 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Cross-domain Voice Activity Detection with Self-Supervised Representations
Sep 22, 2022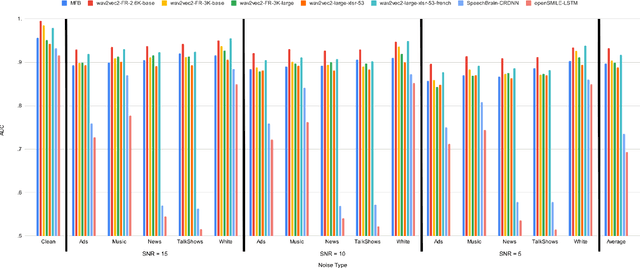
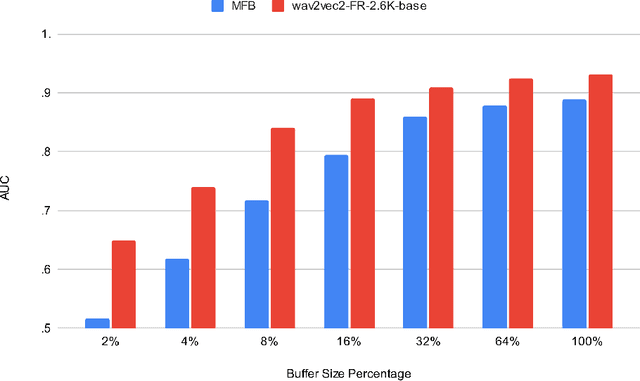
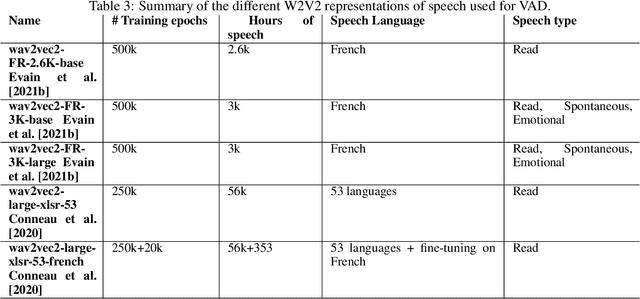
Voice Activity Detection (VAD) aims at detecting speech segments on an audio signal, which is a necessary first step for many today's speech based applications. Current state-of-the-art methods focus on training a neural network exploiting features directly contained in the acoustics, such as Mel Filter Banks (MFBs). Such methods therefore require an extra normalisation step to adapt to a new domain where the acoustics is impacted, which can be simply due to a change of speaker, microphone, or environment. In addition, this normalisation step is usually a rather rudimentary method that has certain limitations, such as being highly susceptible to the amount of data available for the new domain. Here, we exploited the crowd-sourced Common Voice (CV) corpus to show that representations based on Self-Supervised Learning (SSL) can adapt well to different domains, because they are computed with contextualised representations of speech across multiple domains. SSL representations also achieve better results than systems based on hand-crafted representations (MFBs), and off-the-shelf VADs, with significant improvement in cross-domain settings.
Dynamic Time-Alignment of Dimensional Annotations of Emotion using Recurrent Neural Networks
Sep 21, 2022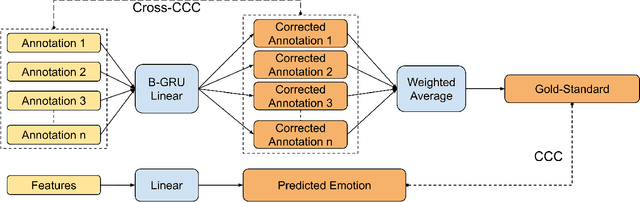

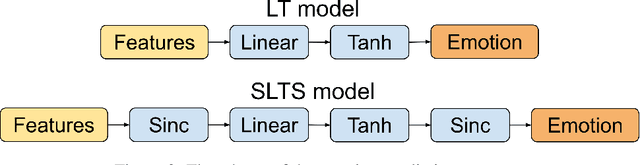
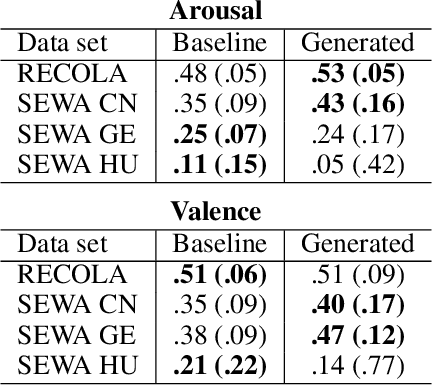
Most automatic emotion recognition systems exploit time-continuous annotations of emotion to provide fine-grained descriptions of spontaneous expressions as observed in real-life interactions. As emotion is rather subjective, its annotation is usually performed by several annotators who provide a trace for a given dimension, i.e. a time-continuous series describing a dimension such as arousal or valence. However, annotations of the same expression are rarely consistent between annotators, either in time or in value, which adds bias and delay in the trace that is used to learn predictive models of emotion. We therefore propose a method that can dynamically compensate inconsistencies across annotations and synchronise the traces with the corresponding acoustic features using Recurrent Neural Networks. Experimental evaluations were carried on several emotion data sets that include Chinese, French, German, and Hungarian participants who interacted remotely in either noise-free conditions or in-the-wild. The results show that our method can significantly increase inter-annotator agreement, as well as correlation between traces and audio features, for both arousal and valence. In addition, improvements are obtained in the automatic prediction of these dimensions using simple light-weight models, especially for valence in noise-free conditions, and arousal for recordings captured in-the-wild.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021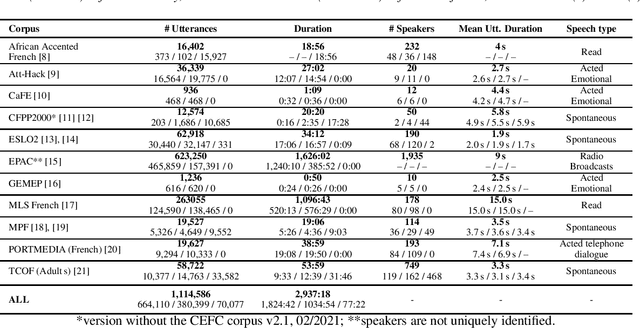
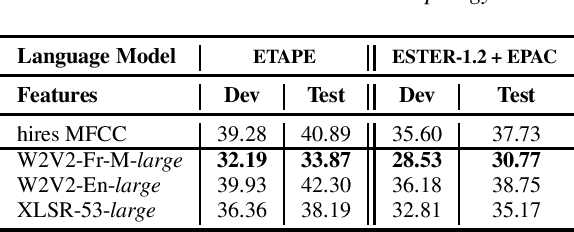
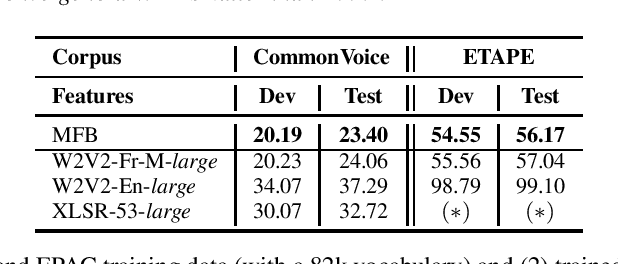
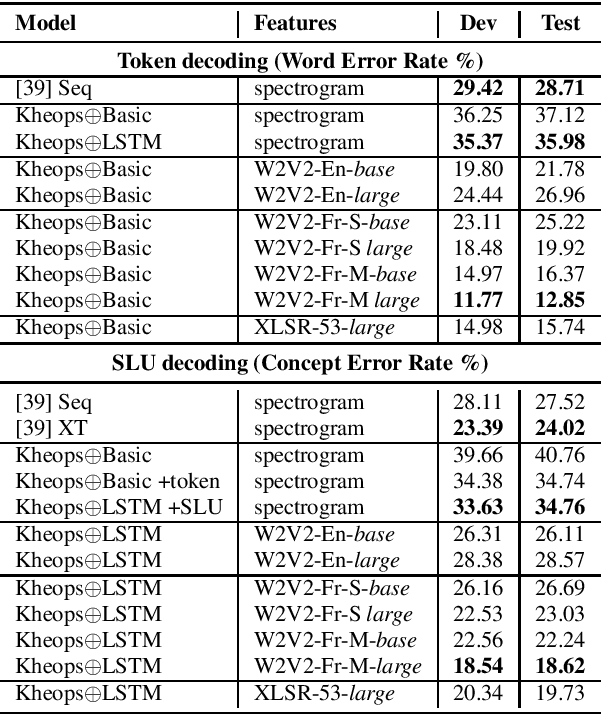
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition
Jul 10, 2019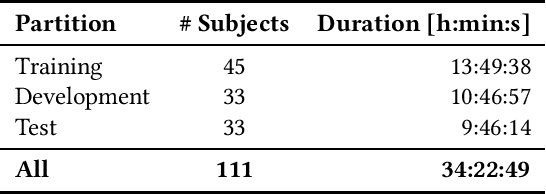
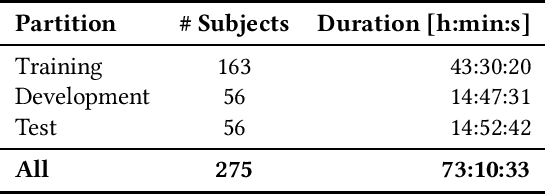
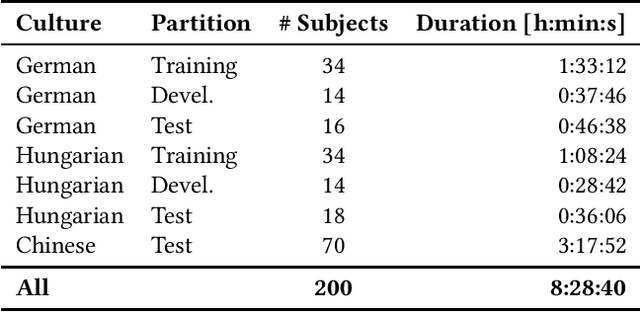
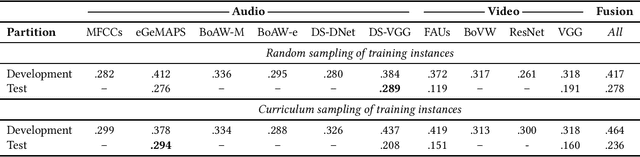
The Audio/Visual Emotion Challenge and Workshop (AVEC 2019) "State-of-Mind, Detecting Depression with AI, and Cross-cultural Affect Recognition" is the ninth competition event aimed at the comparison of multimedia processing and machine learning methods for automatic audiovisual health and emotion analysis, with all participants competing strictly under the same conditions. The goal of the Challenge is to provide a common benchmark test set for multimodal information processing and to bring together the health and emotion recognition communities, as well as the audiovisual processing communities, to compare the relative merits of various approaches to health and emotion recognition from real-life data. This paper presents the major novelties introduced this year, the challenge guidelines, the data used, and the performance of the baseline systems on the three proposed tasks: state-of-mind recognition, depression assessment with AI, and cross-cultural affect sensing, respectively.