 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022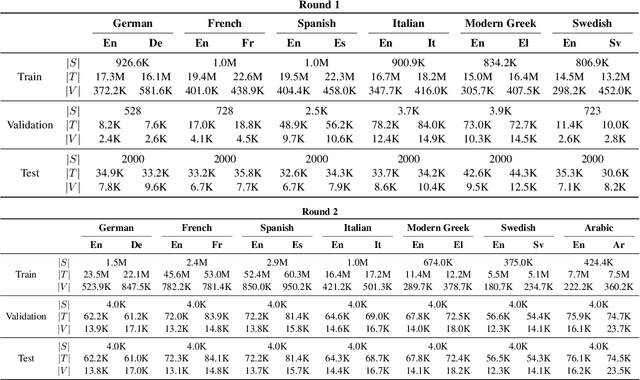
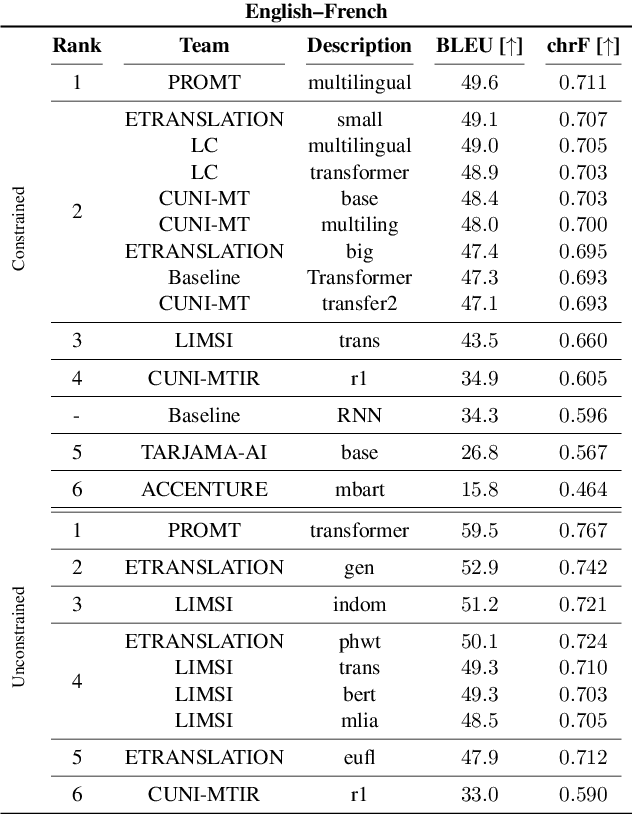
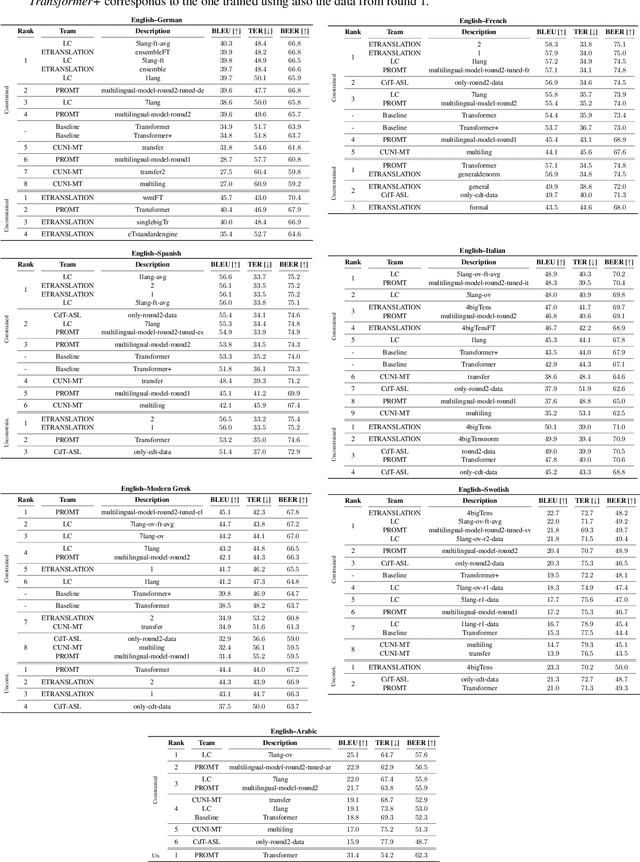
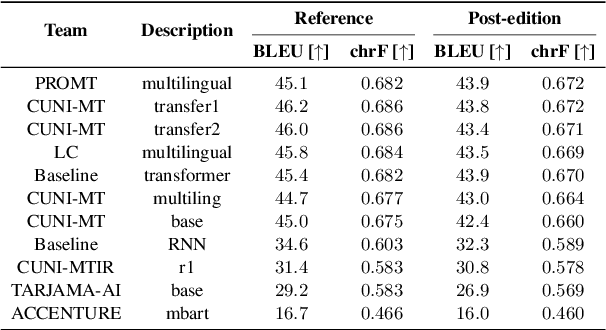
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.
Demonstration of a Neural Machine Translation System with Online Learning for Translators
Jun 21, 2019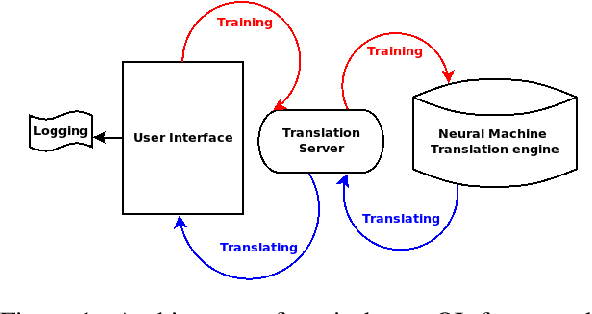

We introduce a demonstration of our system, which implements online learning for neural machine translation in a production environment. These techniques allow the system to continuously learn from the corrections provided by the translators. We implemented an end-to-end platform integrating our machine translation servers to one of the most common user interfaces for professional translators: SDL Trados Studio. Our objective was to save post-editing effort as the machine is continuously learning from human choices and adapting the models to a specific domain or user style.
Incremental Adaptation of NMT for Professional Post-editors: A User Study
Jun 21, 2019
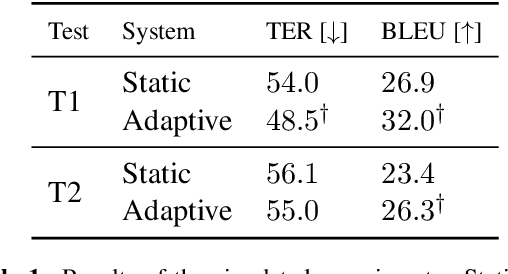

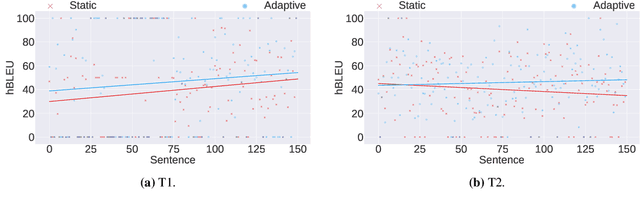
A common use of machine translation in the industry is providing initial translation hypotheses, which are later supervised and post-edited by a human expert. During this revision process, new bilingual data are continuously generated. Machine translation systems can benefit from these new data, incrementally updating the underlying models under an online learning paradigm. We conducted a user study on this scenario, for a neural machine translation system. The experimentation was carried out by professional translators, with a vast experience in machine translation post-editing. The results showed a reduction in the required amount of human effort needed when post-editing the outputs of the system, improvements in the translation quality and a positive perception of the adaptive system by the users.
Neural Machine Translation by Generating Multiple Linguistic Factors
Dec 05, 2017

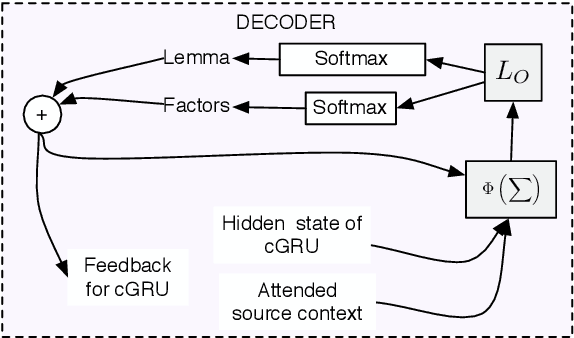

Factored neural machine translation (FNMT) is founded on the idea of using the morphological and grammatical decomposition of the words (factors) at the output side of the neural network. This architecture addresses two well-known problems occurring in MT, namely the size of target language vocabulary and the number of unknown tokens produced in the translation. FNMT system is designed to manage larger vocabulary and reduce the training time (for systems with equivalent target language vocabulary size). Moreover, we can produce grammatically correct words that are not part of the vocabulary. FNMT model is evaluated on IWSLT'15 English to French task and compared to the baseline word-based and BPE-based NMT systems. Promising qualitative and quantitative results (in terms of BLEU and METEOR) are reported.
LIUM Machine Translation Systems for WMT17 News Translation Task
Jul 14, 2017

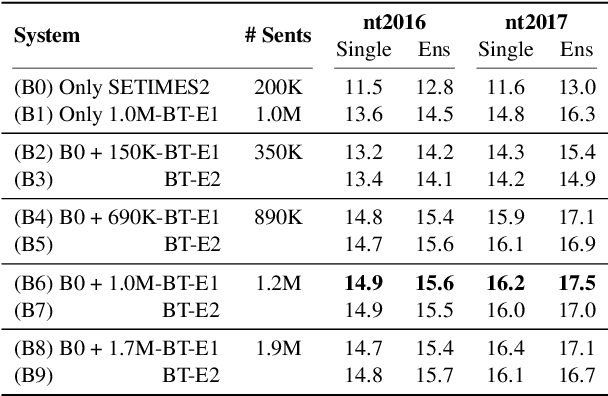
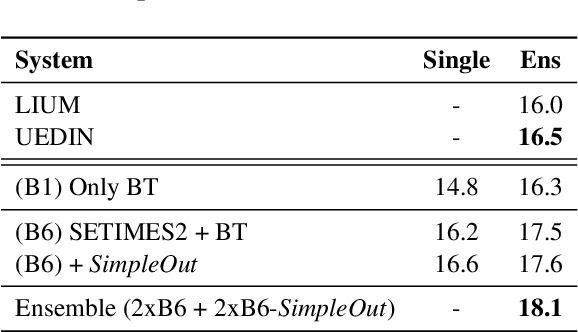
This paper describes LIUM submissions to WMT17 News Translation Task for English-German, English-Turkish, English-Czech and English-Latvian language pairs. We train BPE-based attentive Neural Machine Translation systems with and without factored outputs using the open source nmtpy framework. Competitive scores were obtained by ensembling various systems and exploiting the availability of target monolingual corpora for back-translation. The impact of back-translation quantity and quality is also analyzed for English-Turkish where our post-deadline submission surpassed the best entry by +1.6 BLEU.
LIUM-CVC Submissions for WMT17 Multimodal Translation Task
Jul 14, 2017
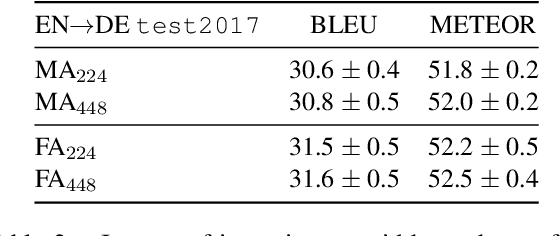
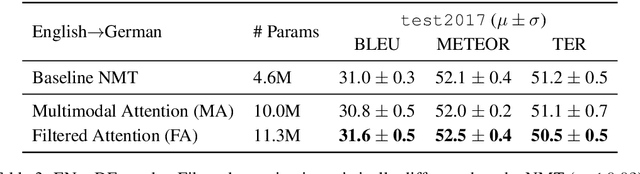
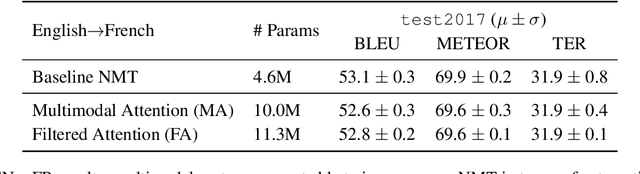
This paper describes the monomodal and multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT17 Shared Task on Multimodal Translation. We mainly explored two multimodal architectures where either global visual features or convolutional feature maps are integrated in order to benefit from visual context. Our final systems ranked first for both En-De and En-Fr language pairs according to the automatic evaluation metrics METEOR and BLEU.
NMTPY: A Flexible Toolkit for Advanced Neural Machine Translation Systems
Jun 01, 2017



In this paper, we present nmtpy, a flexible Python toolkit based on Theano for training Neural Machine Translation and other neural sequence-to-sequence architectures. nmtpy decouples the specification of a network from the training and inference utilities to simplify the addition of a new architecture and reduce the amount of boilerplate code to be written. nmtpy has been used for LIUM's top-ranked submissions to WMT Multimodal Machine Translation and News Translation tasks in 2016 and 2017.
Factored Neural Machine Translation
Sep 15, 2016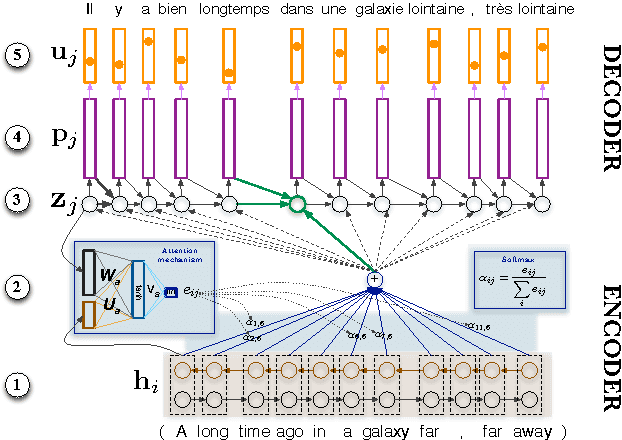
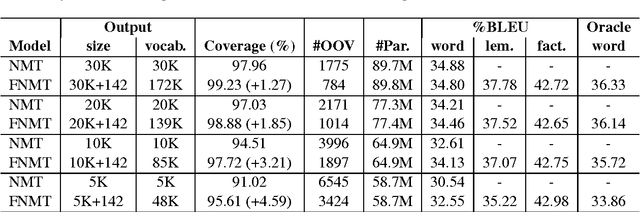
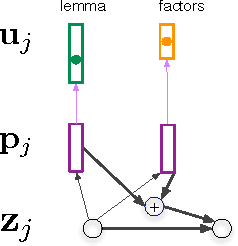
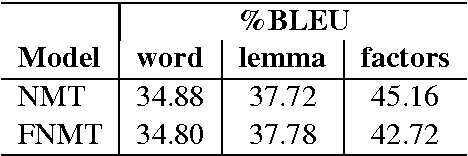
We present a new approach for neural machine translation (NMT) using the morphological and grammatical decomposition of the words (factors) in the output side of the neural network. This architecture addresses two main problems occurring in MT, namely dealing with a large target language vocabulary and the out of vocabulary (OOV) words. By the means of factors, we are able to handle larger vocabulary and reduce the training time (for systems with equivalent target language vocabulary size). In addition, we can produce new words that are not in the vocabulary. We use a morphological analyser to get a factored representation of each word (lemmas, Part of Speech tag, tense, person, gender and number). We have extended the NMT approach with attention mechanism in order to have two different outputs, one for the lemmas and the other for the rest of the factors. The final translation is built using some \textit{a priori} linguistic information. We compare our extension with a word-based NMT system. The experiments, performed on the IWSLT'15 dataset translating from English to French, show that while the performance do not always increase, the system can manage a much larger vocabulary and consistently reduce the OOV rate. We observe up to 2% BLEU point improvement in a simulated out of domain translation setup.
Does Multimodality Help Human and Machine for Translation and Image Captioning?
Aug 16, 2016

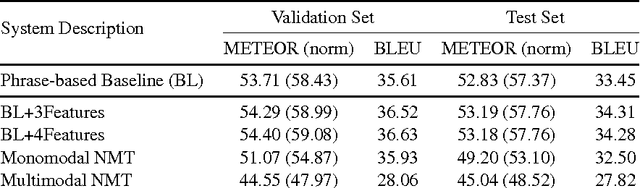

This paper presents the systems developed by LIUM and CVC for the WMT16 Multimodal Machine Translation challenge. We explored various comparative methods, namely phrase-based systems and attentional recurrent neural networks models trained using monomodal or multimodal data. We also performed a human evaluation in order to estimate the usefulness of multimodal data for human machine translation and image description generation. Our systems obtained the best results for both tasks according to the automatic evaluation metrics BLEU and METEOR.