 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreekBarBench: A Challenging Benchmark for Free-Text Legal Reasoning and Citations
May 22, 2025We introduce GreekBarBench, a benchmark that evaluates LLMs on legal questions across five different legal areas from the Greek Bar exams, requiring citations to statutory articles and case facts. To tackle the challenges of free-text evaluation, we propose a three-dimensional scoring system combined with an LLM-as-a-judge approach. We also develop a meta-evaluation benchmark to assess the correlation between LLM-judges and human expert evaluations, revealing that simple, span-based rubrics improve their alignment. Our systematic evaluation of 13 proprietary and open-weight LLMs shows that even though the best models outperform average expert scores, they fall short of the 95th percentile of experts.
Evaluation and Facilitation of Online Discussions in the LLM Era: A Survey
Mar 03, 2025
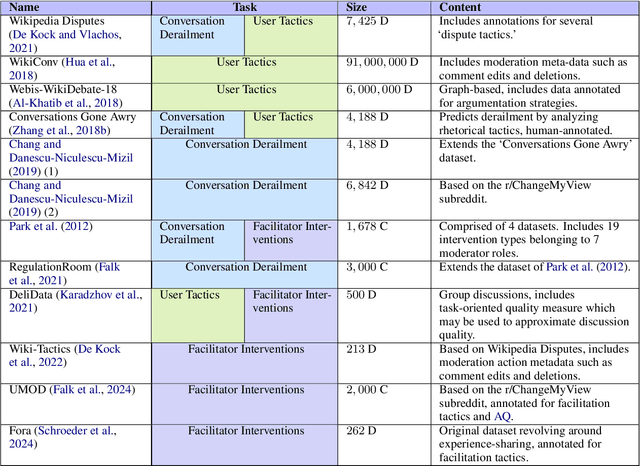


We present a survey of methods for assessing and enhancing the quality of online discussions, focusing on the potential of Large Language Models (LLMs). While online discourses aim, at least in theory, to foster mutual understanding, they often devolve into harmful exchanges, such as hate speech, threatening social cohesion and democratic values. Recent advancements in LLMs enable facilitation agents that not only moderate content, but also actively improve the quality of interactions. Our survey synthesizes ideas from Natural Language Processing (NLP) and Social Sciences to provide (a) a new taxonomy on discussion quality evaluation, (b) an overview of intervention and facilitation strategies, along with a new taxonomy on conversation facilitation datasets, (c) an LLM-oriented roadmap of good practices and future research directions, from technological and societal perspectives.
AUEB-Archimedes at RIRAG-2025: Is obligation concatenation really all you need?
Dec 16, 2024



This paper presents the systems we developed for RIRAG-2025, a shared task that requires answering regulatory questions by retrieving relevant passages. The generated answers are evaluated using RePASs, a reference-free and model-based metric. Our systems use a combination of three retrieval models and a reranker. We show that by exploiting a neural component of RePASs that extracts important sentences ('obligations') from the retrieved passages, we achieve a dubiously high score (0.947), even though the answers are directly extracted from the retrieved passages and are not actually generated answers. We then show that by selecting the answer with the best RePASs among a few generated alternatives and then iteratively refining this answer by reducing contradictions and covering more obligations, we can generate readable, coherent answers that achieve a more plausible and relatively high score (0.639).
GR-NLP-TOOLKIT: An Open-Source NLP Toolkit for Modern Greek
Dec 11, 2024

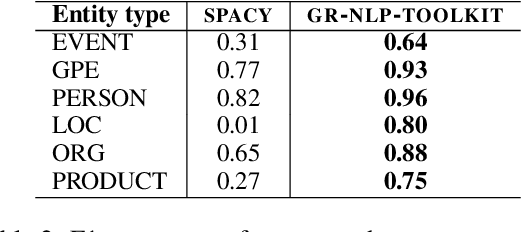
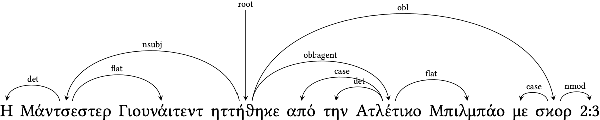
We present GR-NLP-TOOLKIT, an open-source natural language processing (NLP) toolkit developed specifically for modern Greek. The toolkit provides state-of-the-art performance in five core NLP tasks, namely part-of-speech tagging, morphological tagging, dependency parsing, named entity recognition, and Greeklishto-Greek transliteration. The toolkit is based on pre-trained Transformers, it is freely available, and can be easily installed in Python (pip install gr-nlp-toolkit). It is also accessible through a demonstration platform on HuggingFace, along with a publicly available API for non-commercial use. We discuss the functionality provided for each task, the underlying methods, experiments against comparable open-source toolkits, and future possible enhancements. The toolkit is available at: https://github.com/nlpaueb/gr-nlp-toolkit
LAR-ECHR: A New Legal Argument Reasoning Task and Dataset for Cases of the European Court of Human Rights
Oct 17, 2024



We present Legal Argument Reasoning (LAR), a novel task designed to evaluate the legal reasoning capabilities of Large Language Models (LLMs). The task requires selecting the correct next statement (from multiple choice options) in a chain of legal arguments from court proceedings, given the facts of the case. We constructed a dataset (LAR-ECHR) for this task using cases from the European Court of Human Rights (ECHR). We evaluated seven general-purpose LLMs on LAR-ECHR and found that (a) the ranking of the models is aligned with that of LegalBench, an established US-based legal reasoning benchmark, even though LAR-ECHR is based on EU law, (b) LAR-ECHR distinguishes top models more clearly, compared to LegalBench, (c) even the best model (GPT-4o) obtains 75.8% accuracy on LAR-ECHR, indicating significant potential for further model improvement. The process followed to construct LAR-ECHR can be replicated with cases from other legal systems.
A Data-Driven Guided Decoding Mechanism for Diagnostic Captioning
Jun 20, 2024



Diagnostic Captioning (DC) automatically generates a diagnostic text from one or more medical images (e.g., X-rays, MRIs) of a patient. Treated as a draft, the generated text may assist clinicians, by providing an initial estimation of the patient's condition, speeding up and helping safeguard the diagnostic process. The accuracy of a diagnostic text, however, strongly depends on how well the key medical conditions depicted in the images are expressed. We propose a new data-driven guided decoding method that incorporates medical information, in the form of existing tags capturing key conditions of the image(s), into the beam search of the diagnostic text generation process. We evaluate the proposed method on two medical datasets using four DC systems that range from generic image-to-text systems with CNN encoders and RNN decoders to pre-trained Large Language Models. The latter can also be used in few- and zero-shot learning scenarios. In most cases, the proposed mechanism improves performance with respect to all evaluation measures. We provide an open-source implementation of the proposed method at https://github.com/nlpaueb/dmmcs.
Comparing Data Augmentation Methods for End-to-End Task-Oriented Dialog Systems
Jun 10, 2024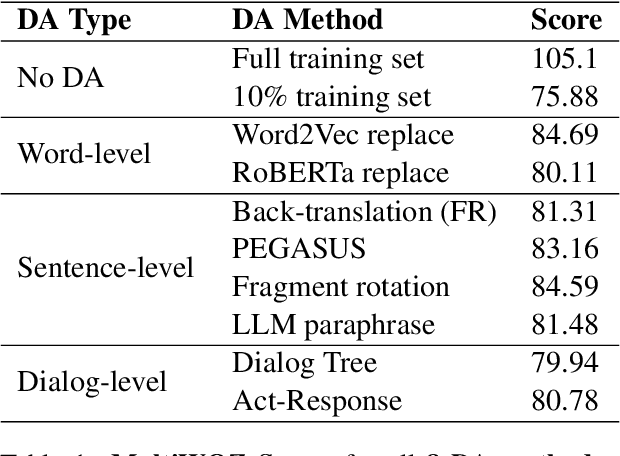
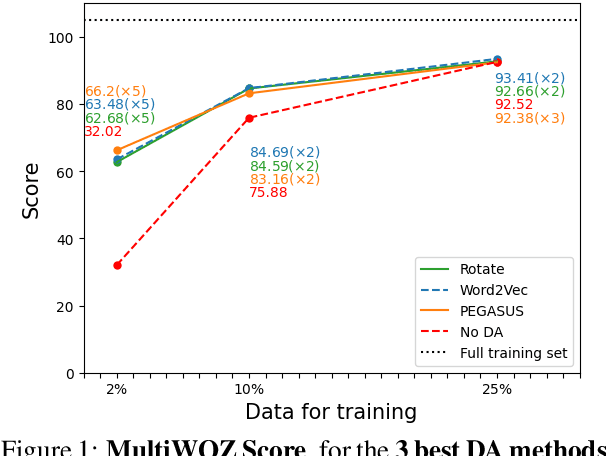
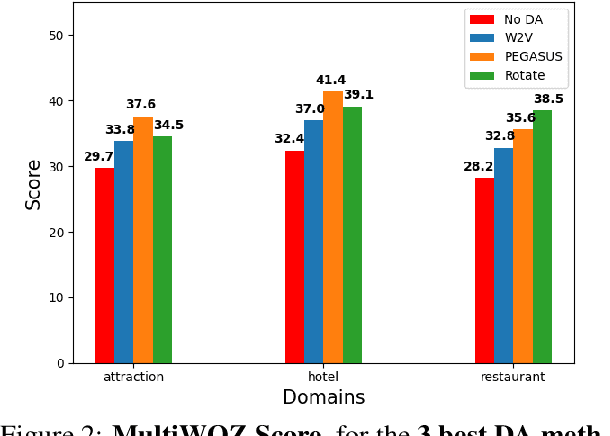

Creating effective and reliable task-oriented dialog systems (ToDSs) is challenging, not only because of the complex structure of these systems, but also due to the scarcity of training data, especially when several modules need to be trained separately, each one with its own input/output training examples. Data augmentation (DA), whereby synthetic training examples are added to the training data, has been successful in other NLP systems, but has not been explored as extensively in ToDSs. We empirically evaluate the effectiveness of DA methods in an end-to-end ToDS setting, where a single system is trained to handle all processing stages, from user inputs to system outputs. We experiment with two ToDSs (UBAR, GALAXY) on two datasets (MultiWOZ, KVRET). We consider three types of DA methods (word-level, sentence-level, dialog-level), comparing eight DA methods that have shown promising results in ToDSs and other NLP systems. We show that all DA methods considered are beneficial, and we highlight the best ones, also providing advice to practitioners. We also introduce a more challenging few-shot cross-domain ToDS setting, reaching similar conclusions.
Archimedes-AUEB at SemEval-2024 Task 5: LLM explains Civil Procedure
May 14, 2024

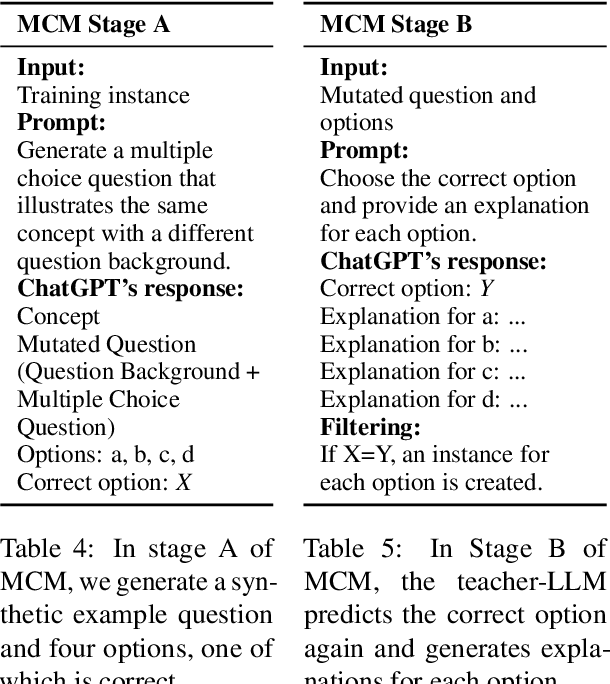
The SemEval task on Argument Reasoning in Civil Procedure is challenging in that it requires understanding legal concepts and inferring complex arguments. Currently, most Large Language Models (LLM) excelling in the legal realm are principally purposed for classification tasks, hence their reasoning rationale is subject to contention. The approach we advocate involves using a powerful teacher-LLM (ChatGPT) to extend the training dataset with explanations and generate synthetic data. The resulting data are then leveraged to fine-tune a small student-LLM. Contrary to previous work, our explanations are not directly derived from the teacher's internal knowledge. Instead they are grounded in authentic human analyses, therefore delivering a superior reasoning signal. Additionally, a new `mutation' method generates artificial data instances inspired from existing ones. We are publicly releasing the explanations as an extension to the original dataset, along with the synthetic dataset and the prompts that were used to generate both. Our system ranked 15th in the SemEval competition. It outperforms its own teacher and can produce explanations aligned with the original human analyses, as verified by legal experts.
Should I try multiple optimizers when fine-tuning pre-trained Transformers for NLP tasks? Should I tune their hyperparameters?
Feb 10, 2024



NLP research has explored different neural model architectures and sizes, datasets, training objectives, and transfer learning techniques. However, the choice of optimizer during training has not been explored as extensively. Typically, some variant of Stochastic Gradient Descent (SGD) is employed, selected among numerous variants, using unclear criteria, often with minimal or no tuning of the optimizer's hyperparameters. Experimenting with five GLUE datasets, two models (DistilBERT and DistilRoBERTa), and seven popular optimizers (SGD, SGD with Momentum, Adam, AdaMax, Nadam, AdamW, and AdaBound), we find that when the hyperparameters of the optimizers are tuned, there is no substantial difference in test performance across the five more elaborate (adaptive) optimizers, despite differences in training loss. Furthermore, tuning just the learning rate is in most cases as good as tuning all the hyperparameters. Hence, we recommend picking any of the best-behaved adaptive optimizers (e.g., Adam) and tuning only its learning rate. When no hyperparameter can be tuned, SGD with Momentum is the best choice.
Cache me if you Can: an Online Cost-aware Teacher-Student framework to Reduce the Calls to Large Language Models
Oct 20, 2023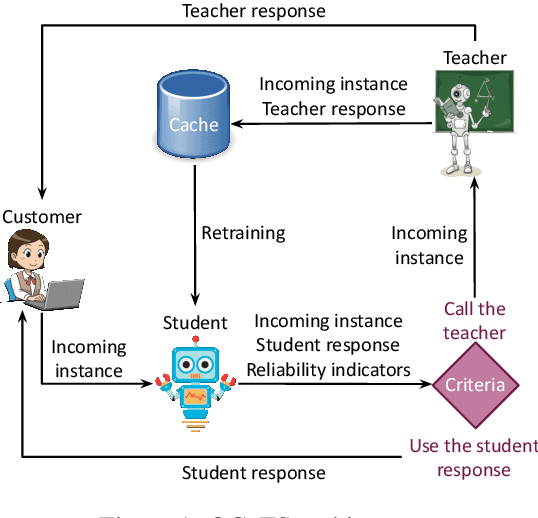
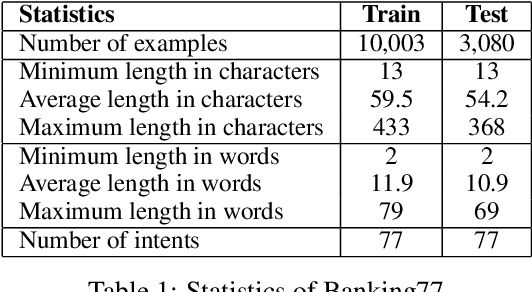
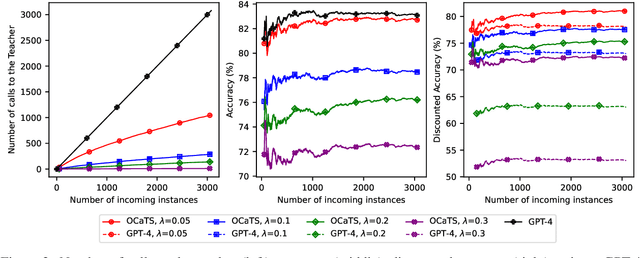
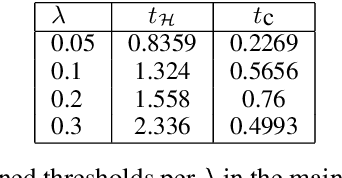
Prompting Large Language Models (LLMs) performs impressively in zero- and few-shot settings. Hence, small and medium-sized enterprises (SMEs) that cannot afford the cost of creating large task-specific training datasets, but also the cost of pretraining their own LLMs, are increasingly turning to third-party services that allow them to prompt LLMs. However, such services currently require a payment per call, which becomes a significant operating expense (OpEx). Furthermore, customer inputs are often very similar over time, hence SMEs end-up prompting LLMs with very similar instances. We propose a framework that allows reducing the calls to LLMs by caching previous LLM responses and using them to train a local inexpensive model on the SME side. The framework includes criteria for deciding when to trust the local model or call the LLM, and a methodology to tune the criteria and measure the tradeoff between performance and cost. For experimental purposes, we instantiate our framework with two LLMs, GPT-3.5 or GPT-4, and two inexpensive students, a k-NN classifier or a Multi-Layer Perceptron, using two common business tasks, intent recognition and sentiment analysis. Experimental results indicate that significant OpEx savings can be obtained with only slightly lower performance.