 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional Programming for Kullback-Leibler Divergence in Hypothesis Testing
Jan 02, 2026Maximizing the Kullback-Leibler divergence (KLD) is a fundamental problem in waveform design for active sensing and hypothesis testing, as it directly relates to the error exponent of detection probability. However, the associated optimization problem is highly nonconvex due to the intricate coupling of log-determinant and matrix trace terms. Existing solutions often suffer from high computational complexity, typically requiring matrix inversion at every iteration. In this paper, we propose a computationally efficient optimization framework based on fractional programming (FP). Our key idea is to reformulate the KLD maximization problem into a sequence of tractable quadratic subproblems using matrix FP. To further reduce complexity, we introduce a nonhomogeneous relaxation technique that replaces the costly linear system solver with a simple closed-form update, thereby reducing the per-iteration complexity to quadratic order. To compensate for the convergence speed trade-off caused by relaxation, we employ an acceleration method called STEM by interpreting the iterative scheme as a fixed-point mapping. The resulting algorithm achieves significantly faster convergence rates with low per-iteration cost. Numerical results demonstrate that our approach reduces the total runtime by orders of magnitude compared to a state-of-the-art benchmark. Finally, we apply the proposed framework to a multiple random access scenario and a joint integrated sensing and communication scenario, validating the efficacy of our framework in such applications.
Uplink Coordinated Pilot Design for 1-bit Massive MIMO in Correlated Channel
Feb 19, 2025In this paper, we propose a coordinated pilot design method to minimize the channel estimation mean squared error (MSE) in 1-bit analog-to-digital converters (ADCs) massive multiple-input multiple-output (MIMO). Under the assumption that the well-known Bussgang linear minimum mean square error (BLMMSE) estimator is used for channel estimation, we first observe that the resulting MSE leads to an intractable optimization problem, as it involves the arcsin function and a complex multiple matrix ratio form. To resolve this, we derive the approximate MSE by assuming the low signal-to-noise ratio (SNR) regime, by which we develop an efficient coordinated pilot design based on a fractional programming technique. The proposed pilot design is distinguishable from the existing work in that it is applicable in general system environments, including correlated channel and multi-cell environments. We demonstrate that the proposed method outperforms the channel estimation accuracy performance compared to the conventional approaches.
Intelligent Surface Assisted Radar Stealth Against Unauthorized ISAC
Jan 26, 2025The integration of radar sensors and communication networks as envisioned for the 6G wireless networks poses significant security risks, e.g., the user position information can be released to an unauthorized dual-functional base station (DFBS). To address this issue, we propose an intelligent surface (IS)-assisted radar stealth technology that prevents adversarial sensing. Specifically, we modify the wireless channels by tuning the phase shifts of IS in order to protect the target user from unauthorized sensing without jeopardizing the wireless communication link. In principle, we wish to maximize the distortion between the estimated angle-of-arrival (AoA) by the DFBS and the ground truth given the minimum signal-to-noise-radio (SNR) constraint for communication. Toward this end, we propose characterizing the problem as a game played by the DFBS and the IS, in which the DFBS aims to maximize a particular utility while the IS aims to minimize the utility. Although the problem is nonconvex, this paper shows that it can be optimally solved in closed form from a geometric perspective. According to the simulations, the proposed closed-form algorithm outperforms the baseline methods significantly in combating unauthorized sensing while limiting the impacts on wireless communications.
An Efficient Convex-Hull Relaxation Based Algorithm for Multi-User Discrete Passive Beamforming
Jul 30, 2024Intelligent reflecting surface (IRS) is an emerging technology to enhance spatial multiplexing in wireless networks. This letter considers the discrete passive beamforming design for IRS in order to maximize the minimum signal-to-interference-plus-noise ratio (SINR) among multiple users in an IRS-assisted downlink network. The main design difficulty lies in the discrete phase-shift constraint. Differing from most existing works, this letter advocates a convex-hull relaxation of the discrete constraints which leads to a continuous reformulated problem equivalent to the original discrete problem. This letter further proposes an efficient alternating projection/proximal gradient descent and ascent algorithm for solving the reformulated problem. Simulation results show that the proposed algorithm outperforms the state-of-the-art methods significantly.
* 5 pages
Blind Beamforming for Coverage Enhancement with Intelligent Reflecting Surface
Jul 17, 2024



Conventional policy for configuring an intelligent reflecting surface (IRS) typically requires channel state information (CSI), thus incurring substantial overhead costs and facing incompatibility with the current network protocols. This paper proposes a blind beamforming strategy in the absence of CSI, aiming to boost the minimum signal-to-noise ratio (SNR) among all the receiver positions, namely the coverage enhancement. Although some existing works already consider the IRS-assisted coverage enhancement without CSI, they assume certain position-channel models through which the channels can be recovered from the geographic locations. In contrast, our approach solely relies on the received signal power data, not assuming any position-channel model. We examine the achievability and converse of the proposed blind beamforming method. If the IRS has $N$ reflective elements and there are $U$ receiver positions, then our method guarantees the minimum SNR of $\Omega(N^2/U)$ -- which is fairly close to the upper bound $O(N+N^2\sqrt{\ln (NU)}/\sqrt[4]{U})$. Aside from the simulation results, we justify the practical use of blind beamforming in a field test at 2.6 GHz. According to the real-world experiment, the proposed blind beamforming method boosts the minimum SNR across seven random positions in a conference room by 18.22 dB, while the position-based method yields a boost of 12.08 dB.
SEMINAR: Search Enhanced Multi-modal Interest Network and Approximate Retrieval for Lifelong Sequential Recommendation
Jul 15, 2024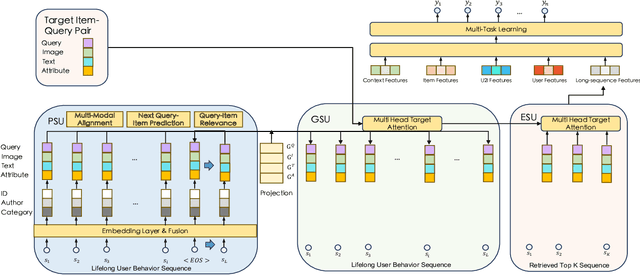

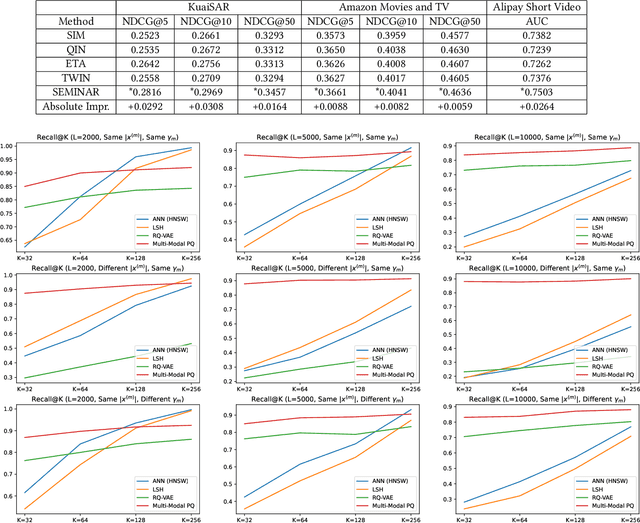
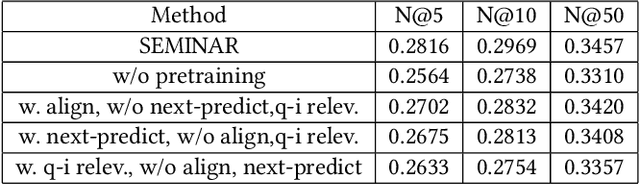
The modeling of users' behaviors is crucial in modern recommendation systems. A lot of research focuses on modeling users' lifelong sequences, which can be extremely long and sometimes exceed thousands of items. These models use the target item to search for the most relevant items from the historical sequence. However, training lifelong sequences in click through rate (CTR) prediction or personalized search ranking (PSR) is extremely difficult due to the insufficient learning problem of ID embedding, especially when the IDs in the lifelong sequence features do not exist in the samples of training dataset. Additionally, existing target attention mechanisms struggle to learn the multi-modal representations of items in the sequence well. The distribution of multi-modal embedding (text, image and attributes) output of user's interacted items are not properly aligned and there exist divergence across modalities. We also observe that users' search query sequences and item browsing sequences can fully depict users' intents and benefit from each other. To address these challenges, we propose a unified lifelong multi-modal sequence model called SEMINAR-Search Enhanced Multi-Modal Interest Network and Approximate Retrieval. Specifically, a network called Pretraining Search Unit (PSU) learns the lifelong sequences of multi-modal query-item pairs in a pretraining-finetuning manner with multiple objectives: multi-modal alignment, next query-item pair prediction, query-item relevance prediction, etc. After pretraining, the downstream model restores the pretrained embedding as initialization and finetunes the network. To accelerate the online retrieval speed of multi-modal embedding, we propose a multi-modal codebook-based product quantization strategy to approximate the exact attention calculati
Fast Fractional Programming for Multi-Cell Integrated Sensing and Communications
Jun 16, 2024



This paper concerns the coordinate multi-cell beamforming design for integrated sensing and communications (ISAC). In particular, we assume that each base station (BS) has massive antennas. The optimization objective is to maximize a weighted sum of the data rates (for communications) and the Fisher information (for sensing). We first show that the conventional beamforming method for the multiple-input multiple-output (MIMO) transmission, i.e., the weighted minimum mean square error (WMMSE) algorithm, has a natural extension to the ISAC problem scenario from a fractional programming (FP) perspective. However, the extended WMMSE algorithm requires computing the $N\times N$ matrix inverse extensively, where $N$ is proportional to the antenna array size, so the algorithm becomes quite costly when antennas are massively deployed. To address this issue, we develop a nonhomogeneous bound and use it in conjunction with the FP technique to solve the ISAC beamforming problem without the need to invert any large matrices. It is further shown that the resulting new FP algorithm has an intimate connection with gradient projection, based on which we can accelerate the convergence via Nesterov's gradient extrapolation.
Denoising Time Cycle Modeling for Recommendation
Feb 05, 2024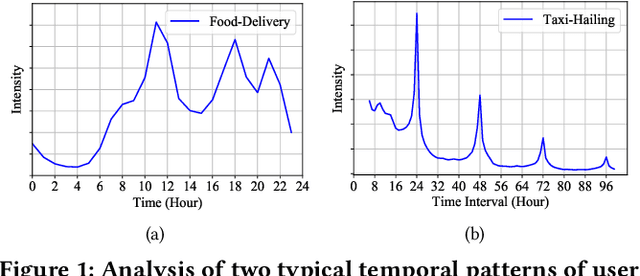
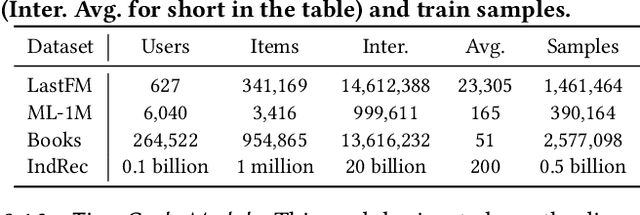
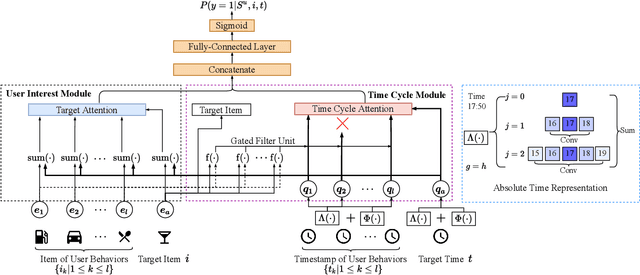
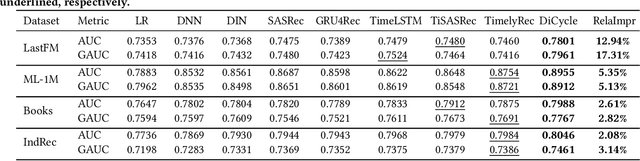
Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
Intelligent Surfaces Empowered Wireless Network: Recent Advances and The Road to 6G
Jan 15, 2024
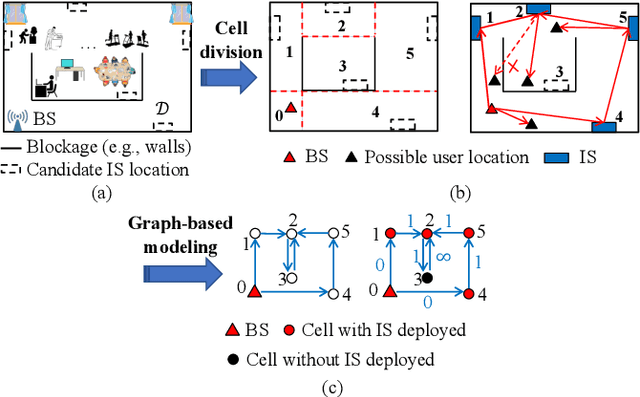
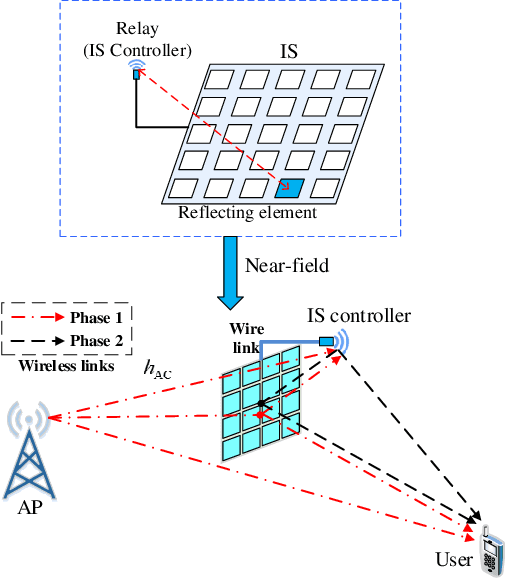
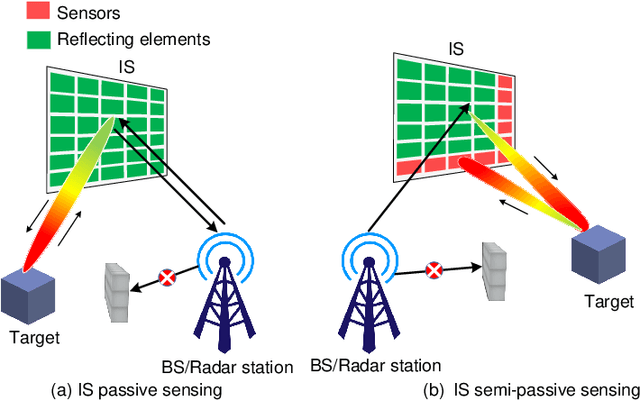
Intelligent surfaces (ISs) have emerged as a key technology to empower a wide range of appealing applications for wireless networks, due to their low cost, high energy efficiency, flexibility of deployment and capability of constructing favorable wireless channels/radio environments. Moreover, the recent advent of several new IS architectures further expanded their electromagnetic functionalities from passive reflection to active amplification, simultaneous reflection and refraction, as well as holographic beamforming. However, the research on ISs is still in rapid progress and there have been recent technological advances in ISs and their emerging applications that are worthy of a timely review. Thus, we provide in this paper a comprehensive survey on the recent development and advances of ISs aided wireless networks. Specifically, we start with an overview on the anticipated use cases of ISs in future wireless networks such as 6G, followed by a summary of the recent standardization activities related to ISs. Then, the main design issues of the commonly adopted reflection-based IS and their state-of-theart solutions are presented in detail, including reflection optimization, deployment, signal modulation, wireless sensing, and integrated sensing and communications. Finally, recent progress and new challenges in advanced IS architectures are discussed to inspire futrue research.
Discerning and Enhancing the Weighted Sum-Rate Maximization Algorithms in Communications
Nov 08, 2023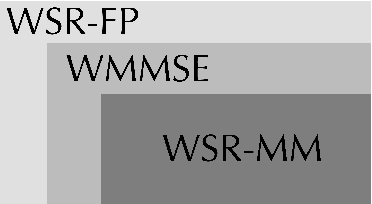
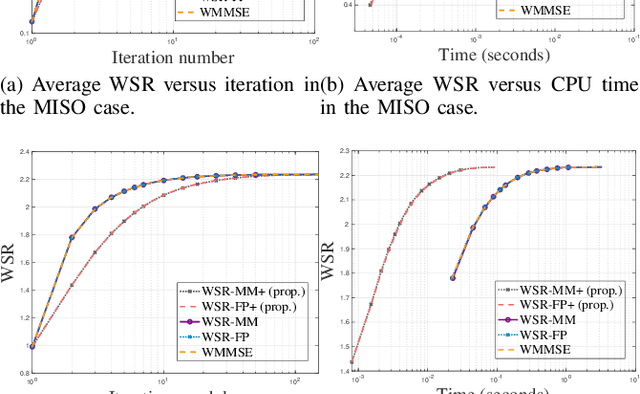
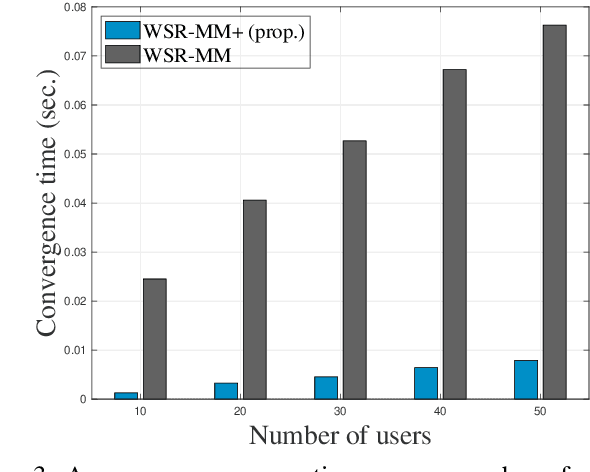
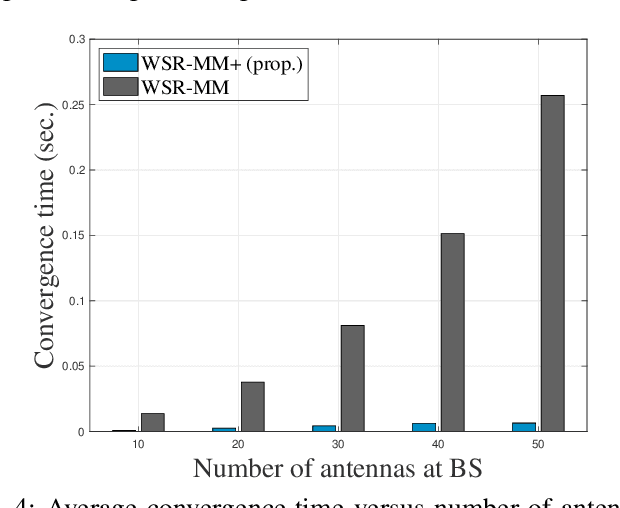
Weighted sum-rate (WSR) maximization plays a critical role in communication system design. This paper examines three optimization methods for WSR maximization, which ensure convergence to stationary points: two block coordinate ascent (BCA) algorithms, namely, weighted sum-minimum mean-square error (WMMSE) and WSR maximization via fractional programming (WSR-FP), along with a minorization-maximization (MM) algorithm, WSR maximization via MM (WSR-MM). Our contributions are threefold. Firstly, we delineate the exact relationships among WMMSE, WSR-FP, and WSR-MM, which, despite their extensive use in the literature, lack a comprehensive comparative study. By probing the theoretical underpinnings linking the BCA and MM algorithmic frameworks, we reveal the direct correlations between the equivalent transformation techniques, essential to the development of WMMSE and WSR-FP, and the surrogate functions pivotal to WSR-MM. Secondly, we propose a novel algorithm, WSR-MM+, harnessing the flexibility of selecting surrogate functions in MM framework. By circumventing the repeated matrix inversions in the search for optimal Lagrange multipliers in existing algorithms, WSR-MM+ significantly reduces the computational load per iteration and accelerates convergence. Thirdly, we reconceptualize WSR-MM+ within the BCA framework, introducing a new equivalent transform, which gives rise to an enhanced version of WSR-FP, named as WSR-FP+. We further demonstrate that WSR-MM+ can be construed as the basic gradient projection method. This perspective yields a deeper understanding into its computational intricacies. Numerical simulations corroborate the connections between WMMSE, WSR-FP, and WSR-MM and confirm the efficacy of the proposed WSR-MM+ and WSR-FP+ algorithms.