 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Supervised Fine-Tuning Needs to Unlock the Potential of Token Priority
Feb 01, 2026The transition from fitting empirical data to achieving true human utility is fundamentally constrained by a granularity mismatch, where fine-grained autoregressive generation is often supervised by coarse or uniform signals. This position paper advocates Token Priority as the essential bridge, formalizing Supervised Fine-Tuning (SFT) not as simple optimization but as a precise distribution reshaping process that aligns raw data with the ideal alignment manifold. We analyze recent breakthroughs through this unified lens, categorizing them into two distinct regimes: Positive Priority for noise filtration and Signed Priority for toxic modes unlearning. We revisit existing progress and limitations, identify key challenges, and suggest directions for future research.
Training-Trajectory-Aware Token Selection
Jan 15, 2026Efficient distillation is a key pathway for converting expensive reasoning capability into deployable efficiency, yet in the frontier regime where the student already has strong reasoning ability, naive continual distillation often yields limited gains or even degradation. We observe a characteristic training phenomenon: even as loss decreases monotonically, all performance metrics can drop sharply at almost the same bottleneck, before gradually recovering. We further uncover a token-level mechanism: confidence bifurcates into steadily increasing Imitation-Anchor Tokens that quickly anchor optimization and other yet-to-learn tokens whose confidence is suppressed until after the bottleneck. And the characteristic that these two types of tokens cannot coexist is the root cause of the failure in continual distillation. To this end, we propose Training-Trajectory-Aware Token Selection (T3S) to reconstruct the training objective at the token level, clearing the optimization path for yet-to-learn tokens. T3 yields consistent gains in both AR and dLLM settings: with only hundreds of examples, Qwen3-8B surpasses DeepSeek-R1 on competitive reasoning benchmarks, Qwen3-32B approaches Qwen3-235B, and T3-trained LLaDA-2.0-Mini exceeds its AR baseline, achieving state-of-the-art performance among all of 16B-scale no-think models.
Reasoning Path Divergence: A New Metric and Curation Strategy to Unlock LLM Diverse Thinking
Oct 30, 2025While Test-Time Scaling (TTS) has proven effective in improving the reasoning ability of large language models (LLMs), low diversity in model outputs often becomes a bottleneck; this is partly caused by the common "one problem, one solution" (1P1S) training practice, which provides a single canonical answer and can push models toward a narrow set of reasoning paths. To address this, we propose a "one problem, multiple solutions" (1PNS) training paradigm that exposes the model to a variety of valid reasoning trajectories and thus increases inference diversity. A core challenge for 1PNS is reliably measuring semantic differences between multi-step chains of thought, so we introduce Reasoning Path Divergence (RPD), a step-level metric that aligns and scores Long Chain-of-Thought solutions to capture differences in intermediate reasoning. Using RPD, we curate maximally diverse solution sets per problem and fine-tune Qwen3-4B-Base. Experiments show that RPD-selected training yields more varied outputs and higher pass@k, with an average +2.80% gain in pass@16 over a strong 1P1S baseline and a +4.99% gain on AIME24, demonstrating that 1PNS further amplifies the effectiveness of TTS. Our code is available at https://github.com/fengjujf/Reasoning-Path-Divergence .
Merge-of-Thought Distillation
Sep 10, 2025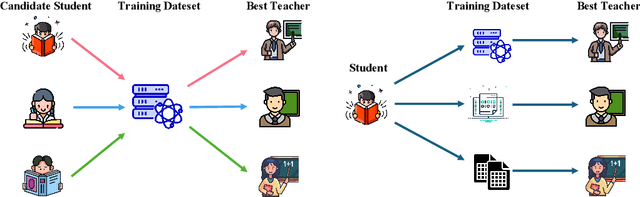
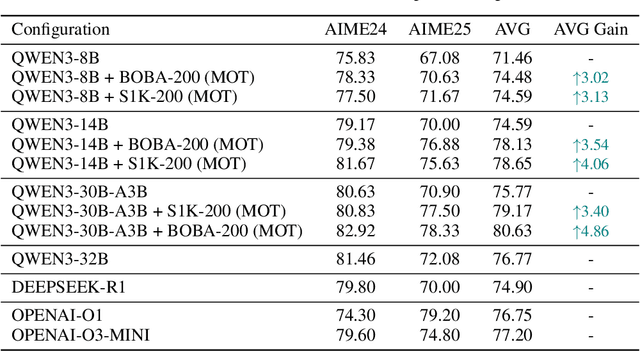
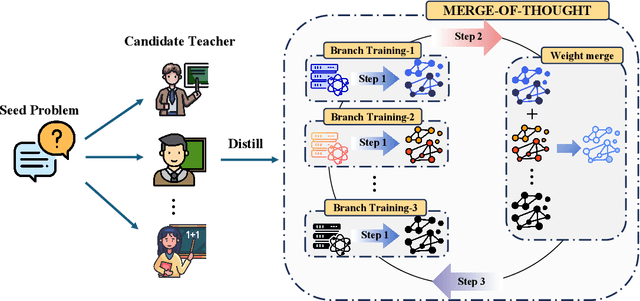

Efficient reasoning distillation for long chain-of-thought (CoT) models is increasingly constrained by the assumption of a single oracle teacher, despite practical availability of multiple candidate teachers and growing CoT corpora. We revisit teacher selection and observe that different students have different "best teachers," and even for the same student the best teacher can vary across datasets. Therefore, to unify multiple teachers' reasoning abilities into student with overcoming conflicts among various teachers' supervision, we propose Merge-of-Thought Distillation (MoT), a lightweight framework that alternates between teacher-specific supervised fine-tuning branches and weight-space merging of the resulting student variants. On competition math benchmarks, using only about 200 high-quality CoT samples, applying MoT to a Qwen3-14B student surpasses strong models including DEEPSEEK-R1, QWEN3-30B-A3B, QWEN3-32B, and OPENAI-O1, demonstrating substantial gains. Besides, MoT consistently outperforms the best single-teacher distillation and the naive multi-teacher union, raises the performance ceiling while mitigating overfitting, and shows robustness to distribution-shifted and peer-level teachers. Moreover, MoT reduces catastrophic forgetting, improves general reasoning beyond mathematics and even cultivates a better teacher, indicating that consensus-filtered reasoning features transfer broadly. These results position MoT as a simple, scalable route to efficiently distilling long CoT capabilities from diverse teachers into compact students.
Quality-Diversity Red-Teaming: Automated Generation of High-Quality and Diverse Attackers for Large Language Models
Jun 08, 2025Ensuring safety of large language models (LLMs) is important. Red teaming--a systematic approach to identifying adversarial prompts that elicit harmful responses from target LLMs--has emerged as a crucial safety evaluation method. Within this framework, the diversity of adversarial prompts is essential for comprehensive safety assessments. We find that previous approaches to red-teaming may suffer from two key limitations. First, they often pursue diversity through simplistic metrics like word frequency or sentence embedding similarity, which may not capture meaningful variation in attack strategies. Second, the common practice of training a single attacker model restricts coverage across potential attack styles and risk categories. This paper introduces Quality-Diversity Red-Teaming (QDRT), a new framework designed to address these limitations. QDRT achieves goal-driven diversity through behavior-conditioned training and implements a behavioral replay buffer in an open-ended manner. Additionally, it trains multiple specialized attackers capable of generating high-quality attacks across diverse styles and risk categories. Our empirical evaluation demonstrates that QDRT generates attacks that are both more diverse and more effective against a wide range of target LLMs, including GPT-2, Llama-3, Gemma-2, and Qwen2.5. This work advances the field of LLM safety by providing a systematic and effective approach to automated red-teaming, ultimately supporting the responsible deployment of LLMs.
Lifelong Safety Alignment for Language Models
May 26, 2025



LLMs have made impressive progress, but their growing capabilities also expose them to highly flexible jailbreaking attacks designed to bypass safety alignment. While many existing defenses focus on known types of attacks, it is more critical to prepare LLMs for unseen attacks that may arise during deployment. To address this, we propose a lifelong safety alignment framework that enables LLMs to continuously adapt to new and evolving jailbreaking strategies. Our framework introduces a competitive setup between two components: a Meta-Attacker, trained to actively discover novel jailbreaking strategies, and a Defender, trained to resist them. To effectively warm up the Meta-Attacker, we first leverage the GPT-4o API to extract key insights from a large collection of jailbreak-related research papers. Through iterative training, the first iteration Meta-Attacker achieves a 73% attack success rate (ASR) on RR and a 57% transfer ASR on LAT using only single-turn attacks. Meanwhile, the Defender progressively improves its robustness and ultimately reduces the Meta-Attacker's success rate to just 7%, enabling safer and more reliable deployment of LLMs in open-ended environments. The code is available at https://github.com/sail-sg/LifelongSafetyAlignment.
Does Representation Intervention Really Identify Desired Concepts and Elicit Alignment?
May 24, 2025Representation intervention aims to locate and modify the representations that encode the underlying concepts in Large Language Models (LLMs) to elicit the aligned and expected behaviors. Despite the empirical success, it has never been examined whether one could locate the faithful concepts for intervention. In this work, we explore the question in safety alignment. If the interventions are faithful, the intervened LLMs should erase the harmful concepts and be robust to both in-distribution adversarial prompts and the out-of-distribution (OOD) jailbreaks. While it is feasible to erase harmful concepts without degrading the benign functionalities of LLMs in linear settings, we show that it is infeasible in the general non-linear setting. To tackle the issue, we propose Concept Concentration (COCA). Instead of identifying the faithful locations to intervene, COCA refractors the training data with an explicit reasoning process, which firstly identifies the potential unsafe concepts and then decides the responses. Essentially, COCA simplifies the decision boundary between harmful and benign representations, enabling more effective linear erasure. Extensive experiments with multiple representation intervention methods and model architectures demonstrate that COCA significantly reduces both in-distribution and OOD jailbreak success rates, and meanwhile maintaining strong performance on regular tasks such as math and code generation.
Scaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
Leveraging Reasoning with Guidelines to Elicit and Utilize Knowledge for Enhancing Safety Alignment
Feb 06, 2025



Training safe LLMs is one of the most critical research challenge. However, the commonly used method, Refusal Training (RT), struggles to generalize against various OOD jailbreaking attacks. Many safety training methods have been proposed to address this issue. While they offer valuable insights, we aim to complement this line of research by investigating whether OOD attacks truly exceed the capability of RT model. Conducting evaluation with BoN, we observe significant improvements on generalization as N increases. This underscores that the model possesses sufficient safety-related latent knowledge, but RT fails to consistently elicit this knowledge when addressing OOD attacks. Further analysis based on domain adaptation reveals that training with direct refusal causes model to rely on superficial shortcuts, resulting in learning of non-robust representation mappings. Based on our findings, we propose training model to perform safety reasoning for each query. Reasoning supervision encourages model to perform more computations, explicitly eliciting and using latent knowledge through reasoning. To achieve this, we synthesize reasoning supervision based on pre-guidelines, training the model to reason in alignment with them, thereby effectively eliciting and utilizing latent knowledge from diverse perspectives. Extensive experiments show that our method significantly improves generalization performance against OOD attacks.