 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARGE: A Locally Adaptive Regularization Approach for Estimating Gaussian Graphical Models
Jan 14, 2026The graphical Lasso (GLASSO) is a widely used algorithm for learning high-dimensional undirected Gaussian graphical models (GGM). Given i.i.d. observations from a multivariate normal distribution, GLASSO estimates the precision matrix by maximizing the log-likelihood with an \ell_1-penalty on the off-diagonal entries. However, selecting an optimal regularization parameter λin this unsupervised setting remains a significant challenge. A well-known issue is that existing methods, such as out-of-sample likelihood maximization, select a single global λand do not account for heterogeneity in variable scaling or partial variances. Standardizing the data to unit variances, although a common workaround, has been shown to negatively affect graph recovery. Addressing the problem of nodewise adaptive tuning in graph estimation is crucial for applications like computational neuroscience, where brain networks are constructed from highly heterogeneous, region-specific fMRI data. In this work, we develop Locally Adaptive Regularization for Graph Estimation (LARGE), an approach to adaptively learn nodewise tuning parameters to improve graph estimation and selection. In each block coordinate descent step of GLASSO, we augment the nodewise Lasso regression to jointly estimate the regression coefficients and error variance, which in turn guides the adaptive learning of nodewise penalties. In simulations, LARGE consistently outperforms benchmark methods in graph recovery, demonstrates greater stability across replications, and achieves the best estimation accuracy in the most difficult simulation settings. We demonstrate the practical utility of our method by estimating brain functional connectivity from a real fMRI data set.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Semantic enrichment towards efficient speech representations
Jul 03, 2023Over the past few years, self-supervised learned speech representations have emerged as fruitful replacements for conventional surface representations when solving Spoken Language Understanding (SLU) tasks. Simultaneously, multilingual models trained on massive textual data were introduced to encode language agnostic semantics. Recently, the SAMU-XLSR approach introduced a way to make profit from such textual models to enrich multilingual speech representations with language agnostic semantics. By aiming for better semantic extraction on a challenging Spoken Language Understanding task and in consideration with computation costs, this study investigates a specific in-domain semantic enrichment of the SAMU-XLSR model by specializing it on a small amount of transcribed data from the downstream task. In addition, we show the benefits of the use of same-domain French and Italian benchmarks for low-resource language portability and explore cross-domain capacities of the enriched SAMU-XLSR.
ON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

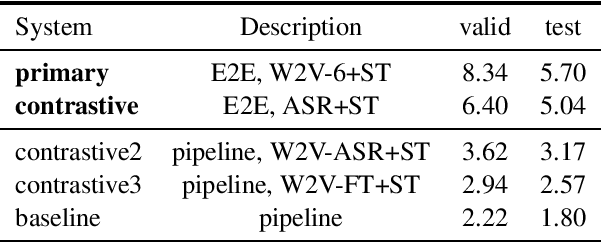

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
Impact of Encoding and Segmentation Strategies on End-to-End Simultaneous Speech Translation
Apr 29, 2021

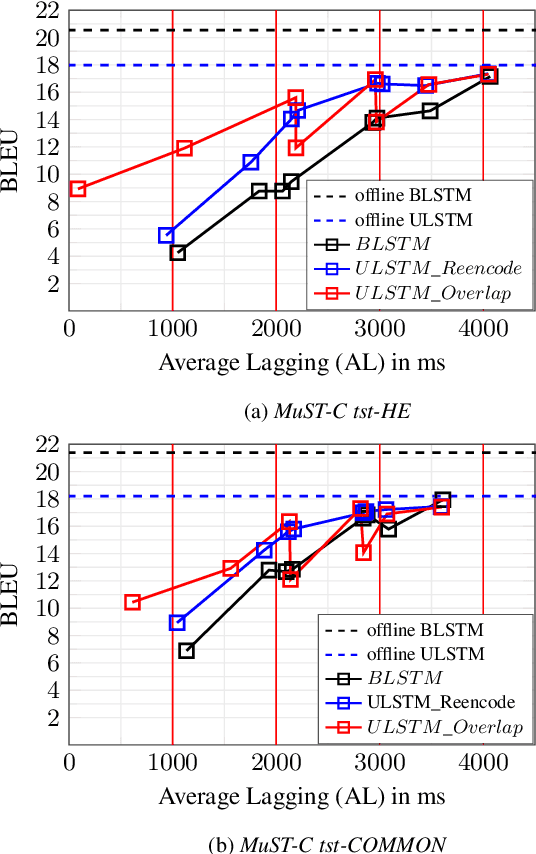
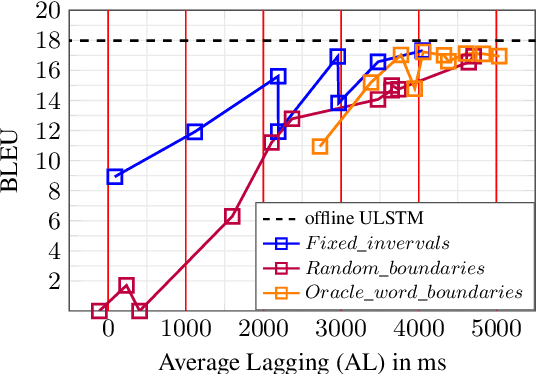
Boosted by the simultaneous translation shared task at IWSLT 2020, promising end-to-end online speech translation approaches were recently proposed. They consist in incrementally encoding a speech input (in a source language) and decoding the corresponding text (in a target language) with the best possible trade-off between latency and translation quality. This paper investigates two key aspects of end-to-end simultaneous speech translation: (a) how to encode efficiently the continuous speech flow, and (b) how to segment the speech flow in order to alternate optimally between reading (R: encoding input) and writing (W: decoding output) operations. We extend our previously proposed end-to-end online decoding strategy and show that while replacing BLSTM by ULSTM encoding degrades performance in offline mode, it actually improves both efficiency and performance in online mode. We also measure the impact of different methods to segment the speech signal (using fixed interval boundaries, oracle word boundaries or randomly set boundaries) and show that our best end-to-end online decoding strategy is surprisingly the one that alternates R/W operations on fixed size blocks on our English-German speech translation setup.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021
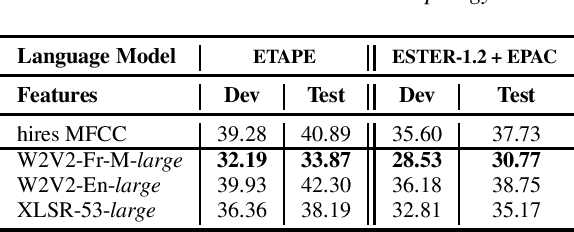
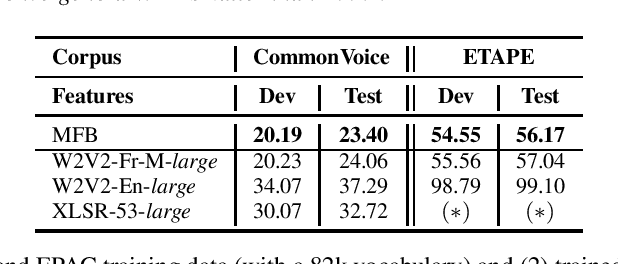
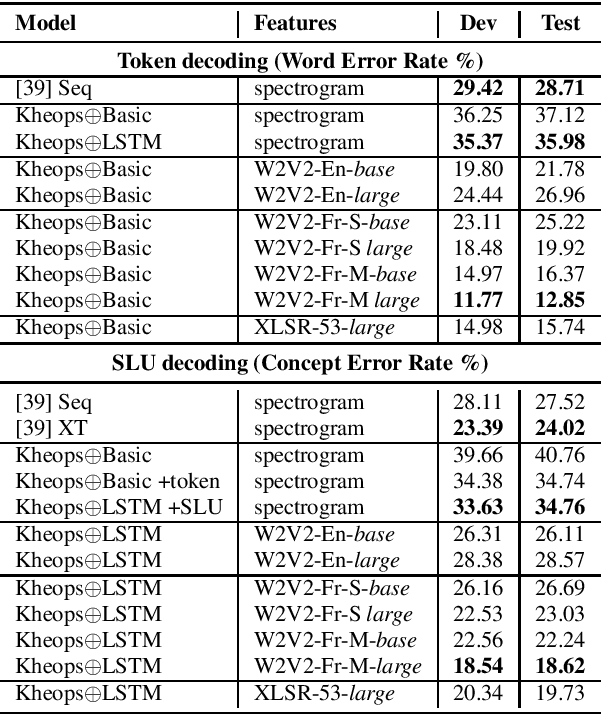
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
An Empirical Study of End-to-end Simultaneous Speech Translation Decoding Strategies
Mar 04, 2021



This paper proposes a decoding strategy for end-to-end simultaneous speech translation. We leverage end-to-end models trained in offline mode and conduct an empirical study for two language pairs (English-to-German and English-to-Portuguese). We also investigate different output token granularities including characters and Byte Pair Encoding (BPE) units. The results show that the proposed decoding approach allows to control BLEU/Average Lagging trade-off along different latency regimes. Our best decoding settings achieve comparable results with a strong cascade model evaluated on the simultaneous translation track of IWSLT 2020 shared task.
ON-TRAC Consortium for End-to-End and Simultaneous Speech Translation Challenge Tasks at IWSLT 2020
May 24, 2020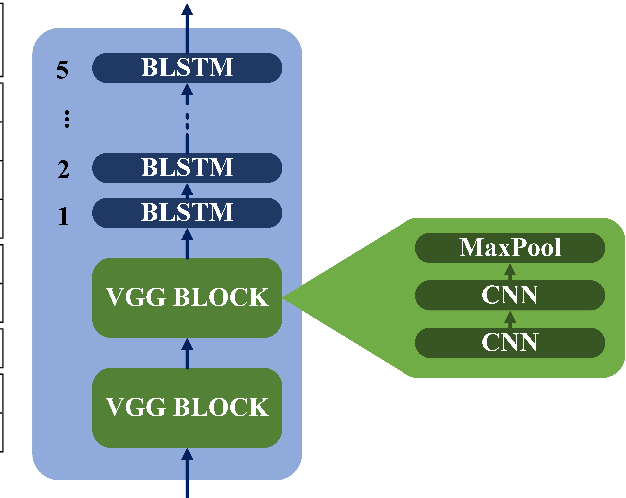
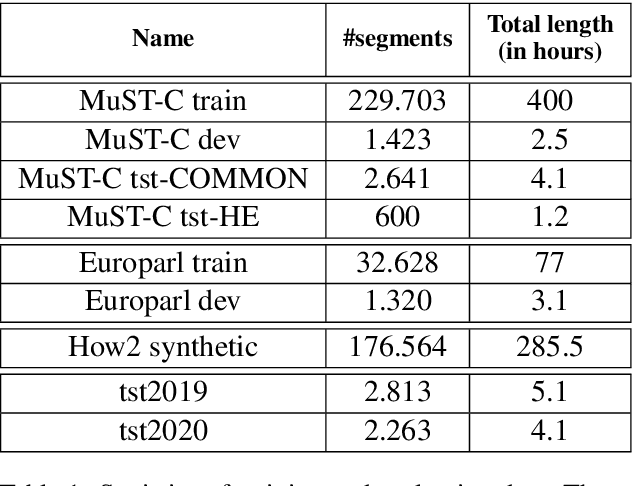
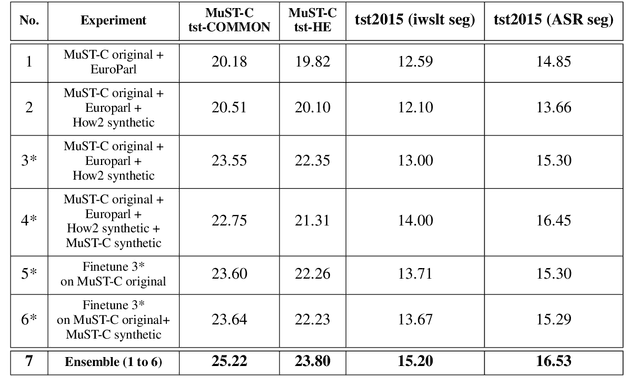
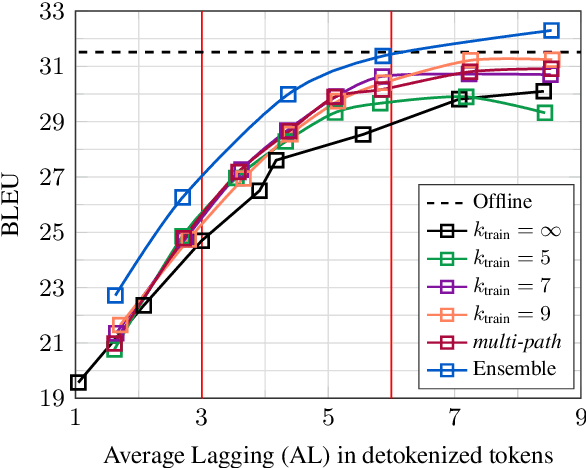
This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2020, offline speech translation and simultaneous speech translation. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). Attention-based encoder-decoder models, trained end-to-end, were used for our submissions to the offline speech translation track. Our contributions focused on data augmentation and ensembling of multiple models. In the simultaneous speech translation track, we build on Transformer-based wait-k models for the text-to-text subtask. For speech-to-text simultaneous translation, we attach a wait-k MT system to a hybrid ASR system. We propose an algorithm to control the latency of the ASR+MT cascade and achieve a good latency-quality trade-off on both subtasks.
ON-TRAC Consortium End-to-End Speech Translation Systems for the IWSLT 2019 Shared Task
Oct 30, 2019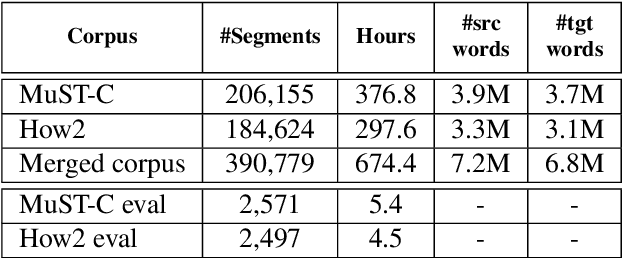
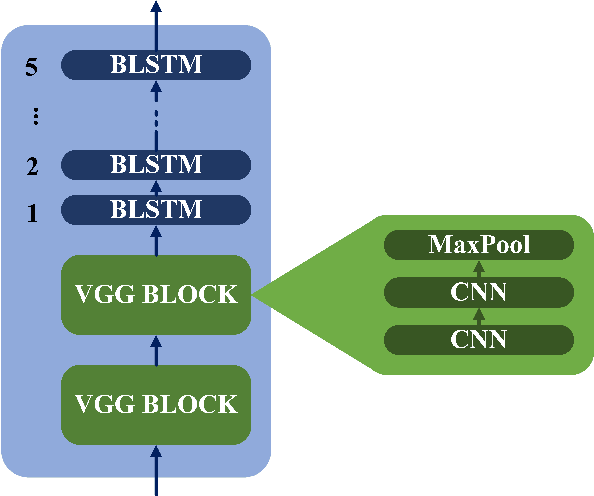
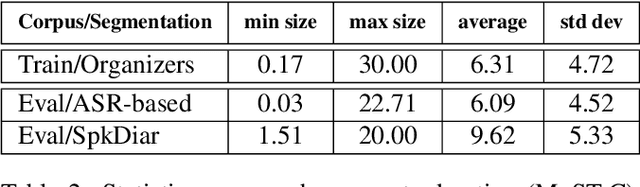
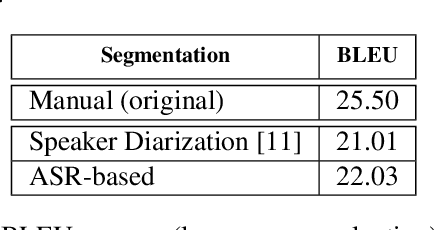
This paper describes the ON-TRAC Consortium translation systems developed for the end-to-end model task of IWSLT Evaluation 2019 for the English-to-Portuguese language pair. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). A single end-to-end model built as a neural encoder-decoder architecture with attention mechanism was used for two primary submissions corresponding to the two EN-PT evaluations sets: (1) TED (MuST-C) and (2) How2. In this paper, we notably investigate impact of pooling heterogeneous corpora for training, impact of target tokenization (characters or BPEs), impact of speech input segmentation and we also compare our best end-to-end model (BLEU of 26.91 on MuST-C and 43.82 on How2 validation sets) to a pipeline (ASR+MT) approach.