 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned in ATCO2: 5000 hours of Air Traffic Control Communications for Robust Automatic Speech Recognition and Understanding
May 02, 2023

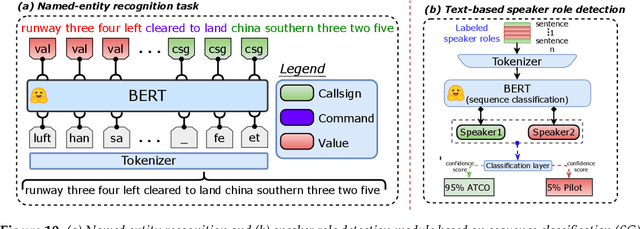

Voice communication between air traffic controllers (ATCos) and pilots is critical for ensuring safe and efficient air traffic control (ATC). This task requires high levels of awareness from ATCos and can be tedious and error-prone. Recent attempts have been made to integrate artificial intelligence (AI) into ATC in order to reduce the workload of ATCos. However, the development of data-driven AI systems for ATC demands large-scale annotated datasets, which are currently lacking in the field. This paper explores the lessons learned from the ATCO2 project, a project that aimed to develop a unique platform to collect and preprocess large amounts of ATC data from airspace in real time. Audio and surveillance data were collected from publicly accessible radio frequency channels with VHF receivers owned by a community of volunteers and later uploaded to Opensky Network servers, which can be considered an "unlimited source" of data. In addition, this paper reviews previous work from ATCO2 partners, including (i) robust automatic speech recognition, (ii) natural language processing, (iii) English language identification of ATC communications, and (iv) the integration of surveillance data such as ADS-B. We believe that the pipeline developed during the ATCO2 project, along with the open-sourcing of its data, will encourage research in the ATC field. A sample of the ATCO2 corpus is available on the following website: https://www.atco2.org/data, while the full corpus can be purchased through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. We demonstrated that ATCO2 is an appropriate dataset to develop ASR engines when little or near to no ATC in-domain data is available. For instance, with the CNN-TDNNf kaldi model, we reached the performance of as low as 17.9% and 24.9% WER on public ATC datasets which is 6.6/7.6% better than "out-of-domain" but supervised CNN-TDNNf model.
Findings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022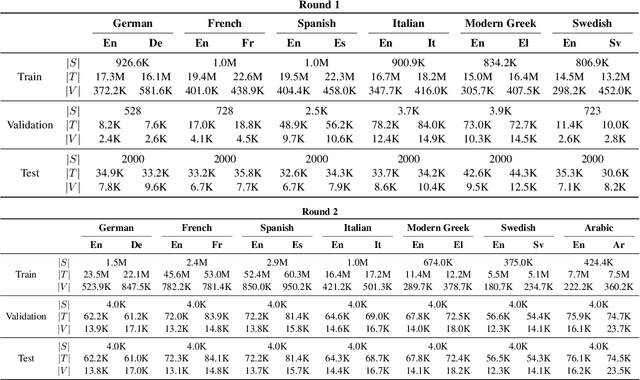
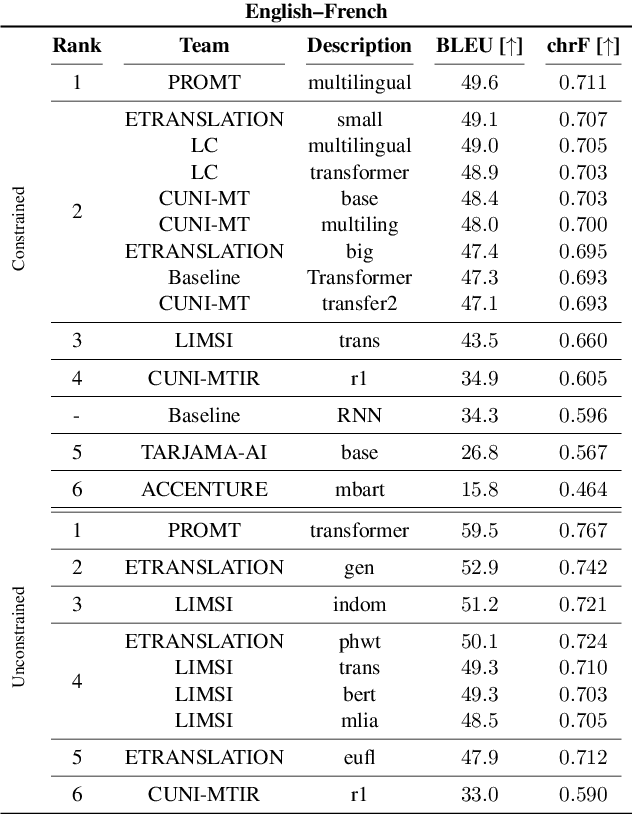
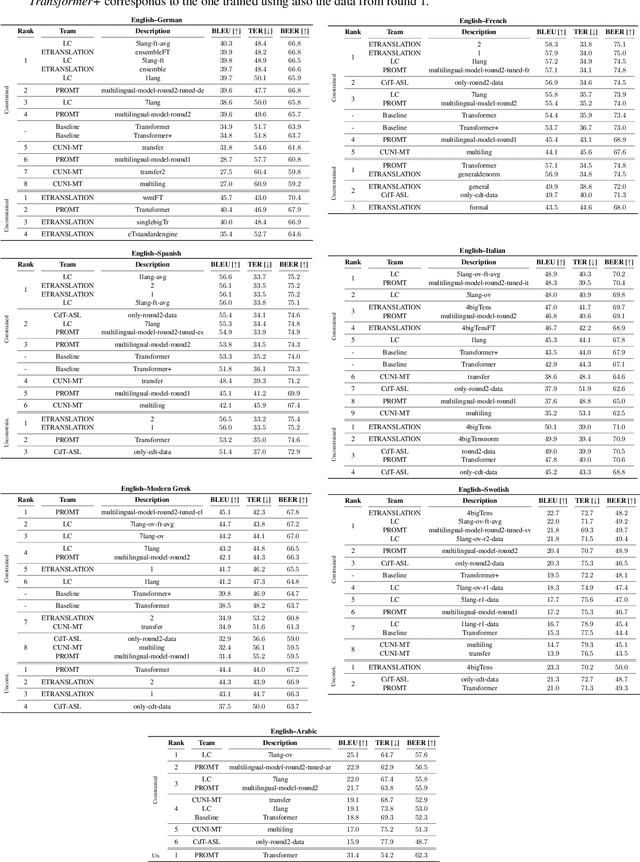
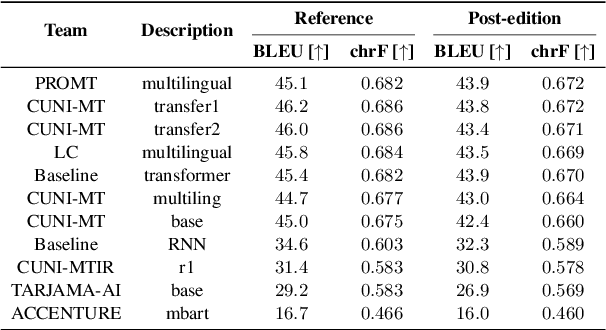
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.
ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications
Nov 08, 2022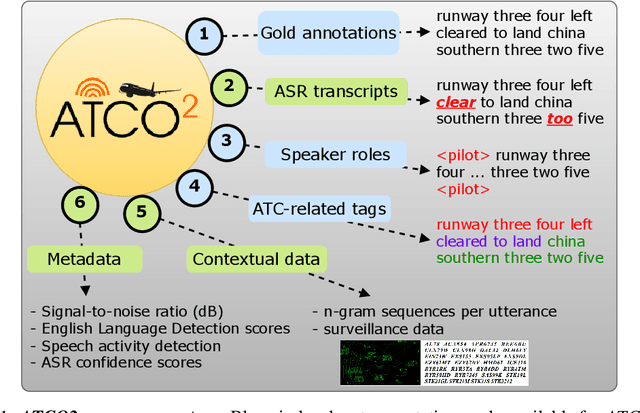
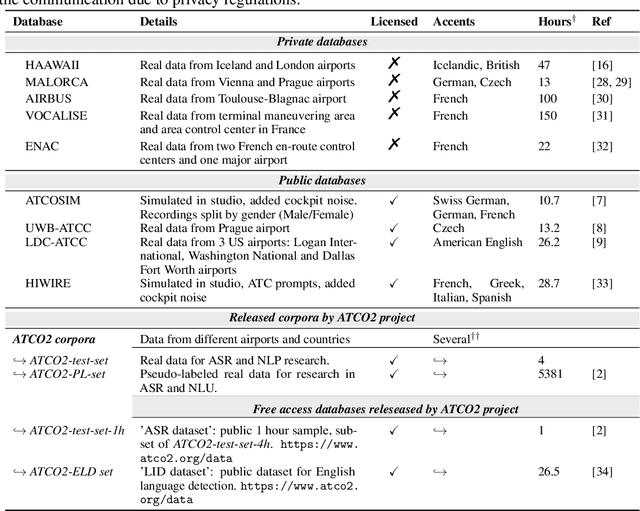
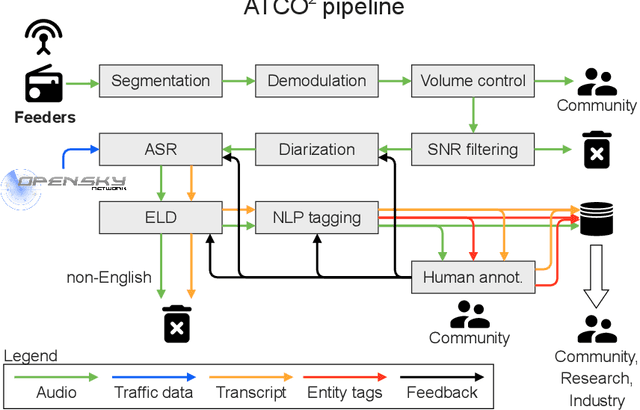

Personal assistants, automatic speech recognizers and dialogue understanding systems are becoming more critical in our interconnected digital world. A clear example is air traffic control (ATC) communications. ATC aims at guiding aircraft and controlling the airspace in a safe and optimal manner. These voice-based dialogues are carried between an air traffic controller (ATCO) and pilots via very-high frequency radio channels. In order to incorporate these novel technologies into ATC (low-resource domain), large-scale annotated datasets are required to develop the data-driven AI systems. Two examples are automatic speech recognition (ASR) and natural language understanding (NLU). In this paper, we introduce the ATCO2 corpus, a dataset that aims at fostering research on the challenging ATC field, which has lagged behind due to lack of annotated data. The ATCO2 corpus covers 1) data collection and pre-processing, 2) pseudo-annotations of speech data, and 3) extraction of ATC-related named entities. The ATCO2 corpus is split into three subsets. 1) ATCO2-test-set corpus contains 4 hours of ATC speech with manual transcripts and a subset with gold annotations for named-entity recognition (callsign, command, value). 2) The ATCO2-PL-set corpus consists of 5281 hours of unlabeled ATC data enriched with automatic transcripts from an in-domain speech recognizer, contextual information, speaker turn information, signal-to-noise ratio estimate and English language detection score per sample. Both available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. 3) The ATCO2-test-set-1h corpus is a one-hour subset from the original test set corpus, that we are offering for free at https://www.atco2.org/data. We expect the ATCO2 corpus will foster research on robust ASR and NLU not only in the field of ATC communications but also in the general research community.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020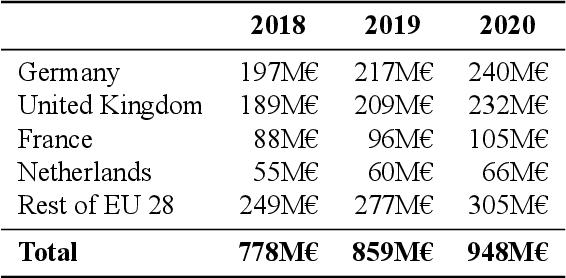
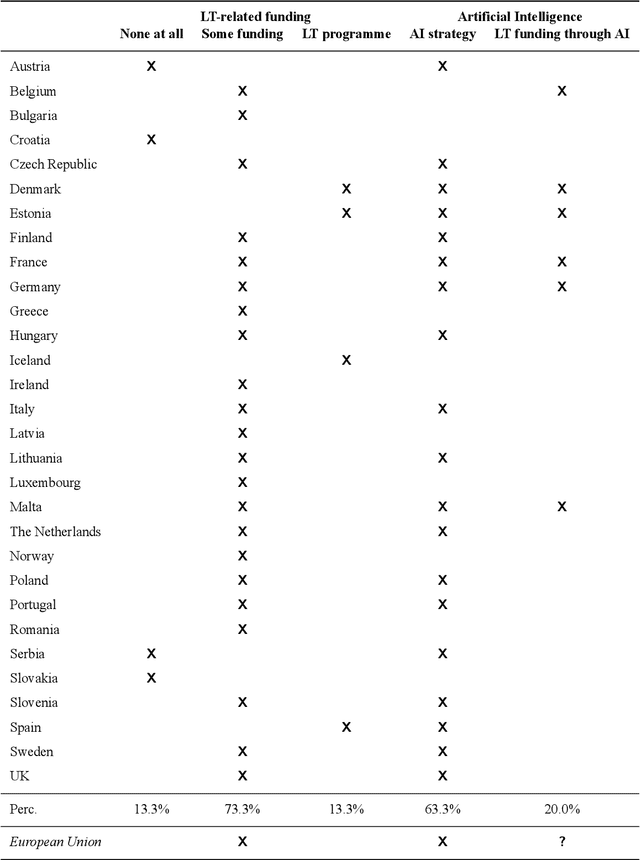
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
European Language Grid: An Overview
Mar 30, 2020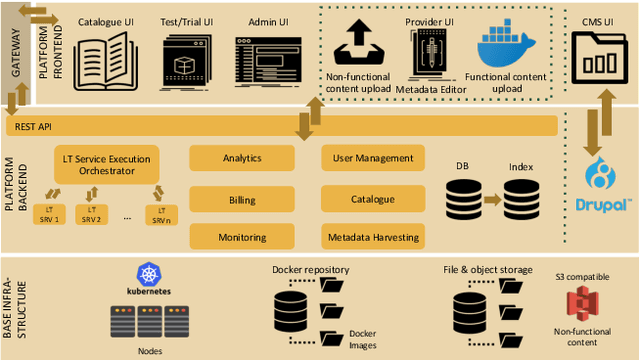

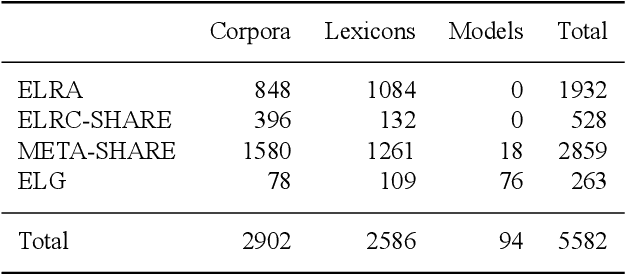
With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
Making Metadata Fit for Next Generation Language Technology Platforms: The Metadata Schema of the European Language Grid
Mar 30, 2020
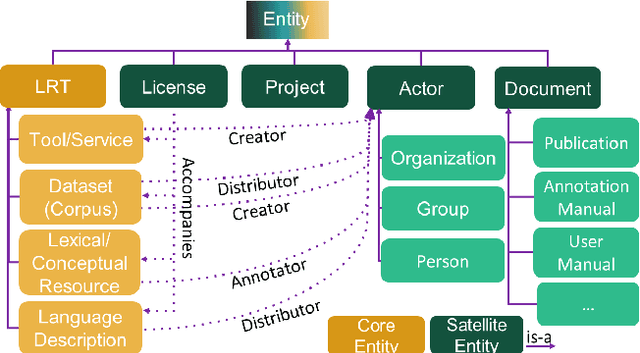
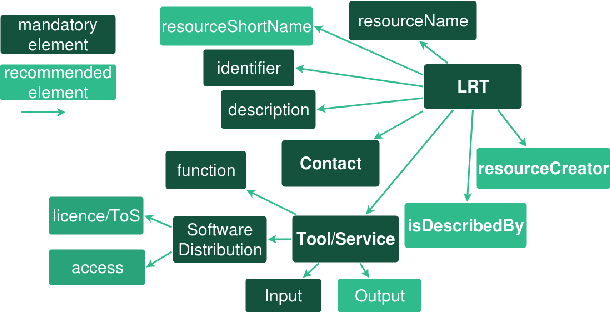

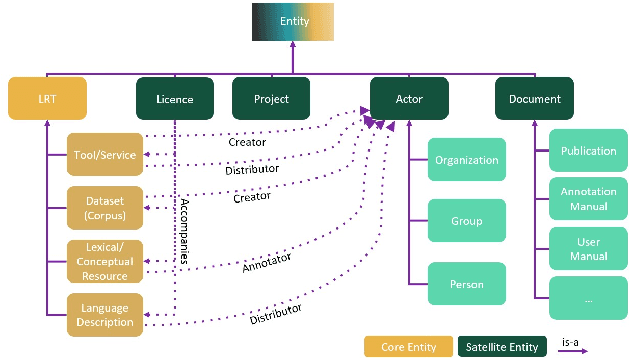
The current scientific and technological landscape is characterised by the increasing availability of data resources and processing tools and services. In this setting, metadata have emerged as a key factor facilitating management, sharing and usage of such digital assets. In this paper we present ELG-SHARE, a rich metadata schema catering for the description of Language Resources and Technologies (processing and generation services and tools, models, corpora, term lists, etc.), as well as related entities (e.g., organizations, projects, supporting documents, etc.). The schema powers the European Language Grid platform that aims to be the primary hub and marketplace for industry-relevant Language Technology in Europe. ELG-SHARE has been based on various metadata schemas, vocabularies, and ontologies, as well as related recommendations and guidelines.