 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adversarial Fine-Tuning as an Effective Regularizer
Paper and Code



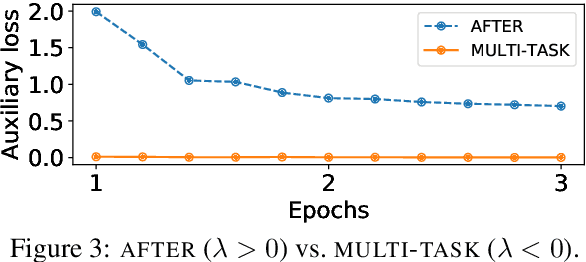
In Natural Language Processing (NLP), pretrained language models (LMs) that are transferred to downstream tasks have been recently shown to achieve state-of-the-art results. However, standard fine-tuning can degrade the general-domain representations captured during pretraining. To address this issue, we introduce a new regularization technique, AFTER; domain Adversarial Fine-Tuning as an Effective Regularizer. Specifically, we complement the task-specific loss used during fine-tuning with an adversarial objective. This additional loss term is related to an adversarial classifier, that aims to discriminate between in-domain and out-of-domain text representations. In-domain refers to the labeled dataset of the task at hand while out-of-domain refers to unlabeled data from a different domain. Intuitively, the adversarial classifier acts as a regularizer which prevents the model from overfitting to the task-specific domain. Empirical results on various natural language understanding tasks show that AFTER leads to improved performance compared to standard fine-tuning.