 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelaxation-Free Min-k-Partition for PCI Assignment in 5G Networks
Jun 12, 2025Physical Cell Identity (PCI) is a critical parameter in 5G networks. Efficient and accurate PCI assignment is essential for mitigating mod-3 interference, mod-30 interference, collisions, and confusions among cells, which directly affect network reliability and user experience. In this paper, we propose a novel framework for PCI assignment by decomposing the problem into Min-3-Partition, Min-10-Partition, and a graph coloring problem, leveraging the Chinese Remainder Theorem (CRT). Furthermore, we develop a relaxation-free approach to the general Min-$k$-Partition problem by reformulating it as a quadratic program with a norm-equality constraint and solving it using a penalized mirror descent (PMD) algorithm. The proposed method demonstrates superior computational efficiency and scalability, significantly reducing interference while eliminating collisions and confusions in large-scale 5G networks. Numerical evaluations on real-world datasets show that our approach reduces computational time by up to 20 times compared to state-of-the-art methods, making it highly practical for real-time PCI optimization in large-scale networks. These results highlight the potential of our method to improve network performance and reduce deployment costs in modern 5G systems.
$XX^{t}$ Can Be Faster
May 14, 2025



We present a new algorithm RXTX that computes product of matrix by its transpose $XX^{t}$. RXTX uses $5\%$ less multiplications and additions than State-of-the-Art and achieves accelerations even for small sizes of matrix $X$. The algorithm was discovered by combining Machine Learning-based search methods with Combinatorial Optimization.
Towards Quantifying the Hessian Structure of Neural Networks
May 05, 2025Empirical studies reported that the Hessian matrix of neural networks (NNs) exhibits a near-block-diagonal structure, yet its theoretical foundation remains unclear. In this work, we reveal two forces that shape the Hessian structure: a ``static force'' rooted in the architecture design, and a ``dynamic force'' arisen from training. We then provide a rigorous theoretical analysis of ``static force'' at random initialization. We study linear models and 1-hidden-layer networks with the mean-square (MSE) loss and the Cross-Entropy (CE) loss for classification tasks. By leveraging random matrix theory, we compare the limit distributions of the diagonal and off-diagonal Hessian blocks and find that the block-diagonal structure arises as $C \rightarrow \infty$, where $C$ denotes the number of classes. Our findings reveal that $C$ is a primary driver of the near-block-diagonal structure. These results may shed new light on the Hessian structure of large language models (LLMs), which typically operate with a large $C$ exceeding $10^4$ or $10^5$.
Exploring the Generalization Capabilities of AID-based Bi-level Optimization
Nov 25, 2024Bi-level optimization has achieved considerable success in contemporary machine learning applications, especially for given proper hyperparameters. However, due to the two-level optimization structure, commonly, researchers focus on two types of bi-level optimization methods: approximate implicit differentiation (AID)-based and iterative differentiation (ITD)-based approaches. ITD-based methods can be readily transformed into single-level optimization problems, facilitating the study of their generalization capabilities. In contrast, AID-based methods cannot be easily transformed similarly but must stay in the two-level structure, leaving their generalization properties enigmatic. In this paper, although the outer-level function is nonconvex, we ascertain the uniform stability of AID-based methods, which achieves similar results to a single-level nonconvex problem. We conduct a convergence analysis for a carefully chosen step size to maintain stability. Combining the convergence and stability results, we give the generalization ability of AID-based bi-level optimization methods. Furthermore, we carry out an ablation study of the parameters and assess the performance of these methods on real-world tasks. Our experimental results corroborate the theoretical findings, demonstrating the effectiveness and potential applications of these methods.
Hermes: A Large Language Model Framework on the Journey to Autonomous Networks
Nov 10, 2024



The drive toward automating cellular network operations has grown with the increasing complexity of these systems. Despite advancements, full autonomy currently remains out of reach due to reliance on human intervention for modeling network behaviors and defining policies to meet target requirements. Network Digital Twins (NDTs) have shown promise in enhancing network intelligence, but the successful implementation of this technology is constrained by use case-specific architectures, limiting its role in advancing network autonomy. A more capable network intelligence, or "telecommunications brain", is needed to enable seamless, autonomous management of cellular network. Large Language Models (LLMs) have emerged as potential enablers for this vision but face challenges in network modeling, especially in reasoning and handling diverse data types. To address these gaps, we introduce Hermes, a chain of LLM agents that uses "blueprints" for constructing NDT instances through structured and explainable logical steps. Hermes allows automatic, reliable, and accurate network modeling of diverse use cases and configurations, thus marking progress toward fully autonomous network operations.
QoS-Aware and Routing-Flexible Network Slicing for Service-Oriented Networks
Sep 20, 2024

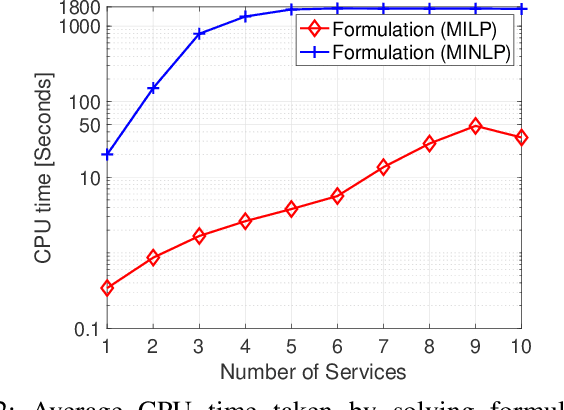

In this paper, we consider the network slicing (NS) problem which attempts to map multiple customized virtual network requests (also called services) to a common shared network infrastructure and manage network resources to meet diverse quality of service (QoS) requirements. We propose a mixed-integer nonlinear programming (MINLP) formulation for the considered NS problem that can flexibly route the traffic flow of the services on multiple paths and provide end-to-end delay and reliability guarantees for all services. To overcome the computational difficulty due to the intrinsic nonlinearity in the MINLP formulation, we transform the MINLP formulation into an equivalent mixed-integer linear programming (MILP) formulation and further show that their continuous relaxations are equivalent. In sharp contrast to the continuous relaxation of the MINLP formulation which is a nonconvex nonlinear programming problem, the continuous relaxation of the MILP formulation is a polynomial-time solvable linear programming problem, which significantly facilitates the algorithmic design. Based on the newly proposed MILP formulation, we develop a customized column generation (cCG) algorithm for solving the NS problem. The proposed cCG algorithm is a decomposition-based algorithm and is particularly suitable for solving large-scale NS problems. Numerical results demonstrate the efficacy of the proposed formulations and the proposed cCG algorithm.
Enhancing Multi-Stream Beamforming Through CQIs For 5G NR FDD Massive MIMO Communications: A Tuning-Free Scheme
Sep 01, 2024In the fifth-generation new radio (5G NR) frequency division duplex (FDD) massive multiple-input and multiple-output (MIMO) systems, downlink beamforming relies on the acquisition of downlink channel state information (CSI). Codebook based limited feedback schemes have been proposed and widely used in practice to recover the downlink CSI with low communication overhead. In such schemes, the performance of downlink beamforming is determined by the codebook design and the codebook indicator feedback. However, limited by the quantization quality of the codebook, directly utilizing the codeword indicated by the feedback as the beamforming vector cannot achieve high performance. Therefore, other feedback values, such as channel qualification indicator (CQI), should be considered to enhance beamforming. In this paper, we present the relation between CQI and the optimal beamforming vectors, based on which an empirical Bayes based intelligent tuning-free algorithm is devised to learn the optimal beamforming vector and the associated regularization parameter. The proposed algorithm can handle different communication scenarios of MIMO systems, including single stream and multiple streams data transmission scenarios. Numerical results have shown the excellent performance of the proposed algorithm in terms of both beamforming vector acquisition and regularization parameter learning.
Entropic Distribution Matching in Supervised Fine-tuning of LLMs: Less Overfitting and Better Diversity
Aug 29, 2024Large language models rely on Supervised Fine-Tuning (SFT) to specialize in downstream tasks. Cross Entropy (CE) loss is the de facto choice in SFT, but it often leads to overfitting and limited output diversity due to its aggressive updates to the data distribution. This paper aim to address these issues by introducing the maximum entropy principle, which favors models with flatter distributions that still effectively capture the data. Specifically, we develop a new distribution matching method called GEM, which solves reverse Kullback-Leibler divergence minimization with an entropy regularizer. For the SFT of Llama-3-8B models, GEM outperforms CE in several aspects. First, when applied to the UltraFeedback dataset to develop general instruction-following abilities, GEM exhibits reduced overfitting, evidenced by lower perplexity and better performance on the IFEval benchmark. Furthermore, GEM enhances output diversity, leading to performance gains of up to 7 points on math reasoning and code generation tasks using best-of-n sampling, even without domain-specific data. Second, when fine-tuning with domain-specific datasets for math reasoning and code generation, GEM also shows less overfitting and improvements of up to 10 points compared with CE.
Adaptive Foundation Models for Online Decisions: HyperAgent with Fast Incremental Uncertainty Estimation
Jul 18, 2024Foundation models often struggle with uncertainty when faced with new situations in online decision-making, necessitating scalable and efficient exploration to resolve this uncertainty. We introduce GPT-HyperAgent, an augmentation of GPT with HyperAgent for uncertainty-aware, scalable exploration in contextual bandits, a fundamental online decision problem involving natural language input. We prove that HyperAgent achieves fast incremental uncertainty estimation with $\tilde{O}(\log T)$ per-step computational complexity over $T$ periods under the linear realizable assumption. Our analysis demonstrates that HyperAgent's regret order matches that of exact Thompson sampling in linear contextual bandits, closing a significant theoretical gap in scalable exploration. Empirical results in real-world contextual bandit tasks, such as automated content moderation with human feedback, validate the practical effectiveness of GPT-HyperAgent for safety-critical decisions. Our code is open-sourced at \url{https://github.com/szrlee/GPT-HyperAgent/}.
Blind Beamforming for Coverage Enhancement with Intelligent Reflecting Surface
Jul 17, 2024



Conventional policy for configuring an intelligent reflecting surface (IRS) typically requires channel state information (CSI), thus incurring substantial overhead costs and facing incompatibility with the current network protocols. This paper proposes a blind beamforming strategy in the absence of CSI, aiming to boost the minimum signal-to-noise ratio (SNR) among all the receiver positions, namely the coverage enhancement. Although some existing works already consider the IRS-assisted coverage enhancement without CSI, they assume certain position-channel models through which the channels can be recovered from the geographic locations. In contrast, our approach solely relies on the received signal power data, not assuming any position-channel model. We examine the achievability and converse of the proposed blind beamforming method. If the IRS has $N$ reflective elements and there are $U$ receiver positions, then our method guarantees the minimum SNR of $\Omega(N^2/U)$ -- which is fairly close to the upper bound $O(N+N^2\sqrt{\ln (NU)}/\sqrt[4]{U})$. Aside from the simulation results, we justify the practical use of blind beamforming in a field test at 2.6 GHz. According to the real-world experiment, the proposed blind beamforming method boosts the minimum SNR across seven random positions in a conference room by 18.22 dB, while the position-based method yields a boost of 12.08 dB.