 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022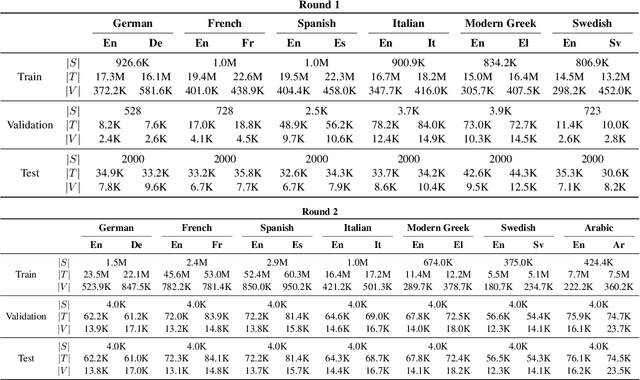
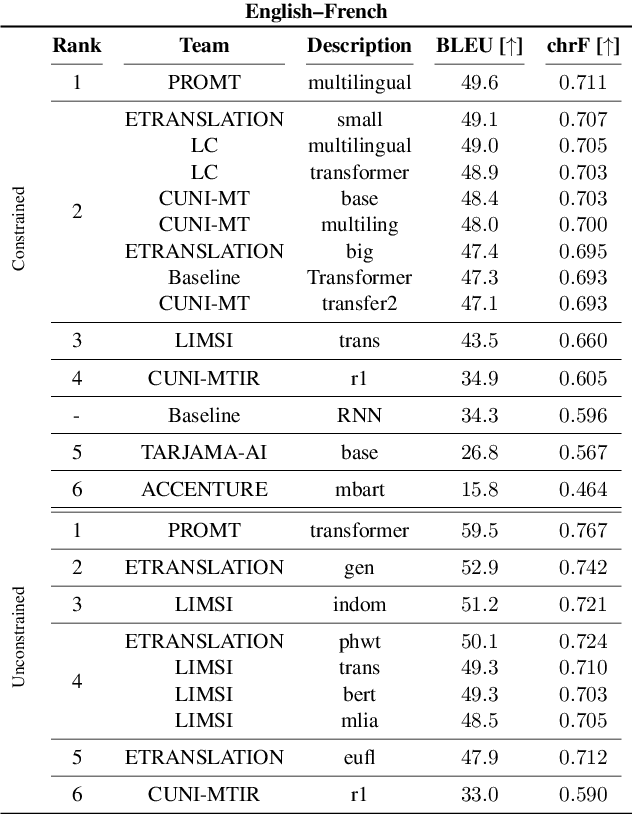
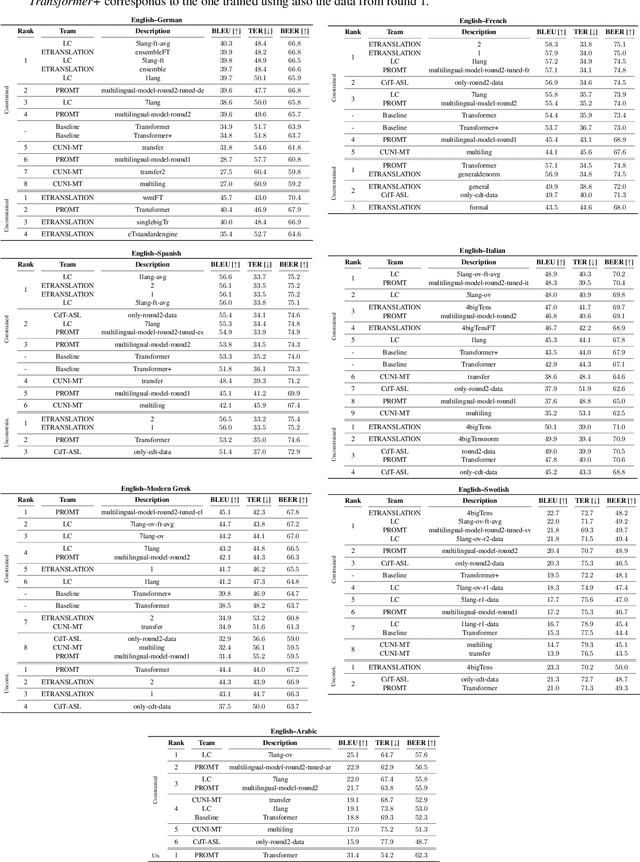
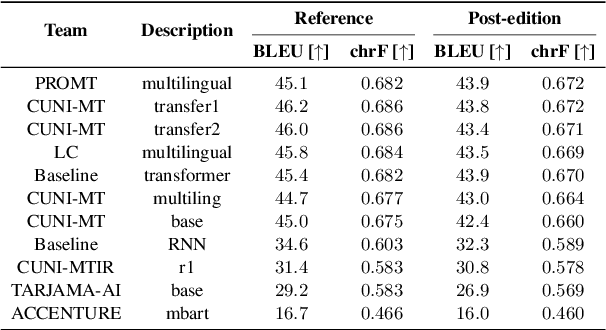
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.
Incremental Adaptation of NMT for Professional Post-editors: A User Study
Jun 21, 2019
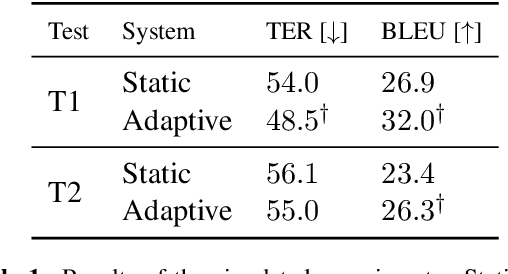

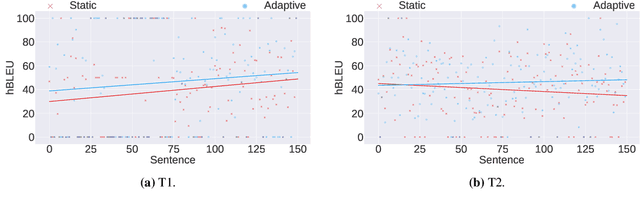
A common use of machine translation in the industry is providing initial translation hypotheses, which are later supervised and post-edited by a human expert. During this revision process, new bilingual data are continuously generated. Machine translation systems can benefit from these new data, incrementally updating the underlying models under an online learning paradigm. We conducted a user study on this scenario, for a neural machine translation system. The experimentation was carried out by professional translators, with a vast experience in machine translation post-editing. The results showed a reduction in the required amount of human effort needed when post-editing the outputs of the system, improvements in the translation quality and a positive perception of the adaptive system by the users.
How Much Does Tokenization Affect Neural Machine Translation?
Dec 27, 2018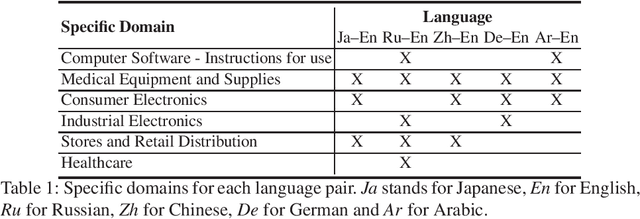
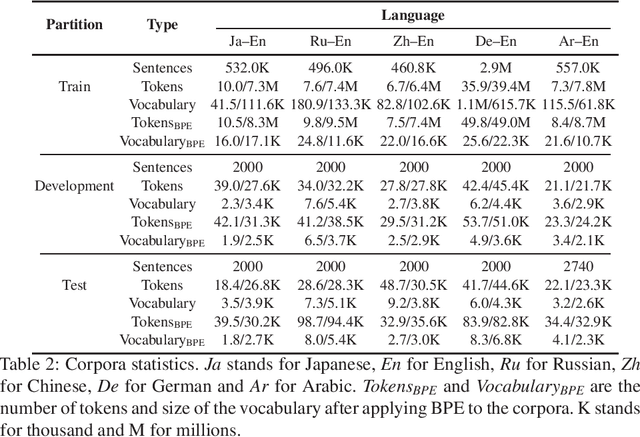
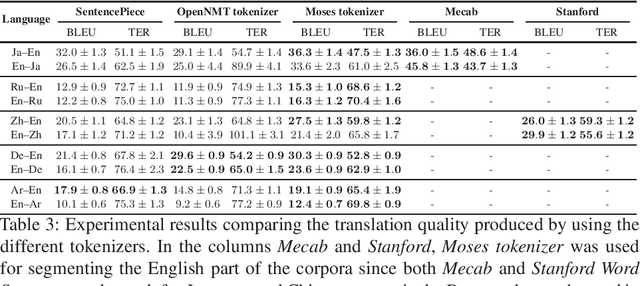
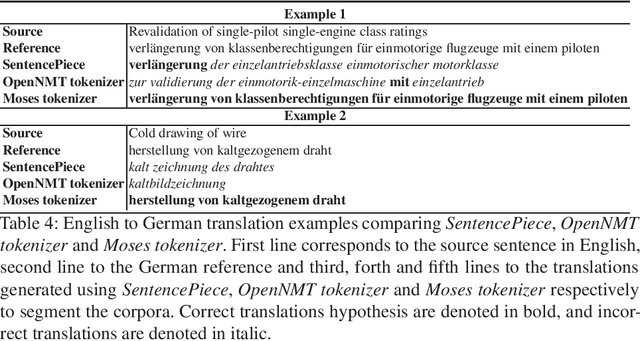
Tokenization or segmentation is a wide concept that covers simple processes such as separating punctuation from words, or more sophisticated processes such as applying morphological knowledge. Neural Machine Translation (NMT) requires a limited-size vocabulary for computational cost and enough examples to estimate word embeddings. Separating punctuation and splitting tokens into words or subwords has proven to be helpful to reduce vocabulary and increase the number of examples of each word, improving the translation quality. Tokenization is more challenging when dealing with languages with no separator between words. In order to assess the impact of the tokenization in the quality of the final translation on NMT, we experimented on five tokenizers over ten language pairs. We reached the conclusion that the tokenization significantly affects the final translation quality and that the best tokenizer differs for different language pairs.