 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Model to Breach: Towards Actionable LLM-Generated Vulnerabilities Reporting
Nov 06, 2025As the role of Large Language Models (LLM)-based coding assistants in software development becomes more critical, so does the role of the bugs they generate in the overall cybersecurity landscape. While a number of LLM code security benchmarks have been proposed alongside approaches to improve the security of generated code, it remains unclear to what extent they have impacted widely used coding LLMs. Here, we show that even the latest open-weight models are vulnerable in the earliest reported vulnerability scenarios in a realistic use setting, suggesting that the safety-functionality trade-off has until now prevented effective patching of vulnerabilities. To help address this issue, we introduce a new severity metric that reflects the risk posed by an LLM-generated vulnerability, accounting for vulnerability severity, generation chance, and the formulation of the prompt that induces vulnerable code generation - Prompt Exposure (PE). To encourage the mitigation of the most serious and prevalent vulnerabilities, we use PE to define the Model Exposure (ME) score, which indicates the severity and prevalence of vulnerabilities a model generates.
Are the LLMs Capable of Maintaining at Least the Language Genus?
Oct 24, 2025Large Language Models (LLMs) display notable variation in multilingual behavior, yet the role of genealogical language structure in shaping this variation remains underexplored. In this paper, we investigate whether LLMs exhibit sensitivity to linguistic genera by extending prior analyses on the MultiQ dataset. We first check if models prefer to switch to genealogically related languages when prompt language fidelity is not maintained. Next, we investigate whether knowledge consistency is better preserved within than across genera. We show that genus-level effects are present but strongly conditioned by training resource availability. We further observe distinct multilingual strategies across LLMs families. Our findings suggest that LLMs encode aspects of genus-level structure, but training data imbalances remain the primary factor shaping their multilingual performance.
Extreme Multi-label Completion for Semantic Document Labelling with Taxonomy-Aware Parallel Learning
Dec 18, 2024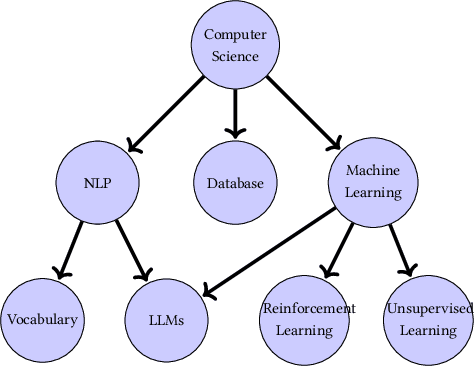
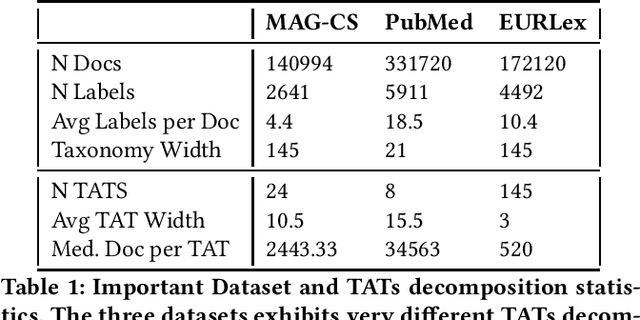
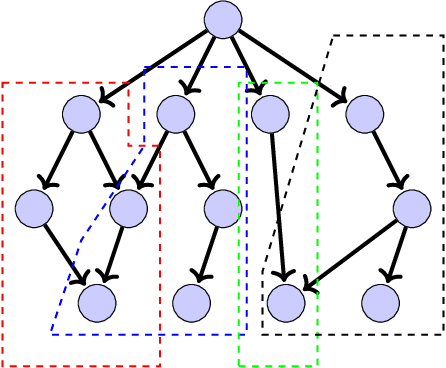
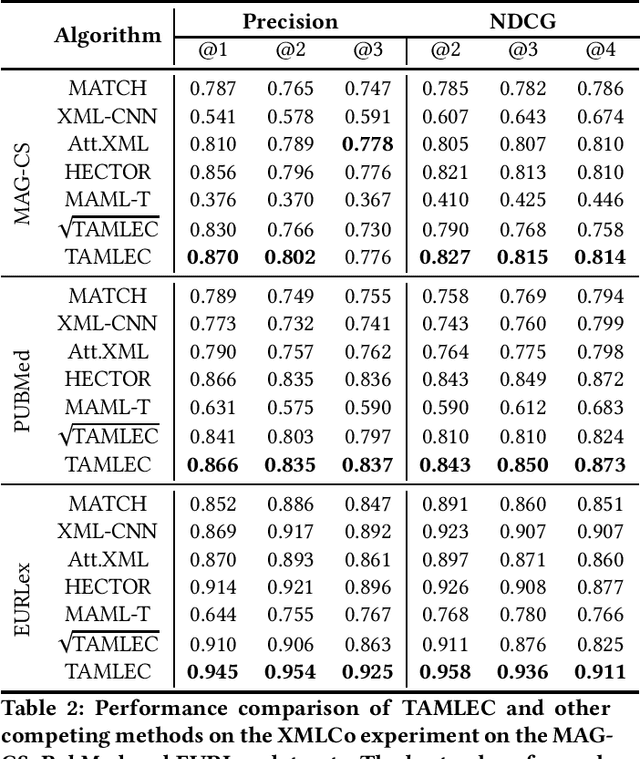
In Extreme Multi Label Completion (XMLCo), the objective is to predict the missing labels of a collection of documents. Together with XML Classification, XMLCo is arguably one of the most challenging document classification tasks, as the very high number of labels (at least ten of thousands) is generally very large compared to the number of available labelled documents in the training dataset. Such a task is often accompanied by a taxonomy that encodes the labels organic relationships, and many methods have been proposed to leverage this hierarchy to improve the results of XMLCo algorithms. In this paper, we propose a new approach to this problem, TAMLEC (Taxonomy-Aware Multi-task Learning for Extreme multi-label Completion). TAMLEC divides the problem into several Taxonomy-Aware Tasks, i.e. subsets of labels adapted to the hierarchical paths of the taxonomy, and trains on these tasks using a dynamic Parallel Feature sharing approach, where some parts of the model are shared between tasks while others are task-specific. Then, at inference time, TAMLEC uses the labels available in a document to infer the appropriate tasks and to predict missing labels. To achieve this result, TAMLEC uses a modified transformer architecture that predicts ordered sequences of labels on a Weak-Semilattice structure that is naturally induced by the tasks. This approach yields multiple advantages. First, our experiments on real-world datasets show that TAMLEC outperforms state-of-the-art methods for various XMLCo problems. Second, TAMLEC is by construction particularly suited for few-shots XML tasks, where new tasks or labels are introduced with only few examples, and extensive evaluations highlight its strong performance compared to existing methods.
NMT-Obfuscator Attack: Ignore a sentence in translation with only one word
Nov 19, 2024



Neural Machine Translation systems are used in diverse applications due to their impressive performance. However, recent studies have shown that these systems are vulnerable to carefully crafted small perturbations to their inputs, known as adversarial attacks. In this paper, we propose a new type of adversarial attack against NMT models. In this attack, we find a word to be added between two sentences such that the second sentence is ignored and not translated by the NMT model. The word added between the two sentences is such that the whole adversarial text is natural in the source language. This type of attack can be harmful in practical scenarios since the attacker can hide malicious information in the automatic translation made by the target NMT model. Our experiments show that different NMT models and translation tasks are vulnerable to this type of attack. Our attack can successfully force the NMT models to ignore the second part of the input in the translation for more than 50% of all cases while being able to maintain low perplexity for the whole input.
Can the Variation of Model Weights be used as a Criterion for Self-Paced Multilingual NMT?
Oct 05, 2024Many-to-one neural machine translation systems improve over one-to-one systems when training data is scarce. In this paper, we design and test a novel algorithm for selecting the language of minibatches when training such systems. The algorithm changes the language of the minibatch when the weights of the model do not evolve significantly, as measured by the smoothed KL divergence between all layers of the Transformer network. This algorithm outperforms the use of alternating monolingual batches, but not the use of shuffled batches, in terms of translation quality (measured with BLEU and COMET) and convergence speed.
LLM Detectors Still Fall Short of Real World: Case of LLM-Generated Short News-Like Posts
Sep 05, 2024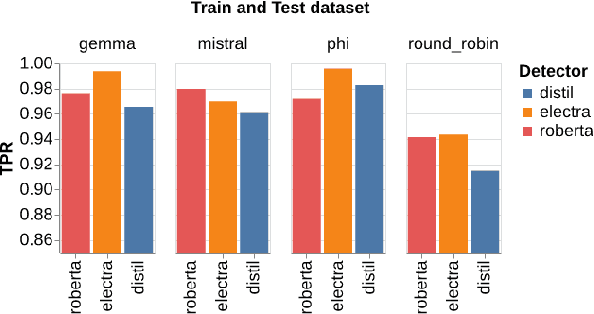


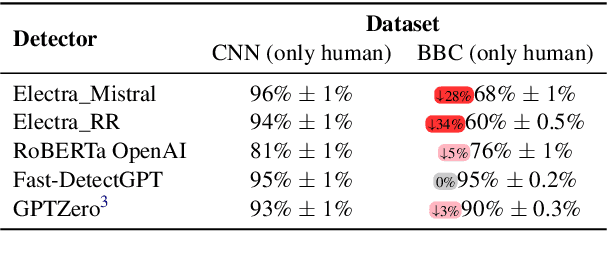
With the emergence of widely available powerful LLMs, disinformation generated by large Language Models (LLMs) has become a major concern. Historically, LLM detectors have been touted as a solution, but their effectiveness in the real world is still to be proven. In this paper, we focus on an important setting in information operations -- short news-like posts generated by moderately sophisticated attackers. We demonstrate that existing LLM detectors, whether zero-shot or purpose-trained, are not ready for real-world use in that setting. All tested zero-shot detectors perform inconsistently with prior benchmarks and are highly vulnerable to sampling temperature increase, a trivial attack absent from recent benchmarks. A purpose-trained detector generalizing across LLMs and unseen attacks can be developed, but it fails to generalize to new human-written texts. We argue that the former indicates domain-specific benchmarking is needed, while the latter suggests a trade-off between the adversarial evasion resilience and overfitting to the reference human text, with both needing evaluation in benchmarks and currently absent. We believe this suggests a re-consideration of current LLM detector benchmarking approaches and provides a dynamically extensible benchmark to allow it (https://github.com/Reliable-Information-Lab-HEVS/dynamic_llm_detector_benchmark).
Sparse vs Contiguous Adversarial Pixel Perturbations in Multimodal Models: An Empirical Analysis
Jul 25, 2024Assessing the robustness of multimodal models against adversarial examples is an important aspect for the safety of its users. We craft L0-norm perturbation attacks on the preprocessed input images. We launch them in a black-box setup against four multimodal models and two unimodal DNNs, considering both targeted and untargeted misclassification. Our attacks target less than 0.04% of perturbed image area and integrate different spatial positioning of perturbed pixels: sparse positioning and pixels arranged in different contiguous shapes (row, column, diagonal, and patch). To the best of our knowledge, we are the first to assess the robustness of three state-of-the-art multimodal models (ALIGN, AltCLIP, GroupViT) against different sparse and contiguous pixel distribution perturbations. The obtained results indicate that unimodal DNNs are more robust than multimodal models. Furthermore, models using CNN-based Image Encoder are more vulnerable than models with ViT - for untargeted attacks, we obtain a 99% success rate by perturbing less than 0.02% of the image area.
Do Large Language Models Exhibit Cognitive Dissonance? Studying the Difference Between Revealed Beliefs and Stated Answers
Jun 21, 2024Prompting and Multiple Choices Questions (MCQ) have become the preferred approach to assess the capabilities of Large Language Models (LLMs), due to their ease of manipulation and evaluation. Such experimental appraisals have pointed toward the LLMs' apparent ability to perform causal reasoning or to grasp uncertainty. In this paper, we investigate whether these abilities are measurable outside of tailored prompting and MCQ by reformulating these issues as direct text completion - the foundation of LLMs. To achieve this goal, we define scenarios with multiple possible outcomes and we compare the prediction made by the LLM through prompting (their Stated Answer) to the probability distributions they compute over these outcomes during next token prediction (their Revealed Belief). Our findings suggest that the Revealed Belief of LLMs significantly differs from their Stated Answer and hint at multiple biases and misrepresentations that their beliefs may yield in many scenarios and outcomes. As text completion is at the core of LLMs, these results suggest that common evaluation methods may only provide a partial picture and that more research is needed to assess the extent and nature of their capabilities.
A Classification-Guided Approach for Adversarial Attacks against Neural Machine Translation
Aug 29, 2023Neural Machine Translation (NMT) models have been shown to be vulnerable to adversarial attacks, wherein carefully crafted perturbations of the input can mislead the target model. In this paper, we introduce ACT, a novel adversarial attack framework against NMT systems guided by a classifier. In our attack, the adversary aims to craft meaning-preserving adversarial examples whose translations by the NMT model belong to a different class than the original translations in the target language. Unlike previous attacks, our new approach has a more substantial effect on the translation by altering the overall meaning, which leads to a different class determined by a classifier. To evaluate the robustness of NMT models to this attack, we propose enhancements to existing black-box word-replacement-based attacks by incorporating output translations of the target NMT model and the output logits of a classifier within the attack process. Extensive experiments in various settings, including a comparison with existing untargeted attacks, demonstrate that the proposed attack is considerably more successful in altering the class of the output translation and has more effect on the translation. This new paradigm can show the vulnerabilities of NMT systems by focusing on the class of translation rather than the mere translation quality as studied traditionally.
A Relaxed Optimization Approach for Adversarial Attacks against Neural Machine Translation Models
Jun 14, 2023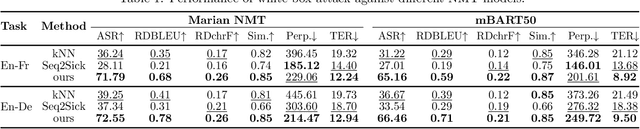
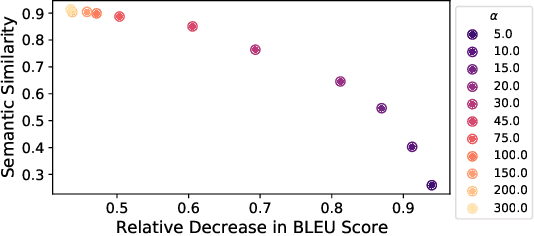

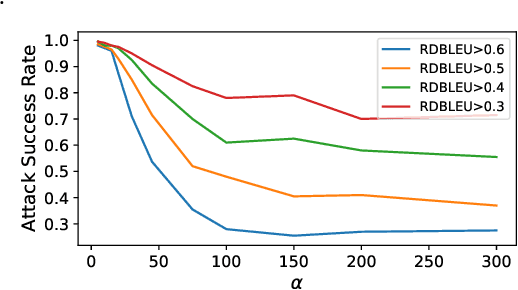
In this paper, we propose an optimization-based adversarial attack against Neural Machine Translation (NMT) models. First, we propose an optimization problem to generate adversarial examples that are semantically similar to the original sentences but destroy the translation generated by the target NMT model. This optimization problem is discrete, and we propose a continuous relaxation to solve it. With this relaxation, we find a probability distribution for each token in the adversarial example, and then we can generate multiple adversarial examples by sampling from these distributions. Experimental results show that our attack significantly degrades the translation quality of multiple NMT models while maintaining the semantic similarity between the original and adversarial sentences. Furthermore, our attack outperforms the baselines in terms of success rate, similarity preservation, effect on translation quality, and token error rate. Finally, we propose a black-box extension of our attack by sampling from an optimized probability distribution for a reference model whose gradients are accessible.