 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Agents and the Understanding of Human Language: Reflections on AI, LLMs, and Cognitive Science
Mar 29, 2026In this paper, we discuss the relationship between natural language processing by computers (NLP) and the understanding of the human language capacity, as studied by linguistics and cognitive science. We outline the evolution of NLP from its beginnings until the age of large language models, and highlight for each of its main paradigms some similarities and differences with theories of the human language capacity. We conclude that the evolution of language technology has not substantially deepened our understanding of how human minds process natural language, despite the impressive language abilities attained by current chatbots using artificial neural networks.
Optimizing the Training Schedule of Multilingual NMT using Reinforcement Learning
Oct 08, 2024



Multilingual NMT is a viable solution for translating low-resource languages (LRLs) when data from high-resource languages (HRLs) from the same language family is available. However, the training schedule, i.e. the order of presentation of languages, has an impact on the quality of such systems. Here, in a many-to-one translation setting, we propose to apply two algorithms that use reinforcement learning to optimize the training schedule of NMT: (1) Teacher-Student Curriculum Learning and (2) Deep Q Network. The former uses an exponentially smoothed estimate of the returns of each action based on the loss on monolingual or multilingual development subsets, while the latter estimates rewards using an additional neural network trained from the history of actions selected in different states of the system, together with the rewards received. On a 8-to-1 translation dataset with LRLs and HRLs, our second method improves BLEU and COMET scores with respect to both random selection of monolingual batches and shuffled multilingual batches, by adjusting the number of presentations of LRL vs. HRL batches.
Can the Variation of Model Weights be used as a Criterion for Self-Paced Multilingual NMT?
Oct 05, 2024Many-to-one neural machine translation systems improve over one-to-one systems when training data is scarce. In this paper, we design and test a novel algorithm for selecting the language of minibatches when training such systems. The algorithm changes the language of the minibatch when the weights of the model do not evolve significantly, as measured by the smoothed KL divergence between all layers of the Transformer network. This algorithm outperforms the use of alternating monolingual batches, but not the use of shuffled batches, in terms of translation quality (measured with BLEU and COMET) and convergence speed.
Don't Rank, Combine! Combining Machine Translation Hypotheses Using Quality Estimation
Jan 12, 2024



Neural machine translation systems estimate probabilities of target sentences given source sentences, yet these estimates may not align with human preferences. This work introduces QE-fusion, a method utilizing a quality estimation metric (QE) that better correlates with human judgments to synthesize improved translations. QE-fusion leverages a candidate pool sampled from a model, combining spans from different candidates using QE metrics such as CometKiwi. We compare QE-fusion against beam search and recent reranking techniques, such as Minimum Bayes Risk decoding or QE-reranking. Our method consistently improves translation quality in terms of COMET and BLEURT scores when applied to large language models (LLMs) used for translation (PolyLM, XGLM, Llama2, and Mistral) and to multilingual translation models (NLLB), over five language pairs. Notably, QE-fusion exhibits larger improvements for LLMs due to their ability to generate diverse outputs. We demonstrate that our approach generates novel translations in over half of the cases and consistently outperforms other methods across varying numbers of candidates (5-200). Furthermore, we empirically establish that QE-fusion scales linearly with the number of candidates in the pool. QE-fusion proves effective in enhancing LLM-based translation without the need for costly retraining of LLMs.
Assessing the Importance of Frequency versus Compositionality for Subword-based Tokenization in NMT
Jun 05, 2023



Subword tokenization is the de facto standard for tokenization in neural language models and machine translation systems. Three advantages are frequently cited in favor of subwords: shorter encoding of frequent tokens, compositionality of subwords, and ability to deal with unknown words. As their relative importance is not entirely clear yet, we propose a tokenization approach that enables us to separate frequency (the first advantage) from compositionality. The approach uses Huffman coding to tokenize words, by order of frequency, using a fixed amount of symbols. Experiments with CS-DE, EN-FR and EN-DE NMT show that frequency alone accounts for 90%-95% of the scores reached by BPE, hence compositionality has less importance than previously thought.
Small Batch Sizes Improve Training of Low-Resource Neural MT
Mar 20, 2022
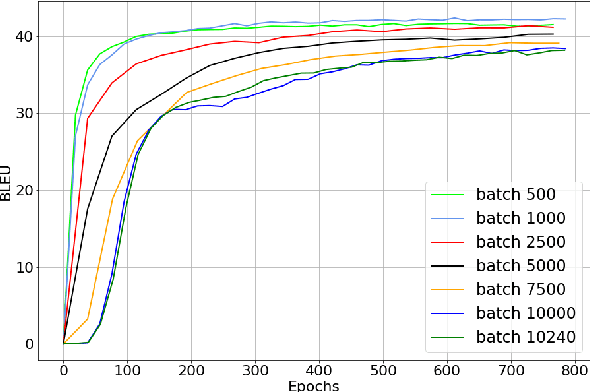
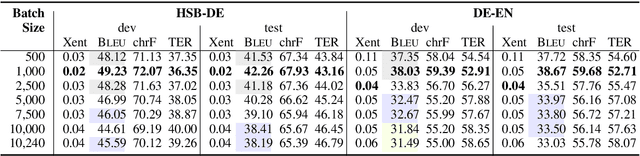

We study the role of an essential hyper-parameter that governs the training of Transformers for neural machine translation in a low-resource setting: the batch size. Using theoretical insights and experimental evidence, we argue against the widespread belief that batch size should be set as large as allowed by the memory of the GPUs. We show that in a low-resource setting, a smaller batch size leads to higher scores in a shorter training time, and argue that this is due to better regularization of the gradients during training.
Subword Mapping and Anchoring across Languages
Sep 09, 2021

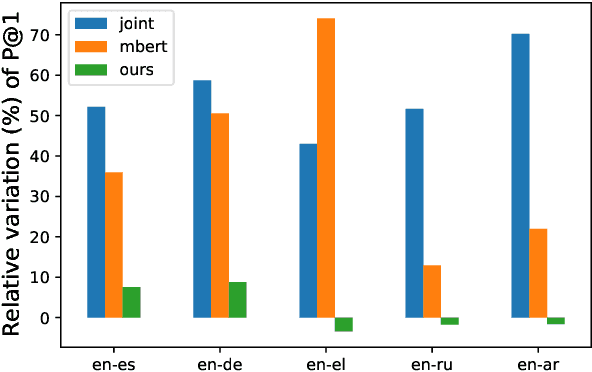
State-of-the-art multilingual systems rely on shared vocabularies that sufficiently cover all considered languages. To this end, a simple and frequently used approach makes use of subword vocabularies constructed jointly over several languages. We hypothesize that such vocabularies are suboptimal due to false positives (identical subwords with different meanings across languages) and false negatives (different subwords with similar meanings). To address these issues, we propose Subword Mapping and Anchoring across Languages (SMALA), a method to construct bilingual subword vocabularies. SMALA extracts subword alignments using an unsupervised state-of-the-art mapping technique and uses them to create cross-lingual anchors based on subword similarities. We demonstrate the benefits of SMALA for cross-lingual natural language inference (XNLI), where it improves zero-shot transfer to an unseen language without task-specific data, but only by sharing subword embeddings. Moreover, in neural machine translation, we show that joint subword vocabularies obtained with SMALA lead to higher BLEU scores on sentences that contain many false positives and false negatives.
Findings of the 2016 WMT Shared Task on Cross-lingual Pronoun Prediction
Nov 27, 2019



We describe the design, the evaluation setup, and the results of the 2016 WMT shared task on cross-lingual pronoun prediction. This is a classification task in which participants are asked to provide predictions on what pronoun class label should replace a placeholder value in the target-language text, provided in lemmatised and PoS-tagged form. We provided four subtasks, for the English-French and English-German language pairs, in both directions. Eleven teams participated in the shared task; nine for the English-French subtask, five for French-English, nine for English-German, and six for German-English. Most of the submissions outperformed two strong language-model based baseline systems, with systems using deep recurrent neural networks outperforming those using other architectures for most language pairs.
* cross-lingual pronoun prediction, WMT, shared task, English, German, French
Context in Neural Machine Translation: A Review of Models and Evaluations
Jan 25, 2019This review paper discusses how context has been used in neural machine translation (NMT) in the past two years (2017-2018). Starting with a brief retrospect on the rapid evolution of NMT models, the paper then reviews studies that evaluate NMT output from various perspectives, with emphasis on those analyzing limitations of the translation of contextual phenomena. In a subsequent version, the paper will then present the main methods that were proposed to leverage context for improving translation quality, and distinguishes methods that aim to improve the translation of specific phenomena from those that consider a wider unstructured context.
Self-Attentive Residual Decoder for Neural Machine Translation
Oct 01, 2018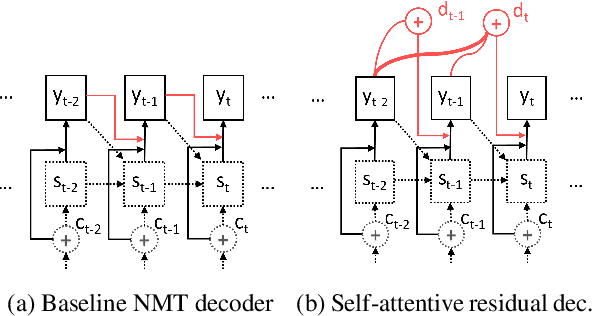



Neural sequence-to-sequence networks with attention have achieved remarkable performance for machine translation. One of the reasons for their effectiveness is their ability to capture relevant source-side contextual information at each time-step prediction through an attention mechanism. However, the target-side context is solely based on the sequence model which, in practice, is prone to a recency bias and lacks the ability to capture effectively non-sequential dependencies among words. To address this limitation, we propose a target-side-attentive residual recurrent network for decoding, where attention over previous words contributes directly to the prediction of the next word. The residual learning facilitates the flow of information from the distant past and is able to emphasize any of the previously translated words, hence it gains access to a wider context. The proposed model outperforms a neural MT baseline as well as a memory and self-attention network on three language pairs. The analysis of the attention learned by the decoder confirms that it emphasizes a wider context, and that it captures syntactic-like structures.