 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation by Generating Multiple Linguistic Factors
Paper and Code


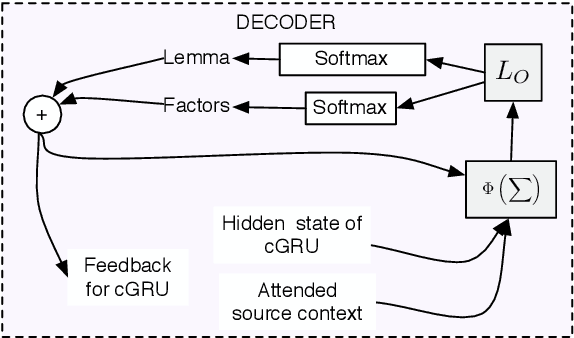

Factored neural machine translation (FNMT) is founded on the idea of using the morphological and grammatical decomposition of the words (factors) at the output side of the neural network. This architecture addresses two well-known problems occurring in MT, namely the size of target language vocabulary and the number of unknown tokens produced in the translation. FNMT system is designed to manage larger vocabulary and reduce the training time (for systems with equivalent target language vocabulary size). Moreover, we can produce grammatically correct words that are not part of the vocabulary. FNMT model is evaluated on IWSLT'15 English to French task and compared to the baseline word-based and BPE-based NMT systems. Promising qualitative and quantitative results (in terms of BLEU and METEOR) are reported.