 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCV-18 NER: Augmented Common Voice for Named Entity Recognition from Arabic Speech
Apr 02, 2026End-to-end speech Named Entity Recognition (NER) aims to directly extract entities from speech. Prior work has shown that end-to-end (E2E) approaches can outperform cascaded pipelines for English, French, and Chinese, but Arabic remains under-explored due to its morphological complexity, the absence of short vowels, and limited annotated resources. We introduce CV-18 NER, the first publicly available dataset for NER from Arabic speech, created by augmenting the Arabic Common Voice 18 corpus with manual NER annotations following the fine-grained Wojood schema (21 entity types). We benchmark both pipeline systems (ASR + text NER) and E2E models based on Whisper and AraBEST-RQ. E2E systems substantially outperform the best pipeline configuration on the test set, reaching 37.0% CoER (AraBEST-RQ 300M) and 38.0% CVER (Whisper-medium). Further analysis shows that Arabic-specific self-supervised pretraining yields strong ASR performance, while multilingual weak supervision transfers more effectively to joint speech-to-entity learning, and that larger models may be harder to adapt in this low-resource setting. Our dataset and models are publicly released, providing the first open benchmark for end-to-end named entity recognition from Arabic speech https://huggingface.co/datasets/Elyadata/CV18-NER.
SLURP-TN : Resource for Tunisian Dialect Spoken Language Understanding
Mar 23, 2026Spoken Language Understanding (SLU) aims to extract the semantic information from the speech utterance of user queries. It is a core component in a task-oriented dialogue system. With the spectacular progress of deep neural network models and the evolution of pre-trained language models, SLU has obtained significant breakthroughs. However, only a few high-resource languages have taken advantage of this progress due to the absence of SLU resources. In this paper, we seek to mitigate this obstacle by introducing SLURP-TN. This dataset was created by recording 55 native speakers uttering sentences in Tunisian dialect, manually translated from six SLURP domains. The result is an SLU Tunisian dialect dataset that comprises 4165 sentences recorded into around 5 hours of acoustic material. We also develop a number of Automatic Speech Recognition and SLU models exploiting SLUTP-TN. The Dataset and baseline models are available at: https://huggingface.co/datasets/Elyadata/SLURP-TN.
Ara-Best-RQ: Multi Dialectal Arabic SSL
Mar 23, 2026We present Ara-BEST-RQ, a family of self-supervised learning (SSL) models specifically designed for multi-dialectal Arabic speech processing. Leveraging 5,640 hours of crawled Creative Commons speech and combining it with publicly available datasets, we pre-train conformer-based BEST-RQ models up to 600M parameters. Our models are evaluated on dialect identification (DID) and automatic speech recognition (ASR) tasks, achieving state-of-the-art performance on the former while using fewer parameters than competing models. We demonstrate that family-targeted pre-training on Arabic dialects significantly improves downstream performance compared to multilingual or monolingual models trained on non-Arabic data. All models, code, and pre-processed datasets will be publicly released to support reproducibility and further research in Arabic speech technologies.
TEDxTN: A Three-way Speech Translation Corpus for Code-Switched Tunisian Arabic - English
Nov 13, 2025In this paper, we introduce TEDxTN, the first publicly available Tunisian Arabic to English speech translation dataset. This work is in line with the ongoing effort to mitigate the data scarcity obstacle for a number of Arabic dialects. We collected, segmented, transcribed and translated 108 TEDx talks following our internally developed annotations guidelines. The collected talks represent 25 hours of speech with code-switching that cover speakers with various accents from over 11 different regions of Tunisia. We make the annotation guidelines and corpus publicly available. This will enable the extension of TEDxTN to new talks as they become available. We also report results for strong baseline systems of Speech Recognition and Speech Translation using multiple pre-trained and fine-tuned end-to-end models. This corpus is the first open source and publicly available speech translation corpus of Code-Switching Tunisian dialect. We believe that this is a valuable resource that can motivate and facilitate further research on the natural language processing of Tunisian Dialect.
ELYADATA & LIA at NADI 2025: ASR and ADI Subtasks
Nov 13, 2025This paper describes Elyadata \& LIA's joint submission to the NADI multi-dialectal Arabic Speech Processing 2025. We participated in the Spoken Arabic Dialect Identification (ADI) and multi-dialectal Arabic ASR subtasks. Our submission ranked first for the ADI subtask and second for the multi-dialectal Arabic ASR subtask among all participants. Our ADI system is a fine-tuned Whisper-large-v3 encoder with data augmentation. This system obtained the highest ADI accuracy score of \textbf{79.83\%} on the official test set. For multi-dialectal Arabic ASR, we fine-tuned SeamlessM4T-v2 Large (Egyptian variant) separately for each of the eight considered dialects. Overall, we obtained an average WER and CER of \textbf{38.54\%} and \textbf{14.53\%}, respectively, on the test set. Our results demonstrate the effectiveness of large pre-trained speech models with targeted fine-tuning for Arabic speech processing.
ADI-20: Arabic Dialect Identification dataset and models
Nov 13, 2025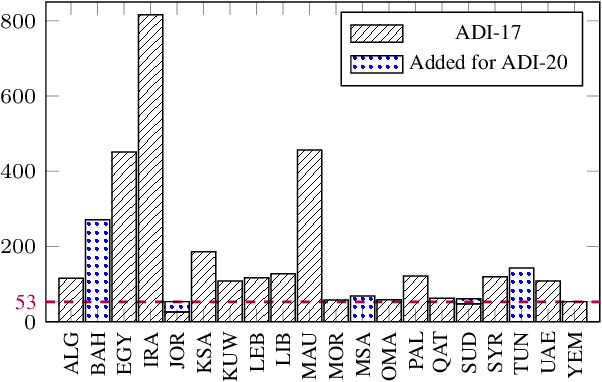
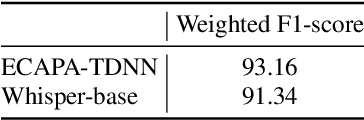
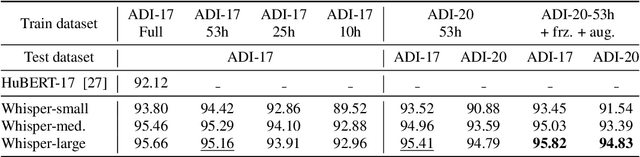
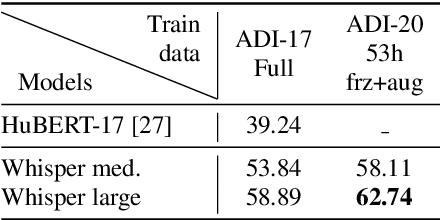
We present ADI-20, an extension of the previously published ADI-17 Arabic Dialect Identification (ADI) dataset. ADI-20 covers all Arabic-speaking countries' dialects. It comprises 3,556 hours from 19 Arabic dialects in addition to Modern Standard Arabic (MSA). We used this dataset to train and evaluate various state-of-the-art ADI systems. We explored fine-tuning pre-trained ECAPA-TDNN-based models, as well as Whisper encoder blocks coupled with an attention pooling layer and a classification dense layer. We investigated the effect of (i) training data size and (ii) the model's number of parameters on identification performance. Our results show a small decrease in F1 score while using only 30% of the original training data. We open-source our collected data and trained models to enable the reproduction of our work, as well as support further research in ADI.
Performance Analysis of Speech Encoders for Low-Resource SLU and ASR in Tunisian Dialect
Jul 05, 2024Speech encoders pretrained through self-supervised learning (SSL) have demonstrated remarkable performance in various downstream tasks, including Spoken Language Understanding (SLU) and Automatic Speech Recognition (ASR). For instance, fine-tuning SSL models for such tasks has shown significant potential, leading to improvements in the SOTA performance across challenging datasets. In contrast to existing research, this paper contributes by comparing the effectiveness of SSL approaches in the context of (i) the low-resource spoken Tunisian Arabic dialect and (ii) its combination with a low-resource SLU and ASR scenario, where only a few semantic annotations are available for fine-tuning. We conduct experiments using many SSL speech encoders on the TARIC-SLU dataset. We use speech encoders that were pre-trained on either monolingual or multilingual speech data. Some of them have also been refined without in-domain nor Tunisian data through multimodal supervised teacher-student paradigm. This study yields numerous significant findings that we are discussing in this paper.
End-to-End Speech Translation of Arabic to English Broadcast News
Dec 11, 2022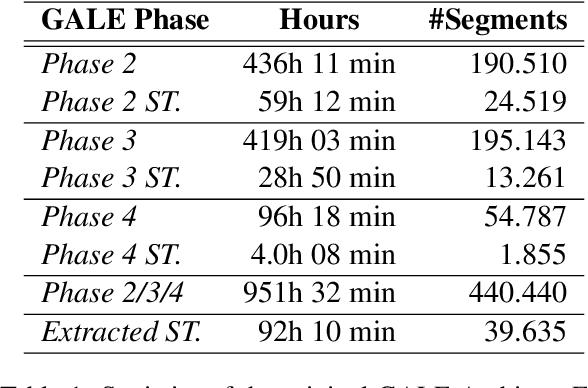
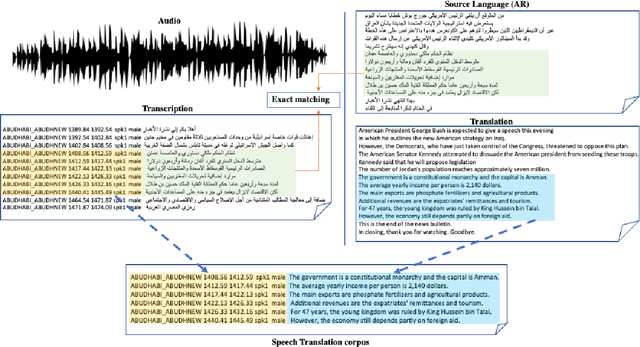
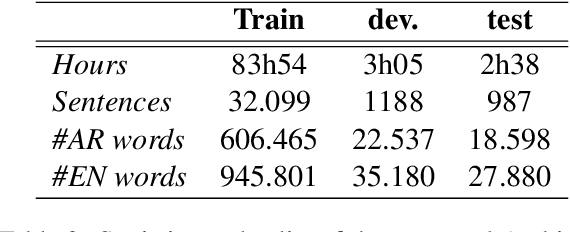

Speech translation (ST) is the task of directly translating acoustic speech signals in a source language into text in a foreign language. ST task has been addressed, for a long time, using a pipeline approach with two modules : first an Automatic Speech Recognition (ASR) in the source language followed by a text-to-text Machine translation (MT). In the past few years, we have seen a paradigm shift towards the end-to-end approaches using sequence-to-sequence deep neural network models. This paper presents our efforts towards the development of the first Broadcast News end-to-end Arabic to English speech translation system. Starting from independent ASR and MT LDC releases, we were able to identify about 92 hours of Arabic audio recordings for which the manual transcription was also translated into English at the segment level. These data was used to train and compare pipeline and end-to-end speech translation systems under multiple scenarios including transfer learning and data augmentation techniques.
ON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

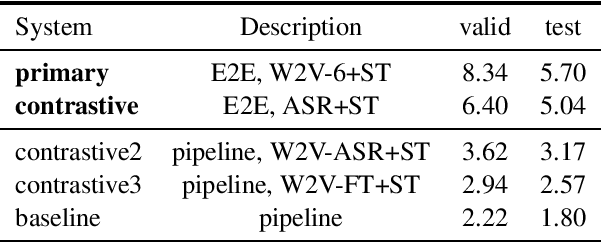

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
Speech Resources in the Tamasheq Language
Jan 14, 2022
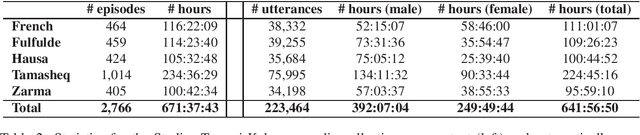

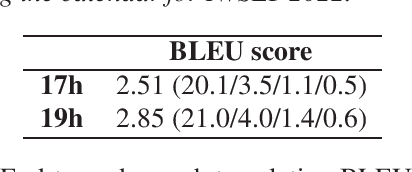
In this paper we present two datasets for Tamasheq, a developing language mainly spoken in Mali and Niger. These two datasets were made available for the IWSLT 2022 low-resource speech translation track, and they consist of collections of radio recordings from the Studio Kalangou (Niger) and Studio Tamani (Mali) daily broadcast news. We share (i) a massive amount of unlabeled audio data (671 hours) in five languages: French from Niger, Fulfulde, Hausa, Tamasheq and Zarma, and (ii) a smaller parallel corpus of audio recordings (17 hours) in Tamasheq, with utterance-level translations in the French language. All this data is shared under the Creative Commons BY-NC-ND 3.0 license. We hope these resources will inspire the speech community to develop and benchmark models using the Tamasheq language.