one-shot example often leads to overfitting, thereby compromising the model's generalization capability. Our framework offers a novel approach to part segmentation that is training-free, flexible, and data-efficient, requiring only a single in-context example for precise segmentation with superior generalization ability. By thoroughly exploring the complementary strengths of VFMs, specifically DINOv2 and Stable Diffusion, we introduce an adaptive channel selection approach by minimizing the intra-class distance for better exploiting these two features, thereby enhancing the discriminatory power of the extracted features for the fine-grained parts. We have achieved remarkable segmentation performance across diverse object categories. The OIParts framework not only eliminates the need for extensive labeled data but also demonstrates superior generalization ability. Through comprehensive experimentation on three benchmark datasets, we have demonstrated the superiority of our proposed method over existing part segmentation approaches in one-shot settings.
WildLong: Synthesizing Realistic Long-Context Instruction Data at Scale
Feb 23, 2025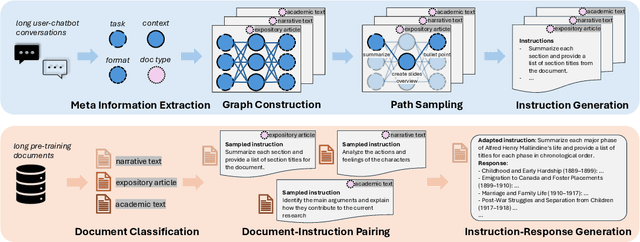
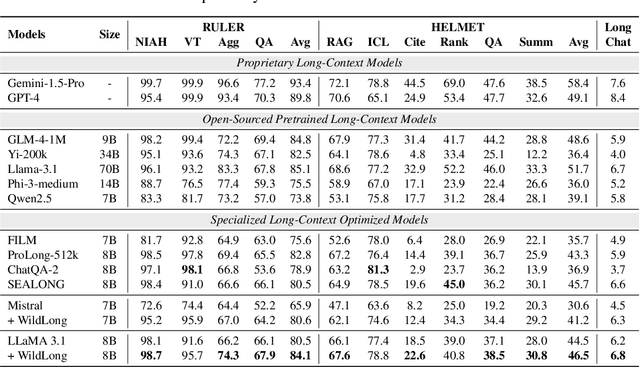
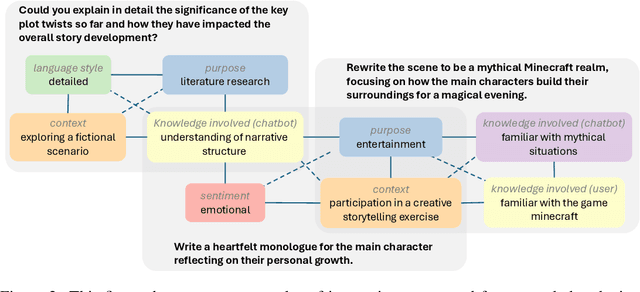
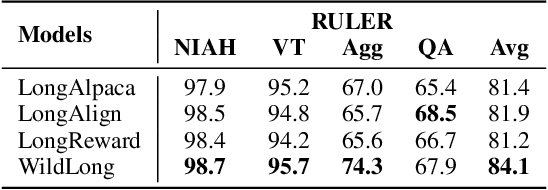
Large language models (LLMs) with extended context windows enable tasks requiring extensive information integration but are limited by the scarcity of high-quality, diverse datasets for long-context instruction tuning. Existing data synthesis methods focus narrowly on objectives like fact retrieval and summarization, restricting their generalizability to complex, real-world tasks. WildLong extracts meta-information from real user queries, models co-occurrence relationships via graph-based methods, and employs adaptive generation to produce scalable data. It extends beyond single-document tasks to support multi-document reasoning, such as cross-document comparison and aggregation. Our models, finetuned on 150K instruction-response pairs synthesized using WildLong, surpasses existing open-source long-context-optimized models across benchmarks while maintaining strong performance on short-context tasks without incorporating supplementary short-context data. By generating a more diverse and realistic long-context instruction dataset, WildLong enhances LLMs' ability to generalize to complex, real-world reasoning over long contexts, establishing a new paradigm for long-context data synthesis.
Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
Jan 19, 2025Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet they often rely on single-paradigm reasoning that limits their effectiveness across diverse tasks. In this paper, we introduce Chain-of-Reasoning (CoR), a novel unified framework that integrates multiple reasoning paradigms--Natural Language Reasoning (NLR), Algorithmic Reasoning (AR), and Symbolic Reasoning (SR)--to enable synergistic collaboration. CoR generates multiple potential answers using different reasoning paradigms and synthesizes them into a coherent final solution. We propose a Progressive Paradigm Training (PPT) strategy that allows models to progressively master these paradigms, culminating in the development of CoR-Math-7B. Experimental results demonstrate that CoR-Math-7B significantly outperforms current SOTA models, achieving up to a 41.0% absolute improvement over GPT-4 in theorem proving tasks and a 7.9% improvement over RL-based methods in arithmetic tasks. These results showcase the enhanced mathematical comprehensive ability of our model, achieving significant performance gains on specific tasks and enabling zero-shot generalization across tasks.