 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Rank, Combine! Combining Machine Translation Hypotheses Using Quality Estimation
Jan 12, 2024



Neural machine translation systems estimate probabilities of target sentences given source sentences, yet these estimates may not align with human preferences. This work introduces QE-fusion, a method utilizing a quality estimation metric (QE) that better correlates with human judgments to synthesize improved translations. QE-fusion leverages a candidate pool sampled from a model, combining spans from different candidates using QE metrics such as CometKiwi. We compare QE-fusion against beam search and recent reranking techniques, such as Minimum Bayes Risk decoding or QE-reranking. Our method consistently improves translation quality in terms of COMET and BLEURT scores when applied to large language models (LLMs) used for translation (PolyLM, XGLM, Llama2, and Mistral) and to multilingual translation models (NLLB), over five language pairs. Notably, QE-fusion exhibits larger improvements for LLMs due to their ability to generate diverse outputs. We demonstrate that our approach generates novel translations in over half of the cases and consistently outperforms other methods across varying numbers of candidates (5-200). Furthermore, we empirically establish that QE-fusion scales linearly with the number of candidates in the pool. QE-fusion proves effective in enhancing LLM-based translation without the need for costly retraining of LLMs.
Assessing the Importance of Frequency versus Compositionality for Subword-based Tokenization in NMT
Jun 05, 2023Subword tokenization is the de facto standard for tokenization in neural language models and machine translation systems. Three advantages are frequently cited in favor of subwords: shorter encoding of frequent tokens, compositionality of subwords, and ability to deal with unknown words. As their relative importance is not entirely clear yet, we propose a tokenization approach that enables us to separate frequency (the first advantage) from compositionality. The approach uses Huffman coding to tokenize words, by order of frequency, using a fixed amount of symbols. Experiments with CS-DE, EN-FR and EN-DE NMT show that frequency alone accounts for 90%-95% of the scores reached by BPE, hence compositionality has less importance than previously thought.
Small Language Models Improve Giants by Rewriting Their Outputs
May 22, 2023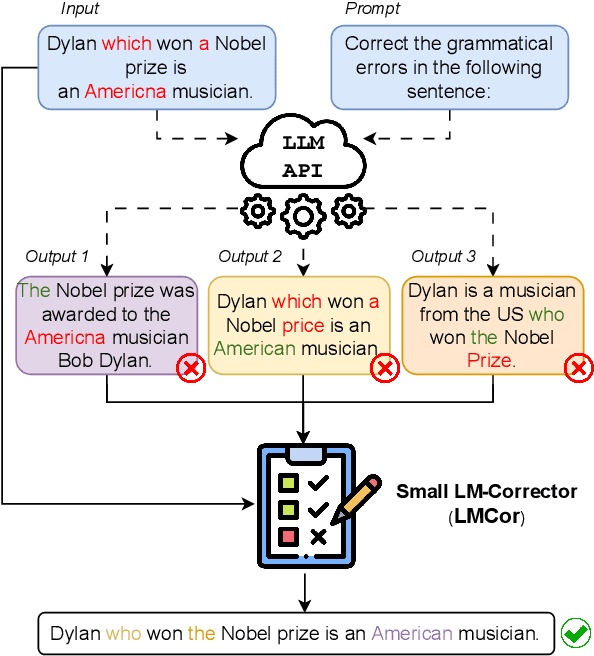
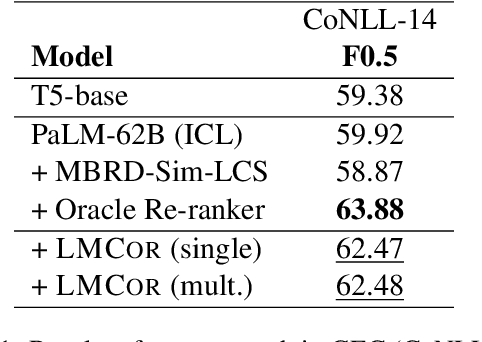
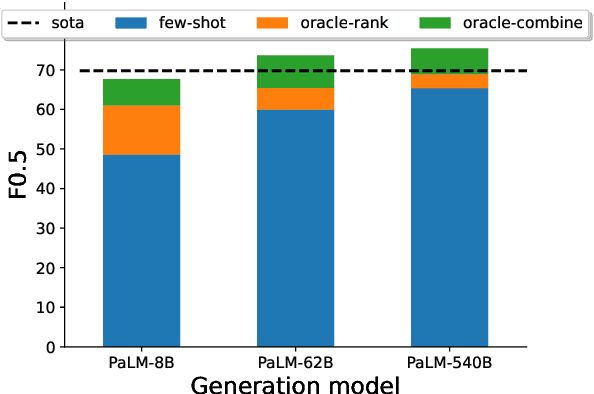

Large language models (LLMs) have demonstrated impressive few-shot learning capabilities, but they often underperform compared to fine-tuned models on challenging tasks. Furthermore, their large size and restricted access only through APIs make task-specific fine-tuning impractical. Moreover, LLMs are sensitive to different aspects of prompts (e.g., the selection and order of demonstrations) and can thus require time-consuming prompt engineering. In this light, we propose a method to correct LLM outputs without relying on their weights. First, we generate a pool of candidates by few-shot prompting an LLM. Second, we refine the LLM-generated outputs using a smaller model, the LM-corrector (LMCor), which is trained to rank, combine and rewrite the candidates to produce the final target output. Our experiments demonstrate that even a small LMCor model (250M) substantially improves the few-shot performance of LLMs (62B) across diverse tasks. Moreover, we illustrate that the LMCor exhibits robustness against different prompts, thereby minimizing the need for extensive prompt engineering. Finally, we showcase that the LMCor can be seamlessly integrated with different LLMs at inference time, serving as a plug-and-play module to improve their performance.
Embarrassingly Easy Document-Level MT Metrics: How to Convert Any Pretrained Metric Into a Document-Level Metric
Sep 27, 2022



We hypothesize that existing sentence-level machine translation (MT) metrics become less effective when the human reference contains ambiguities. To verify this hypothesis, we present a very simple method for extending pretrained metrics to incorporate context at the document level. We apply our method to three popular metrics, BERTScore, Prism, and COMET, and to the reference free metric COMET-QE. We evaluate the extended metrics on the WMT 2021 metrics shared task using the provided MQM annotations. Our results show that the extended metrics outperform their sentence-level counterparts in about 85% of the tested conditions, when excluding results on low-quality human references. Additionally, we show that our document-level extension of COMET-QE dramatically improves its accuracy on discourse phenomena tasks, outperforming a dedicated baseline by up to 6.1%. Our experimental results support our initial hypothesis and show that a simple extension of the metrics permits them to take advantage of context to resolve ambiguities in the reference.
Subword Mapping and Anchoring across Languages
Sep 09, 2021
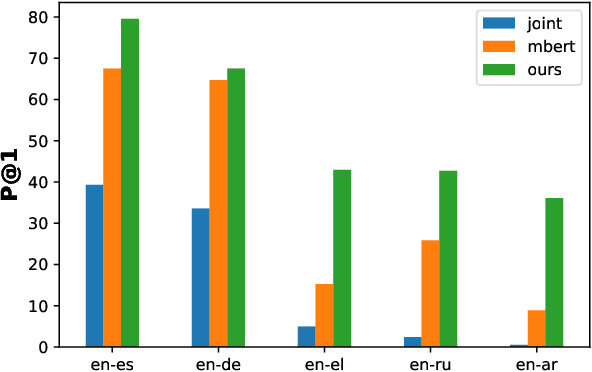

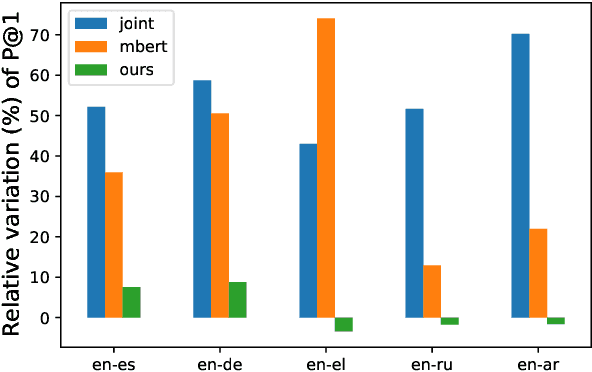
State-of-the-art multilingual systems rely on shared vocabularies that sufficiently cover all considered languages. To this end, a simple and frequently used approach makes use of subword vocabularies constructed jointly over several languages. We hypothesize that such vocabularies are suboptimal due to false positives (identical subwords with different meanings across languages) and false negatives (different subwords with similar meanings). To address these issues, we propose Subword Mapping and Anchoring across Languages (SMALA), a method to construct bilingual subword vocabularies. SMALA extracts subword alignments using an unsupervised state-of-the-art mapping technique and uses them to create cross-lingual anchors based on subword similarities. We demonstrate the benefits of SMALA for cross-lingual natural language inference (XNLI), where it improves zero-shot transfer to an unseen language without task-specific data, but only by sharing subword embeddings. Moreover, in neural machine translation, we show that joint subword vocabularies obtained with SMALA lead to higher BLEU scores on sentences that contain many false positives and false negatives.
Active Learning by Acquiring Contrastive Examples
Sep 08, 2021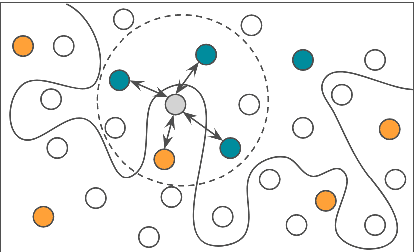
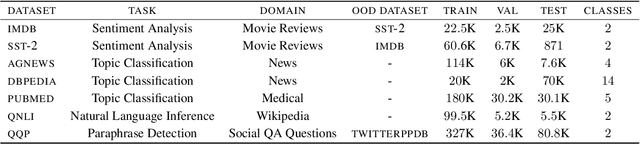
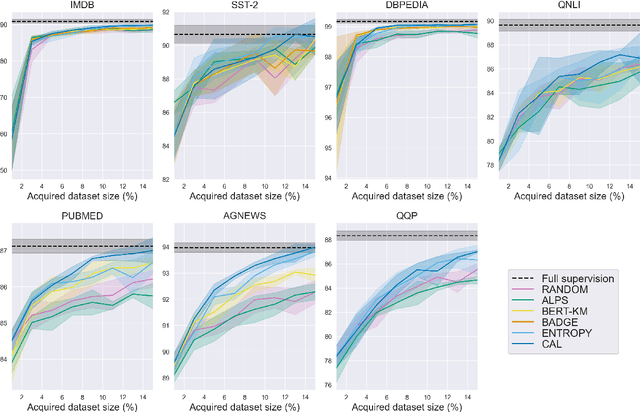
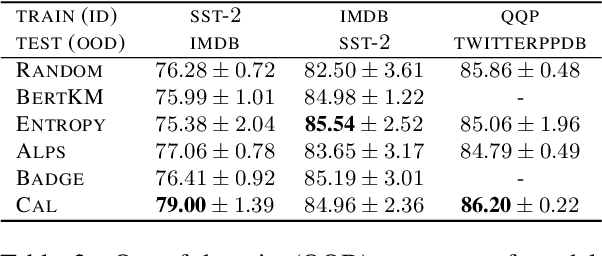
Common acquisition functions for active learning use either uncertainty or diversity sampling, aiming to select difficult and diverse data points from the pool of unlabeled data, respectively. In this work, leveraging the best of both worlds, we propose an acquisition function that opts for selecting \textit{contrastive examples}, i.e. data points that are similar in the model feature space and yet the model outputs maximally different predictive likelihoods. We compare our approach, CAL (Contrastive Active Learning), with a diverse set of acquisition functions in four natural language understanding tasks and seven datasets. Our experiments show that CAL performs consistently better or equal than the best performing baseline across all tasks, on both in-domain and out-of-domain data. We also conduct an extensive ablation study of our method and we further analyze all actively acquired datasets showing that CAL achieves a better trade-off between uncertainty and diversity compared to other strategies.
Domain Adversarial Fine-Tuning as an Effective Regularizer
Oct 05, 2020


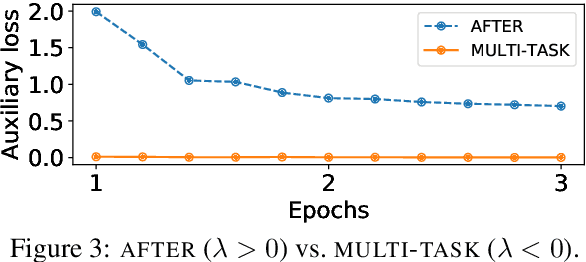
In Natural Language Processing (NLP), pretrained language models (LMs) that are transferred to downstream tasks have been recently shown to achieve state-of-the-art results. However, standard fine-tuning can degrade the general-domain representations captured during pretraining. To address this issue, we introduce a new regularization technique, AFTER; domain Adversarial Fine-Tuning as an Effective Regularizer. Specifically, we complement the task-specific loss used during fine-tuning with an adversarial objective. This additional loss term is related to an adversarial classifier, that aims to discriminate between in-domain and out-of-domain text representations. In-domain refers to the labeled dataset of the task at hand while out-of-domain refers to unlabeled data from a different domain. Intuitively, the adversarial classifier acts as a regularizer which prevents the model from overfitting to the task-specific domain. Empirical results on various natural language understanding tasks show that AFTER leads to improved performance compared to standard fine-tuning.