 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaSFormer: Adaptive Serialized Transformers for Monocular Semantic Scene Completion from Indoor Environments
Mar 26, 2026Indoor monocular semantic scene completion (MSSC) is notably more challenging than its outdoor counterpart due to complex spatial layouts and severe occlusions. While transformers are well suited for modeling global dependencies, their high memory cost and difficulty in reconstructing fine-grained details have limited their use in indoor MSSC. To address these limitations, we introduce AdaSFormer, a serialized transformer framework tailored for indoor MSSC. Our model features three key designs: (1) an Adaptive Serialized Transformer with learnable shifts that dynamically adjust receptive fields; (2) a Center-Relative Positional Encoding that captures spatial information richness; and (3) a Convolution-Modulated Layer Normalization that bridges heterogeneous representations between convolutional and transformer features. Extensive experiments on NYUv2 and Occ-ScanNet demonstrate that AdaSFormer achieves state-of-the-art performance. The code is publicly available at: https://github.com/alanWXZ/AdaSFormer.
Monocular Semantic Scene Completion via Masked Recurrent Networks
Jul 23, 2025Monocular Semantic Scene Completion (MSSC) aims to predict the voxel-wise occupancy and semantic category from a single-view RGB image. Existing methods adopt a single-stage framework that aims to simultaneously achieve visible region segmentation and occluded region hallucination, while also being affected by inaccurate depth estimation. Such methods often achieve suboptimal performance, especially in complex scenes. We propose a novel two-stage framework that decomposes MSSC into coarse MSSC followed by the Masked Recurrent Network. Specifically, we propose the Masked Sparse Gated Recurrent Unit (MS-GRU) which concentrates on the occupied regions by the proposed mask updating mechanism, and a sparse GRU design is proposed to reduce the computation cost. Additionally, we propose the distance attention projection to reduce projection errors by assigning different attention scores according to the distance to the observed surface. Experimental results demonstrate that our proposed unified framework, MonoMRN, effectively supports both indoor and outdoor scenes and achieves state-of-the-art performance on the NYUv2 and SemanticKITTI datasets. Furthermore, we conduct robustness analysis under various disturbances, highlighting the role of the Masked Recurrent Network in enhancing the model's resilience to such challenges. The source code is publicly available.
Discerning and Enhancing the Weighted Sum-Rate Maximization Algorithms in Communications
Nov 08, 2023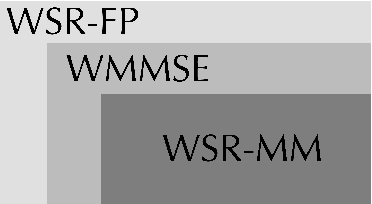
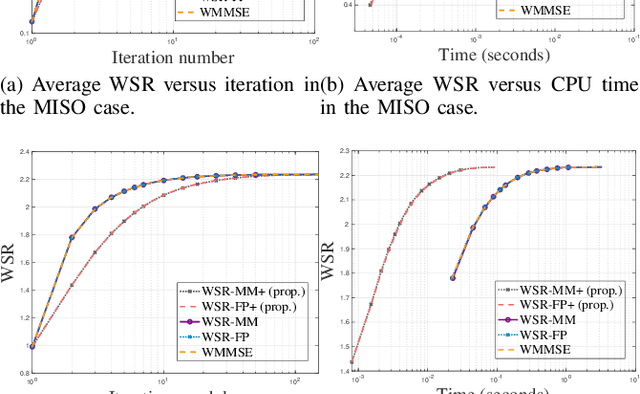
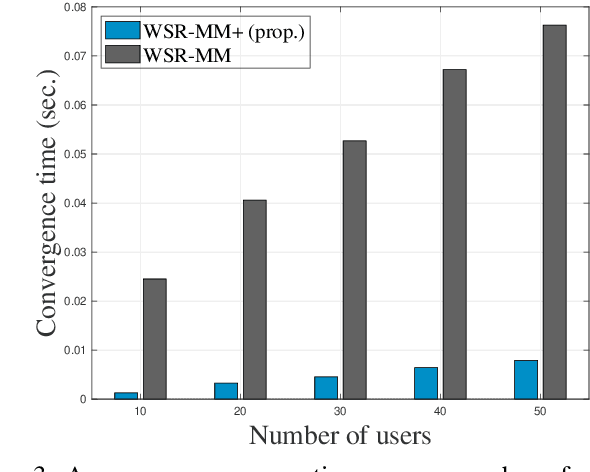
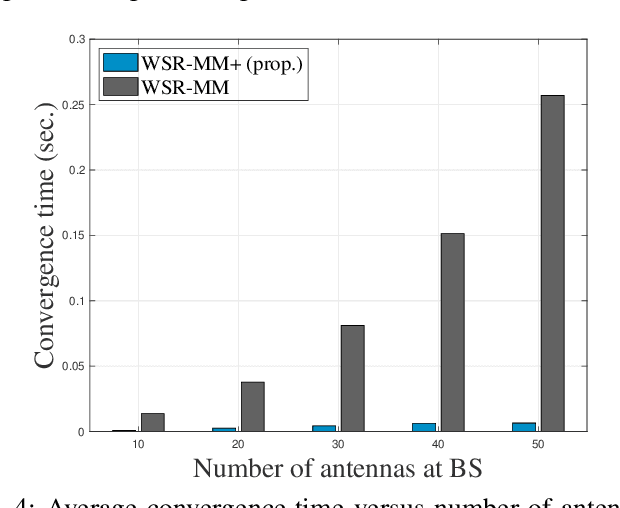
Weighted sum-rate (WSR) maximization plays a critical role in communication system design. This paper examines three optimization methods for WSR maximization, which ensure convergence to stationary points: two block coordinate ascent (BCA) algorithms, namely, weighted sum-minimum mean-square error (WMMSE) and WSR maximization via fractional programming (WSR-FP), along with a minorization-maximization (MM) algorithm, WSR maximization via MM (WSR-MM). Our contributions are threefold. Firstly, we delineate the exact relationships among WMMSE, WSR-FP, and WSR-MM, which, despite their extensive use in the literature, lack a comprehensive comparative study. By probing the theoretical underpinnings linking the BCA and MM algorithmic frameworks, we reveal the direct correlations between the equivalent transformation techniques, essential to the development of WMMSE and WSR-FP, and the surrogate functions pivotal to WSR-MM. Secondly, we propose a novel algorithm, WSR-MM+, harnessing the flexibility of selecting surrogate functions in MM framework. By circumventing the repeated matrix inversions in the search for optimal Lagrange multipliers in existing algorithms, WSR-MM+ significantly reduces the computational load per iteration and accelerates convergence. Thirdly, we reconceptualize WSR-MM+ within the BCA framework, introducing a new equivalent transform, which gives rise to an enhanced version of WSR-FP, named as WSR-FP+. We further demonstrate that WSR-MM+ can be construed as the basic gradient projection method. This perspective yields a deeper understanding into its computational intricacies. Numerical simulations corroborate the connections between WMMSE, WSR-FP, and WSR-MM and confirm the efficacy of the proposed WSR-MM+ and WSR-FP+ algorithms.
hierarchical network with decoupled knowledge distillation for speech emotion recognition
Mar 09, 2023The goal of Speech Emotion Recognition (SER) is to enable computers to recognize the emotion category of a given utterance in the same way that humans do. The accuracy of SER is strongly dependent on the validity of the utterance-level representation obtained by the model. Nevertheless, the ``dark knowledge" carried by non-target classes is always ignored by previous studies. In this paper, we propose a hierarchical network, called DKDFMH, which employs decoupled knowledge distillation in a deep convolutional neural network with a fused multi-head attention mechanism. Our approach applies logit distillation to obtain higher-level semantic features from different scales of attention sets and delve into the knowledge carried by non-target classes, thus guiding the model to focus more on the differences between sentiment features. To validate the effectiveness of our model, we conducted experiments on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset. We achieved competitive performance, with 79.1% weighted accuracy (WA) and 77.1% unweighted accuracy (UA). To the best of our knowledge, this is the first time since 2015 that logit distillation has been returned to state-of-the-art status.
ASGNN: Graph Neural Networks with Adaptive Structure
Oct 03, 2022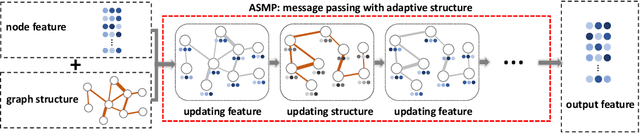
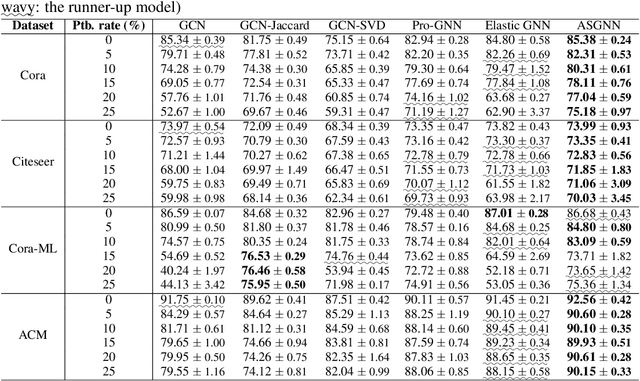
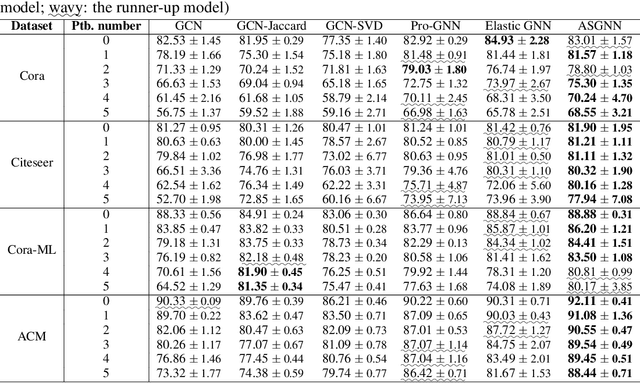
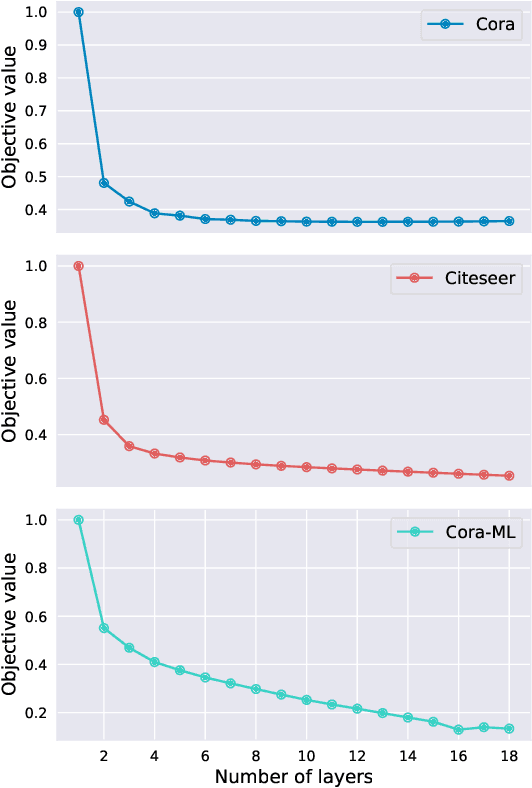
The graph neural network (GNN) models have presented impressive achievements in numerous machine learning tasks. However, many existing GNN models are shown to be vulnerable to adversarial attacks, which creates a stringent need to build robust GNN architectures. In this work, we propose a novel interpretable message passing scheme with adaptive structure (ASMP) to defend against adversarial attacks on graph structure. Layers in ASMP are derived based on optimization steps that minimize an objective function that learns the node feature and the graph structure simultaneously. ASMP is adaptive in the sense that the message passing process in different layers is able to be carried out over dynamically adjusted graphs. Such property allows more fine-grained handling of the noisy (or perturbed) graph structure and hence improves the robustness. Convergence properties of the ASMP scheme are theoretically established. Integrating ASMP with neural networks can lead to a new family of GNN models with adaptive structure (ASGNN). Extensive experiments on semi-supervised node classification tasks demonstrate that the proposed ASGNN outperforms the state-of-the-art GNN architectures in terms of classification performance under various adversarial attacks.
Towards Understanding Graph Neural Networks: An Algorithm Unrolling Perspective
Jun 09, 2022
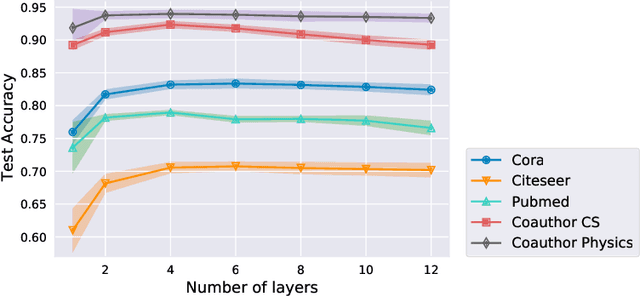
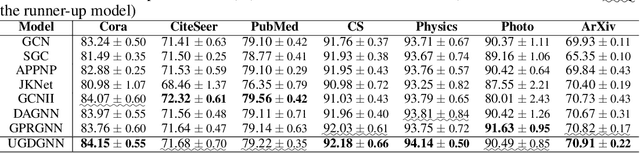
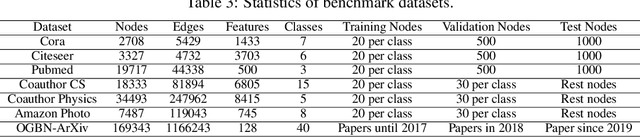
The graph neural network (GNN) has demonstrated its superior performance in various applications. The working mechanism behind it, however, remains mysterious. GNN models are designed to learn effective representations for graph-structured data, which intrinsically coincides with the principle of graph signal denoising (GSD). Algorithm unrolling, a "learning to optimize" technique, has gained increasing attention due to its prospects in building efficient and interpretable neural network architectures. In this paper, we introduce a class of unrolled networks built based on truncated optimization algorithms (e.g., gradient descent and proximal gradient descent) for GSD problems. They are shown to be tightly connected to many popular GNN models in that the forward propagations in these GNNs are in fact unrolled networks serving specific GSDs. Besides, the training process of a GNN model can be seen as solving a bilevel optimization problem with a GSD problem at the lower level. Such a connection brings a fresh view of GNNs, as we could try to understand their practical capabilities from their GSD counterparts, and it can also motivate designing new GNN models. Based on the algorithm unrolling perspective, an expressive model named UGDGNN, i.e., unrolled gradient descent GNN, is further proposed which inherits appealing theoretical properties. Extensive numerical simulations on seven benchmark datasets demonstrate that UGDGNN can achieve superior or competitive performance over the state-of-the-art models.
Weighted Sum-Rate Maximization for Multi-Hop RIS-Aided Multi-User Communications: A Minorization-Maximization Approach
May 08, 2021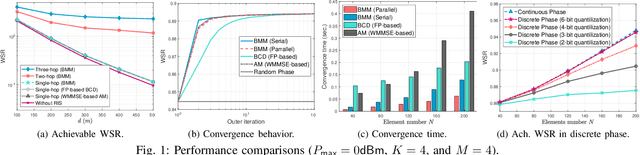
The reconfigurable intelligent surface (RIS) has aroused much research attention recently due to its potential benefits in 5G and beyond wireless networks. This paper considers a general multi-hop RIS-aided multi-user communication system and the weighted sum-rate maximization problem is studied by jointly designing the active beamforming matrix at the base station and multiple phase-shift matrices at the RISs (considering both continuous and discrete phase constraints). To tackle the resulting highly nonconvex optimization problem, a problem-tailored low-complexity and globally convergent algorithm based on block minorization-maximization (BMM) is proposed. The effectiveness of the proposed BMM approach and the performance improvement gained with multi-hop RISs are both demonstrated through numerical simulations. The merits of the proposed algorithms are further illustrated by indicating their adaptivity in solving many other RIS-related system designs.
Joint Design of Transmit Waveforms and Receive Filters for MIMO Radar via Manifold Optimization
Feb 10, 2021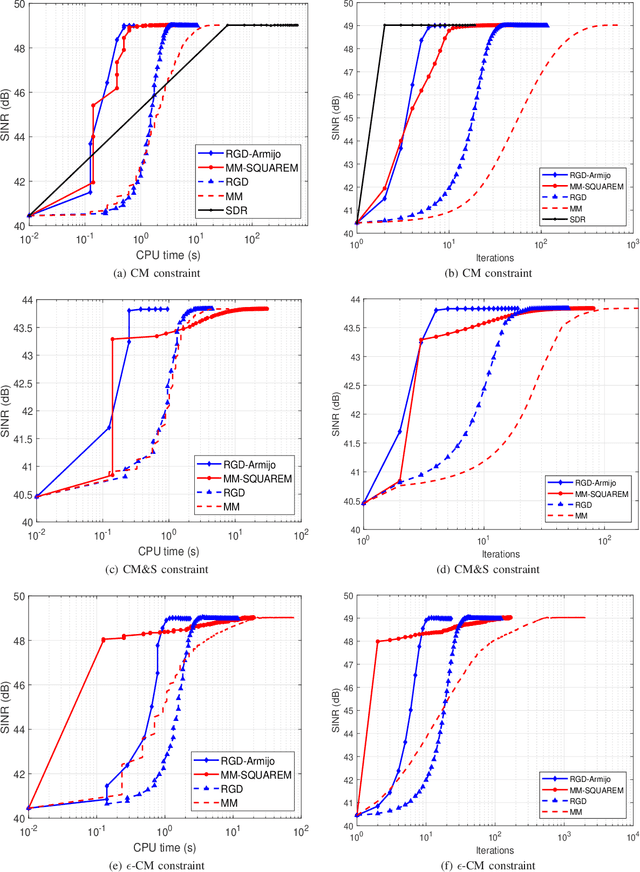
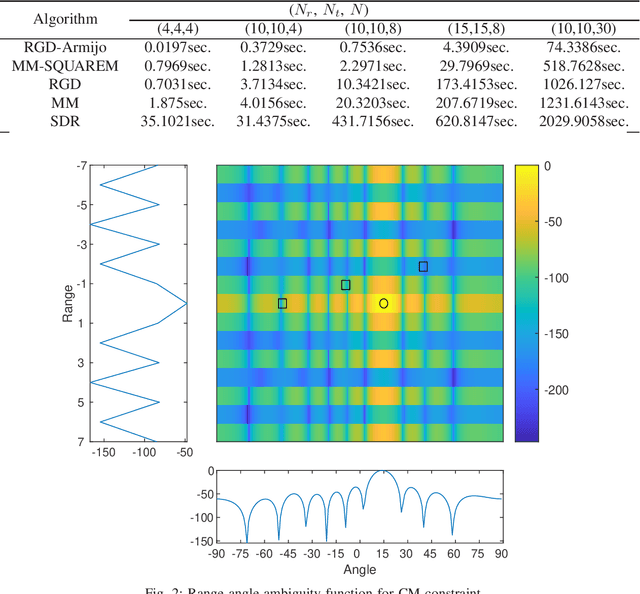
The problem of joint design of transmit waveforms and receive filters is desirable in many application scenarios of multiple-input multiple-output (MIMO) radar systems. In this paper, the joint design problem is investigated under the signal-to-interference-plus-noise ratio (SINR) performance metric, in which case the problem is formulated to maximize the SINR at the receiver side subject to some practical transmit waveform constraints. A numerical algorithm is proposed for problem resolution based on the manifold optimization method, which has been shown to be powerful and flexible to address nonconvex constrained optimization problems in many engineering applications. The proposed algorithm is able to efficiently solve the SINR maximization problem with different waveform constraints under a unified framework. Numerical experiments show that the proposed algorithm outperforms the existing benchmarks in terms of computation efficiency and achieves comparable SINR performance.
AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition
Jul 10, 2019
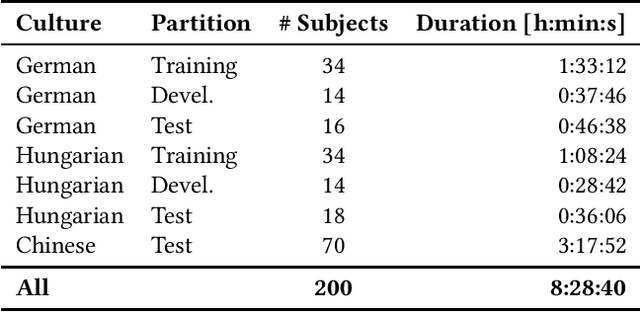
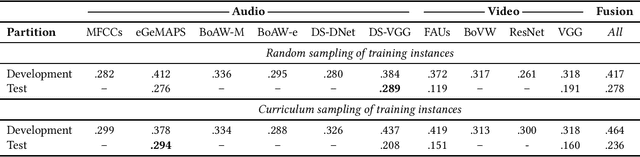
The Audio/Visual Emotion Challenge and Workshop (AVEC 2019) "State-of-Mind, Detecting Depression with AI, and Cross-cultural Affect Recognition" is the ninth competition event aimed at the comparison of multimedia processing and machine learning methods for automatic audiovisual health and emotion analysis, with all participants competing strictly under the same conditions. The goal of the Challenge is to provide a common benchmark test set for multimodal information processing and to bring together the health and emotion recognition communities, as well as the audiovisual processing communities, to compare the relative merits of various approaches to health and emotion recognition from real-life data. This paper presents the major novelties introduced this year, the challenge guidelines, the data used, and the performance of the baseline systems on the three proposed tasks: state-of-mind recognition, depression assessment with AI, and cross-cultural affect sensing, respectively.
Sparse Reduced Rank Regression With Nonconvex Regularization
Mar 20, 2018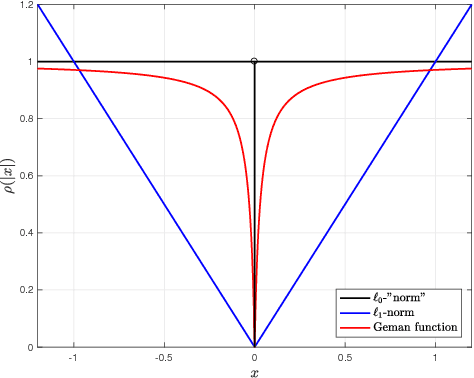

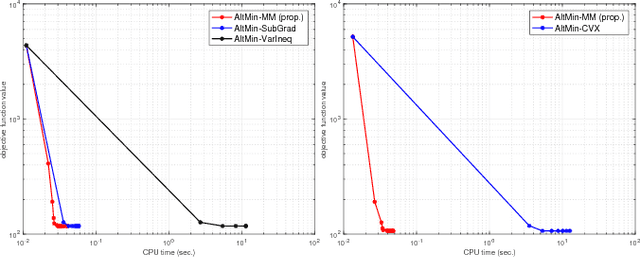

In this paper, the estimation problem for sparse reduced rank regression (SRRR) model is considered. The SRRR model is widely used for dimension reduction and variable selection with applications in signal processing, econometrics, etc. The problem is formulated to minimize the least squares loss with a sparsity-inducing penalty considering an orthogonality constraint. Convex sparsity-inducing functions have been used for SRRR in literature. In this work, a nonconvex function is proposed for better sparsity inducing. An efficient algorithm is developed based on the alternating minimization (or projection) method to solve the nonconvex optimization problem. Numerical simulations show that the proposed algorithm is much more efficient compared to the benchmark methods and the nonconvex function can result in a better estimation accuracy.