 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould I try multiple optimizers when fine-tuning pre-trained Transformers for NLP tasks? Should I tune their hyperparameters?
Feb 10, 2024



NLP research has explored different neural model architectures and sizes, datasets, training objectives, and transfer learning techniques. However, the choice of optimizer during training has not been explored as extensively. Typically, some variant of Stochastic Gradient Descent (SGD) is employed, selected among numerous variants, using unclear criteria, often with minimal or no tuning of the optimizer's hyperparameters. Experimenting with five GLUE datasets, two models (DistilBERT and DistilRoBERTa), and seven popular optimizers (SGD, SGD with Momentum, Adam, AdaMax, Nadam, AdamW, and AdaBound), we find that when the hyperparameters of the optimizers are tuned, there is no substantial difference in test performance across the five more elaborate (adaptive) optimizers, despite differences in training loss. Furthermore, tuning just the learning rate is in most cases as good as tuning all the hyperparameters. Hence, we recommend picking any of the best-behaved adaptive optimizers (e.g., Adam) and tuning only its learning rate. When no hyperparameter can be tuned, SGD with Momentum is the best choice.
Making LLMs Worth Every Penny: Resource-Limited Text Classification in Banking
Nov 10, 2023
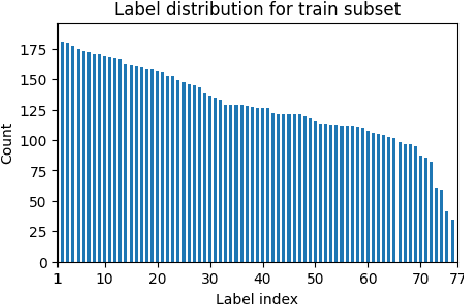
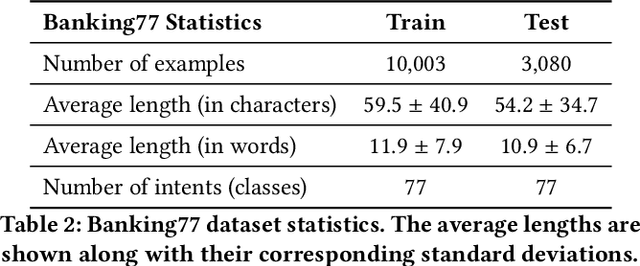

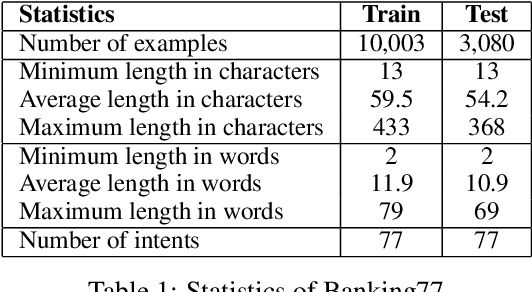
Standard Full-Data classifiers in NLP demand thousands of labeled examples, which is impractical in data-limited domains. Few-shot methods offer an alternative, utilizing contrastive learning techniques that can be effective with as little as 20 examples per class. Similarly, Large Language Models (LLMs) like GPT-4 can perform effectively with just 1-5 examples per class. However, the performance-cost trade-offs of these methods remain underexplored, a critical concern for budget-limited organizations. Our work addresses this gap by studying the aforementioned approaches over the Banking77 financial intent detection dataset, including the evaluation of cutting-edge LLMs by OpenAI, Cohere, and Anthropic in a comprehensive set of few-shot scenarios. We complete the picture with two additional methods: first, a cost-effective querying method for LLMs based on retrieval-augmented generation (RAG), able to reduce operational costs multiple times compared to classic few-shot approaches, and second, a data augmentation method using GPT-4, able to improve performance in data-limited scenarios. Finally, to inspire future research, we provide a human expert's curated subset of Banking77, along with extensive error analysis.
Cache me if you Can: an Online Cost-aware Teacher-Student framework to Reduce the Calls to Large Language Models
Oct 20, 2023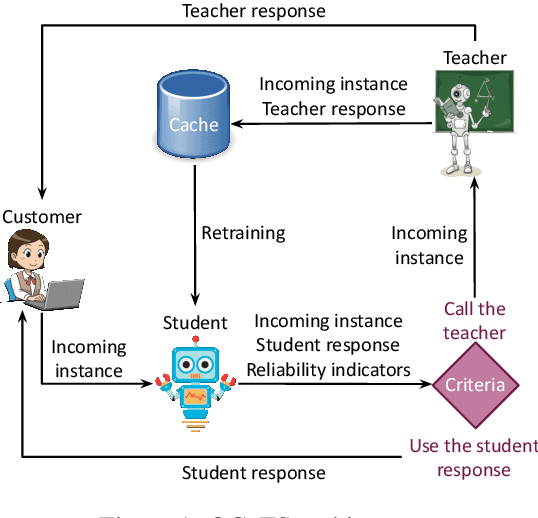
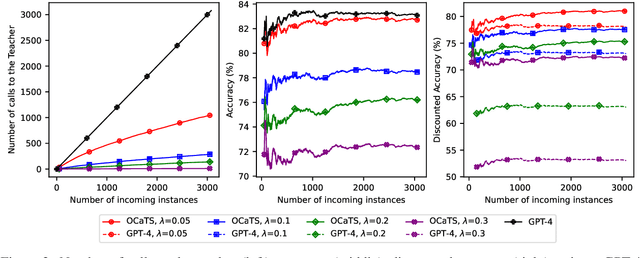
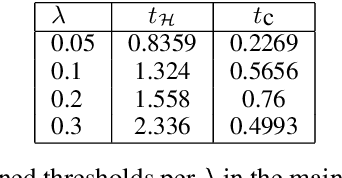
Prompting Large Language Models (LLMs) performs impressively in zero- and few-shot settings. Hence, small and medium-sized enterprises (SMEs) that cannot afford the cost of creating large task-specific training datasets, but also the cost of pretraining their own LLMs, are increasingly turning to third-party services that allow them to prompt LLMs. However, such services currently require a payment per call, which becomes a significant operating expense (OpEx). Furthermore, customer inputs are often very similar over time, hence SMEs end-up prompting LLMs with very similar instances. We propose a framework that allows reducing the calls to LLMs by caching previous LLM responses and using them to train a local inexpensive model on the SME side. The framework includes criteria for deciding when to trust the local model or call the LLM, and a methodology to tune the criteria and measure the tradeoff between performance and cost. For experimental purposes, we instantiate our framework with two LLMs, GPT-3.5 or GPT-4, and two inexpensive students, a k-NN classifier or a Multi-Layer Perceptron, using two common business tasks, intent recognition and sentiment analysis. Experimental results indicate that significant OpEx savings can be obtained with only slightly lower performance.
Breaking the Bank with ChatGPT: Few-Shot Text Classification for Finance
Aug 28, 2023
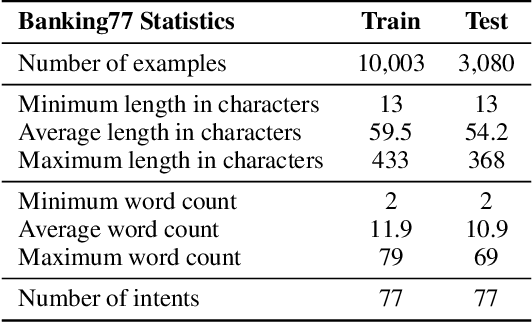

We propose the use of conversational GPT models for easy and quick few-shot text classification in the financial domain using the Banking77 dataset. Our approach involves in-context learning with GPT-3.5 and GPT-4, which minimizes the technical expertise required and eliminates the need for expensive GPU computing while yielding quick and accurate results. Additionally, we fine-tune other pre-trained, masked language models with SetFit, a recent contrastive learning technique, to achieve state-of-the-art results both in full-data and few-shot settings. Our findings show that querying GPT-3.5 and GPT-4 can outperform fine-tuned, non-generative models even with fewer examples. However, subscription fees associated with these solutions may be considered costly for small organizations. Lastly, we find that generative models perform better on the given task when shown representative samples selected by a human expert rather than when shown random ones. We conclude that a) our proposed methods offer a practical solution for few-shot tasks in datasets with limited label availability, and b) our state-of-the-art results can inspire future work in the area.
Legal-Tech Open Diaries: Lesson learned on how to develop and deploy light-weight models in the era of humongous Language Models
Oct 24, 2022



In the era of billion-parameter-sized Language Models (LMs), start-ups have to follow trends and adapt their technology accordingly. Nonetheless, there are open challenges since the development and deployment of large models comes with a need for high computational resources and has economical consequences. In this work, we follow the steps of the R&D group of a modern legal-tech start-up and present important insights on model development and deployment. We start from ground zero by pre-training multiple domain-specific multi-lingual LMs which are a better fit to contractual and regulatory text compared to the available alternatives (XLM-R). We present benchmark results of such models in a half-public half-private legal benchmark comprising 5 downstream tasks showing the impact of larger model size. Lastly, we examine the impact of a full-scale pipeline for model compression which includes: a) Parameter Pruning, b) Knowledge Distillation, and c) Quantization: The resulting models are much more efficient without sacrificing performance at large.
An Exploration of Hierarchical Attention Transformers for Efficient Long Document Classification
Oct 11, 2022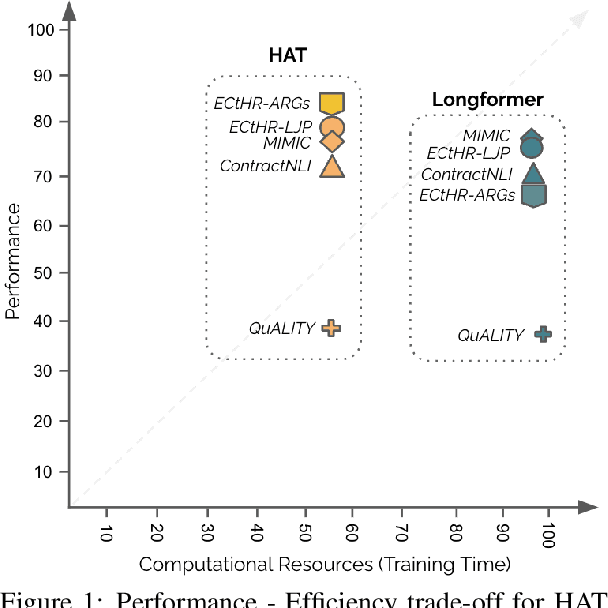

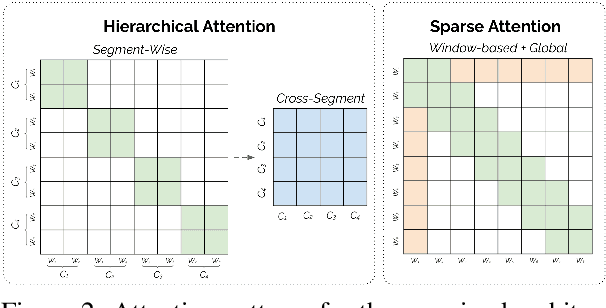
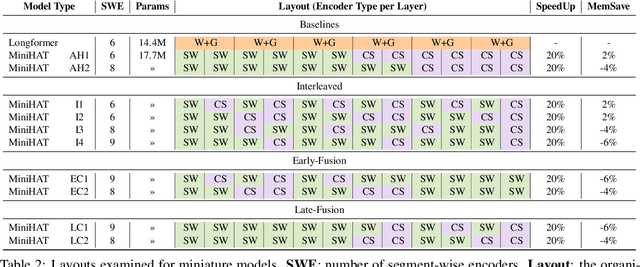
Non-hierarchical sparse attention Transformer-based models, such as Longformer and Big Bird, are popular approaches to working with long documents. There are clear benefits to these approaches compared to the original Transformer in terms of efficiency, but Hierarchical Attention Transformer (HAT) models are a vastly understudied alternative. We develop and release fully pre-trained HAT models that use segment-wise followed by cross-segment encoders and compare them with Longformer models and partially pre-trained HATs. In several long document downstream classification tasks, our best HAT model outperforms equally-sized Longformer models while using 10-20% less GPU memory and processing documents 40-45% faster. In a series of ablation studies, we find that HATs perform best with cross-segment contextualization throughout the model than alternative configurations that implement either early or late cross-segment contextualization. Our code is on GitHub: https://github.com/coastalcph/hierarchical-transformers.
Data Augmentation for Biomedical Factoid Question Answering
Apr 10, 2022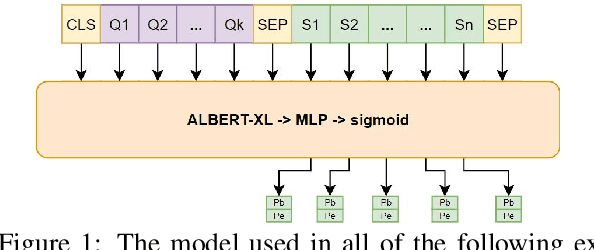

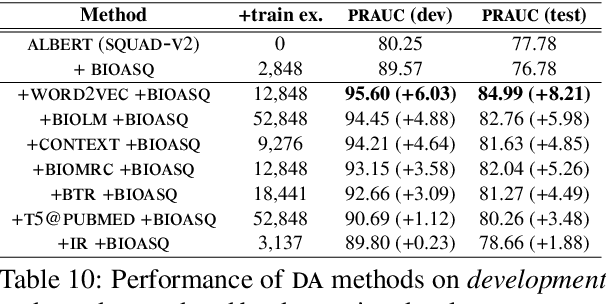

We study the effect of seven data augmentation (da) methods in factoid question answering, focusing on the biomedical domain, where obtaining training instances is particularly difficult. We experiment with data from the BioASQ challenge, which we augment with training instances obtained from an artificial biomedical machine reading comprehension dataset, or via back-translation, information retrieval, word substitution based on word2vec embeddings, or masked language modeling, question generation, or extending the given passage with additional context. We show that da can lead to very significant performance gains, even when using large pre-trained Transformers, contributing to a broader discussion of if/when da benefits large pre-trained models. One of the simplest da methods, word2vec-based word substitution, performed best and is recommended. We release our artificial training instances and code.
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
Mar 12, 2022
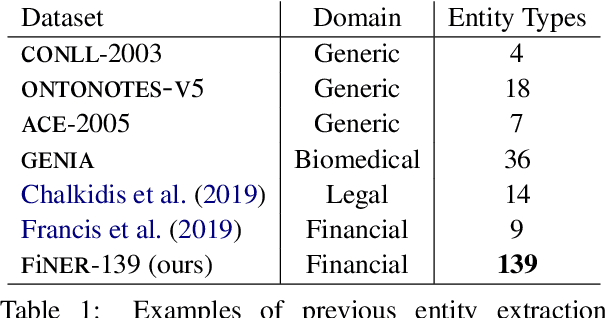
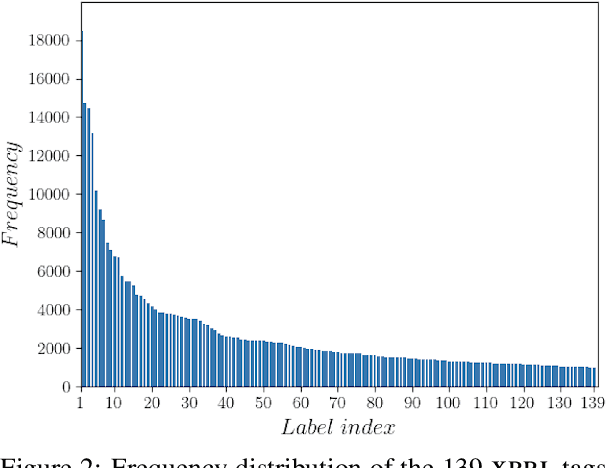
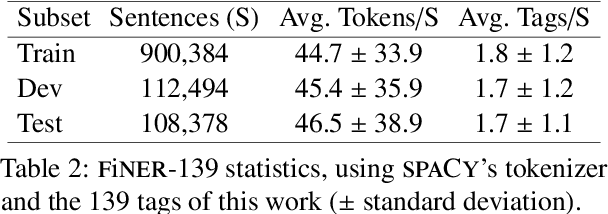
Publicly traded companies are required to submit periodic reports with eXtensive Business Reporting Language (XBRL) word-level tags. Manually tagging the reports is tedious and costly. We, therefore, introduce XBRL tagging as a new entity extraction task for the financial domain and release FiNER-139, a dataset of 1.1M sentences with gold XBRL tags. Unlike typical entity extraction datasets, FiNER-139 uses a much larger label set of 139 entity types. Most annotated tokens are numeric, with the correct tag per token depending mostly on context, rather than the token itself. We show that subword fragmentation of numeric expressions harms BERT's performance, allowing word-level BILSTMs to perform better. To improve BERT's performance, we propose two simple and effective solutions that replace numeric expressions with pseudo-tokens reflecting original token shapes and numeric magnitudes. We also experiment with FIN-BERT, an existing BERT model for the financial domain, and release our own BERT (SEC-BERT), pre-trained on financial filings, which performs best. Through data and error analysis, we finally identify possible limitations to inspire future work on XBRL tagging.
EDGAR-CORPUS: Billions of Tokens Make The World Go Round
Oct 01, 2021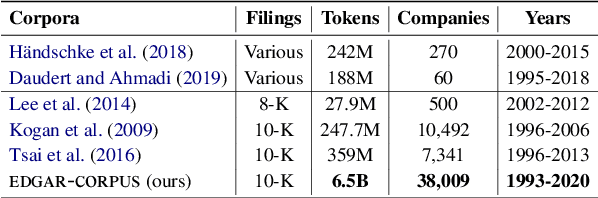



We release EDGAR-CORPUS, a novel corpus comprising annual reports from all the publicly traded companies in the US spanning a period of more than 25 years. To the best of our knowledge, EDGAR-CORPUS is the largest financial NLP corpus available to date. All the reports are downloaded, split into their corresponding items (sections), and provided in a clean, easy-to-use JSON format. We use EDGAR-CORPUS to train and release EDGAR-W2V, which are WORD2VEC embeddings for the financial domain. We employ these embeddings in a battery of financial NLP tasks and showcase their superiority over generic GloVe embeddings and other existing financial word embeddings. We also open-source EDGAR-CRAWLER, a toolkit that facilitates downloading and extracting future annual reports.
Paragraph-level Rationale Extraction through Regularization: A case study on European Court of Human Rights Cases
Mar 24, 2021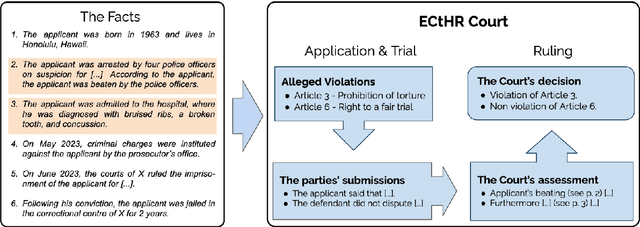
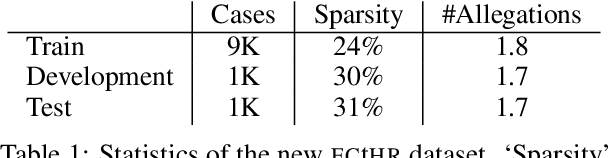
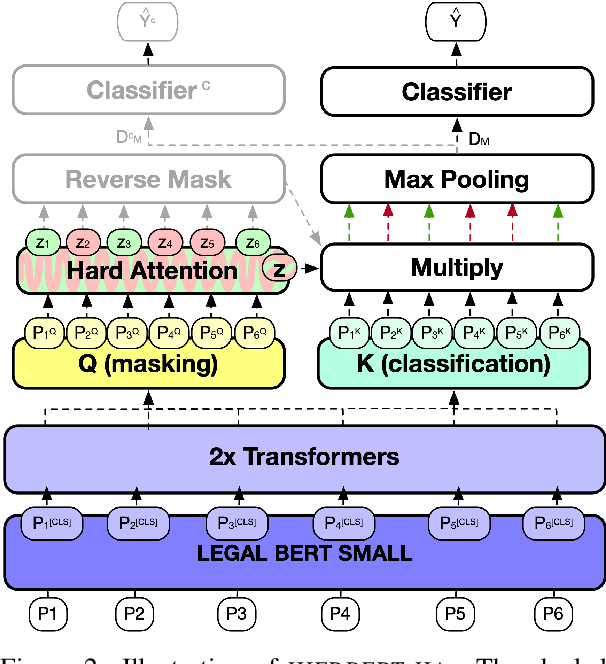
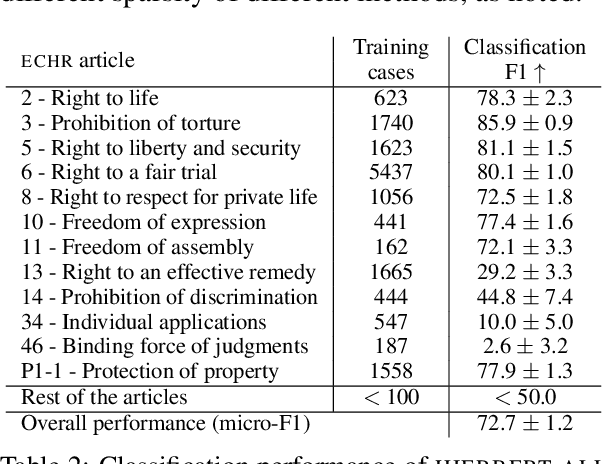
Interpretability or explainability is an emerging research field in NLP. From a user-centric point of view, the goal is to build models that provide proper justification for their decisions, similar to those of humans, by requiring the models to satisfy additional constraints. To this end, we introduce a new application on legal text where, contrary to mainstream literature targeting word-level rationales, we conceive rationales as selected paragraphs in multi-paragraph structured court cases. We also release a new dataset comprising European Court of Human Rights cases, including annotations for paragraph-level rationales. We use this dataset to study the effect of already proposed rationale constraints, i.e., sparsity, continuity, and comprehensiveness, formulated as regularizers. Our findings indicate that some of these constraints are not beneficial in paragraph-level rationale extraction, while others need re-formulation to better handle the multi-label nature of the task we consider. We also introduce a new constraint, singularity, which further improves the quality of rationales, even compared with noisy rationale supervision. Experimental results indicate that the newly introduced task is very challenging and there is a large scope for further research.