 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned in ATCO2: 5000 hours of Air Traffic Control Communications for Robust Automatic Speech Recognition and Understanding
May 02, 2023

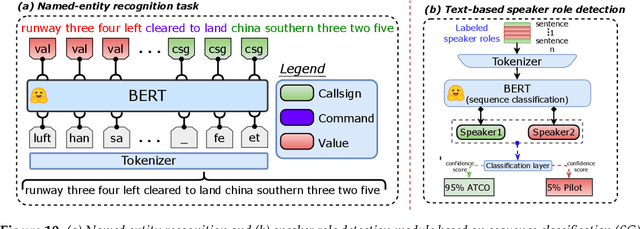

Voice communication between air traffic controllers (ATCos) and pilots is critical for ensuring safe and efficient air traffic control (ATC). This task requires high levels of awareness from ATCos and can be tedious and error-prone. Recent attempts have been made to integrate artificial intelligence (AI) into ATC in order to reduce the workload of ATCos. However, the development of data-driven AI systems for ATC demands large-scale annotated datasets, which are currently lacking in the field. This paper explores the lessons learned from the ATCO2 project, a project that aimed to develop a unique platform to collect and preprocess large amounts of ATC data from airspace in real time. Audio and surveillance data were collected from publicly accessible radio frequency channels with VHF receivers owned by a community of volunteers and later uploaded to Opensky Network servers, which can be considered an "unlimited source" of data. In addition, this paper reviews previous work from ATCO2 partners, including (i) robust automatic speech recognition, (ii) natural language processing, (iii) English language identification of ATC communications, and (iv) the integration of surveillance data such as ADS-B. We believe that the pipeline developed during the ATCO2 project, along with the open-sourcing of its data, will encourage research in the ATC field. A sample of the ATCO2 corpus is available on the following website: https://www.atco2.org/data, while the full corpus can be purchased through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. We demonstrated that ATCO2 is an appropriate dataset to develop ASR engines when little or near to no ATC in-domain data is available. For instance, with the CNN-TDNNf kaldi model, we reached the performance of as low as 17.9% and 24.9% WER on public ATC datasets which is 6.6/7.6% better than "out-of-domain" but supervised CNN-TDNNf model.
Fundamentals of Generative Large Language Models and Perspectives in Cyber-Defense
Mar 21, 2023Generative Language Models gained significant attention in late 2022 / early 2023, notably with the introduction of models refined to act consistently with users' expectations of interactions with AI (conversational models). Arguably the focal point of public attention has been such a refinement of the GPT3 model -- the ChatGPT and its subsequent integration with auxiliary capabilities, including search as part of Microsoft Bing. Despite extensive prior research invested in their development, their performance and applicability to a range of daily tasks remained unclear and niche. However, their wider utilization without a requirement for technical expertise, made in large part possible through conversational fine-tuning, revealed the extent of their true capabilities in a real-world environment. This has garnered both public excitement for their potential applications and concerns about their capabilities and potential malicious uses. This review aims to provide a brief overview of the history, state of the art, and implications of Generative Language Models in terms of their principles, abilities, limitations, and future prospects -- especially in the context of cyber-defense, with a focus on the Swiss operational environment.
Orchestrating Collaborative Cybersecurity: A Secure Framework for Distributed Privacy-Preserving Threat Intelligence Sharing
Sep 06, 2022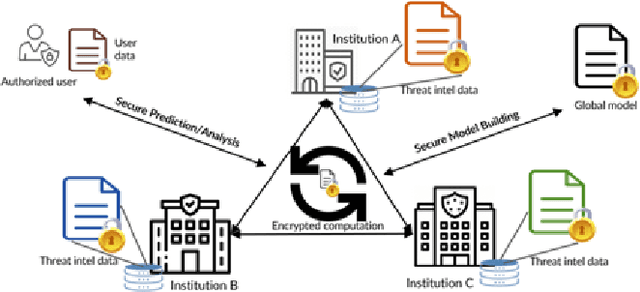

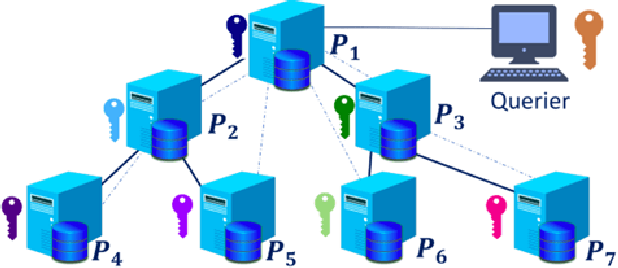
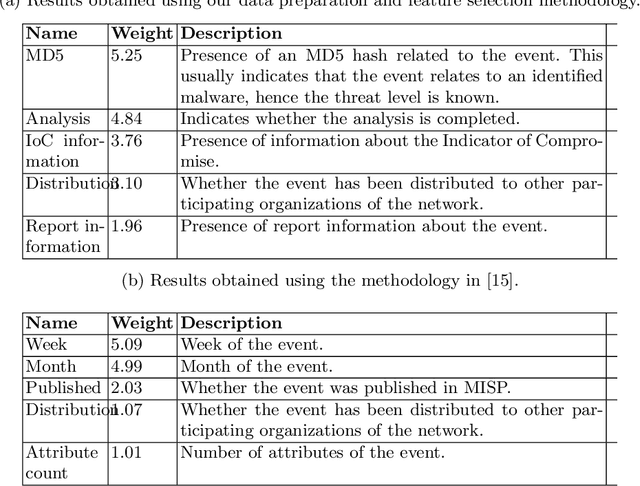
Cyber Threat Intelligence (CTI) sharing is an important activity to reduce information asymmetries between attackers and defenders. However, this activity presents challenges due to the tension between data sharing and confidentiality, that result in information retention often leading to a free-rider problem. Therefore, the information that is shared represents only the tip of the iceberg. Current literature assumes access to centralized databases containing all the information, but this is not always feasible, due to the aforementioned tension. This results in unbalanced or incomplete datasets, requiring the use of techniques to expand them; we show how these techniques lead to biased results and misleading performance expectations. We propose a novel framework for extracting CTI from distributed data on incidents, vulnerabilities and indicators of compromise, and demonstrate its use in several practical scenarios, in conjunction with the Malware Information Sharing Platforms (MISP). Policy implications for CTI sharing are presented and discussed. The proposed system relies on an efficient combination of privacy enhancing technologies and federated processing. This lets organizations stay in control of their CTI and minimize the risks of exposure or leakage, while enabling the benefits of sharing, more accurate and representative results, and more effective predictive and preventive defenses.
From Scattered Sources to Comprehensive Technology Landscape: A Recommendation-based Retrieval Approach
Dec 09, 2021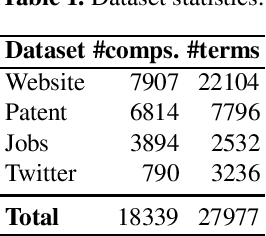
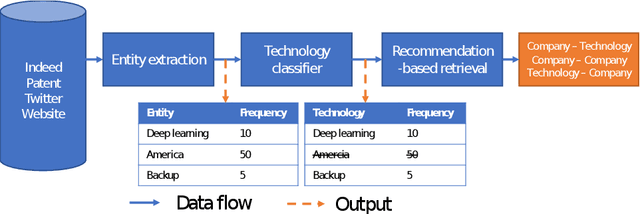
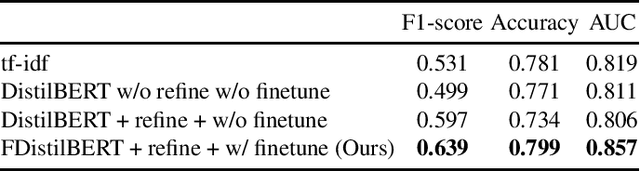
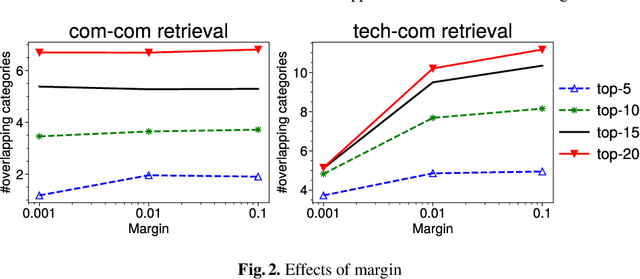
Mapping the technology landscape is crucial for market actors to take informed investment decisions. However, given the large amount of data on the Web and its subsequent information overload, manually retrieving information is a seemingly ineffective and incomplete approach. In this work, we propose an end-to-end recommendation based retrieval approach to support automatic retrieval of technologies and their associated companies from raw Web data. This is a two-task setup involving (i) technology classification of entities extracted from company corpus, and (ii) technology and company retrieval based on classified technologies. Our proposed framework approaches the first task by leveraging DistilBERT which is a state-of-the-art language model. For the retrieval task, we introduce a recommendation-based retrieval technique to simultaneously support retrieving related companies, technologies related to a specific company and companies relevant to a technology. To evaluate these tasks, we also construct a data set that includes company documents and entities extracted from these documents together with company categories and technology labels. Experiments show that our approach is able to return 4 times more relevant companies while outperforming traditional retrieval baseline in retrieving technologies.
Classi-Fly: Inferring Aircraft Categories from Open Data
Jul 30, 2019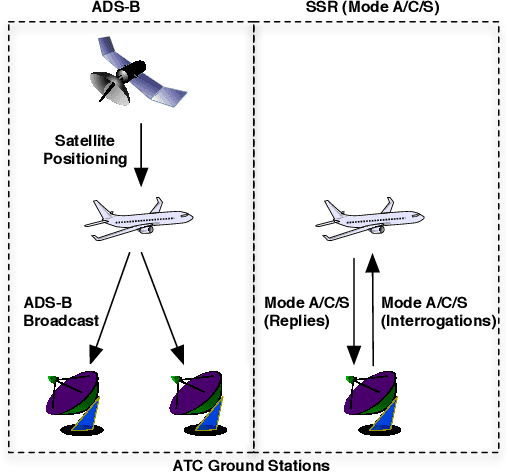
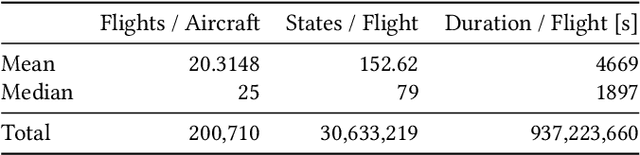
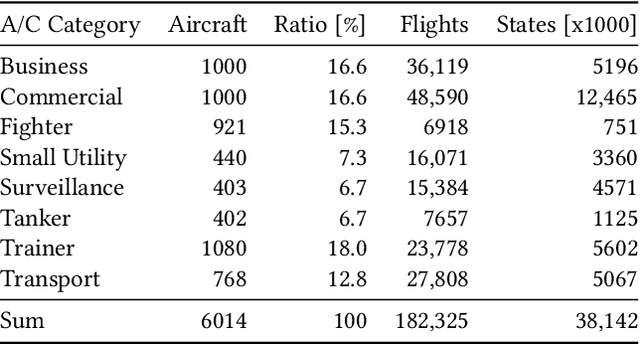
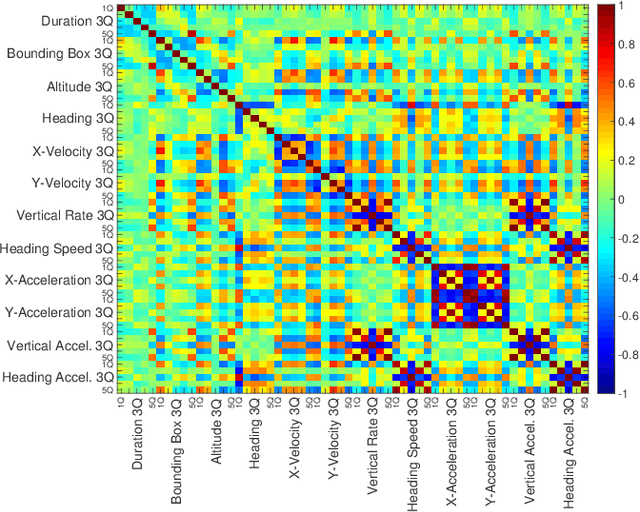
In recent years, air traffic communication data has become easy to access, enabling novel research in many fields. Exploiting this new data source, a wide range of applications have emerged, from weather forecasting to stock market prediction, or the collection of intelligence about military and government movements. Typically these applications require knowledge about the metadata of the aircraft, specifically its operator and the aircraft category. armasuisse Science + Technology, the R&D agency for the Swiss Armed Forces, has been developing Classi-Fly, a novel approach to obtain metadata about aircraft based on their movement patterns. We validate Classi-Fly using several hundred thousand flights collected through open source means, in conjunction with ground truth from publicly available aircraft registries containing more than two million aircraft. We show that we can obtain the correct aircraft category with an accuracy of over 88%. In cases, where no metadata is available, this approach can be used to create the data necessary for applications working with air traffic communication. Finally, we show that it is feasible to automatically detect sensitive aircraft such as police and surveillance aircraft using this method.