 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Exploration of Hierarchical Attention Transformers for Efficient Long Document Classification
Oct 11, 2022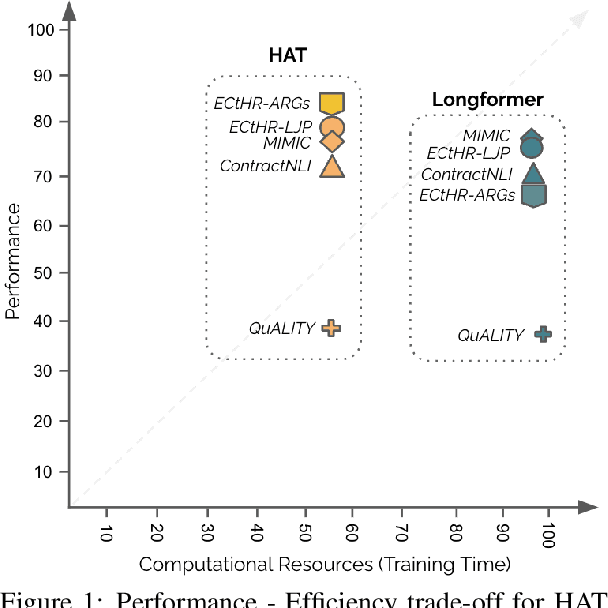

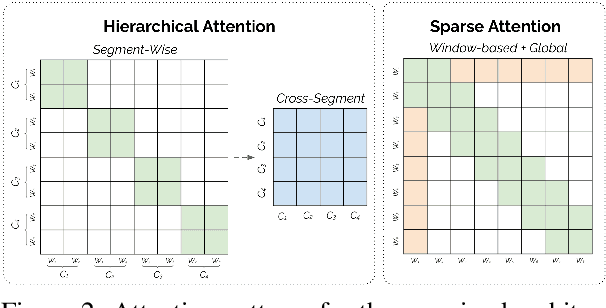
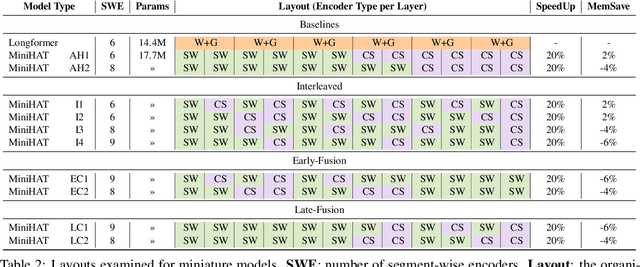
Non-hierarchical sparse attention Transformer-based models, such as Longformer and Big Bird, are popular approaches to working with long documents. There are clear benefits to these approaches compared to the original Transformer in terms of efficiency, but Hierarchical Attention Transformer (HAT) models are a vastly understudied alternative. We develop and release fully pre-trained HAT models that use segment-wise followed by cross-segment encoders and compare them with Longformer models and partially pre-trained HATs. In several long document downstream classification tasks, our best HAT model outperforms equally-sized Longformer models while using 10-20% less GPU memory and processing documents 40-45% faster. In a series of ablation studies, we find that HATs perform best with cross-segment contextualization throughout the model than alternative configurations that implement either early or late cross-segment contextualization. Our code is on GitHub: https://github.com/coastalcph/hierarchical-transformers.
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
Mar 12, 2022
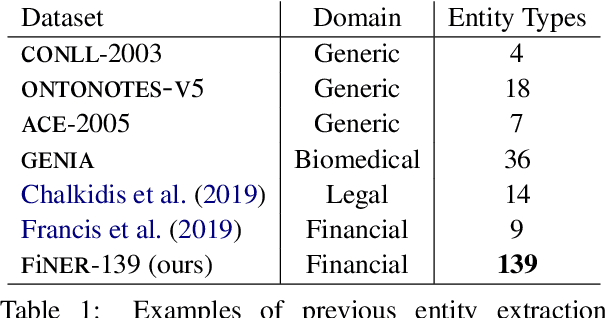
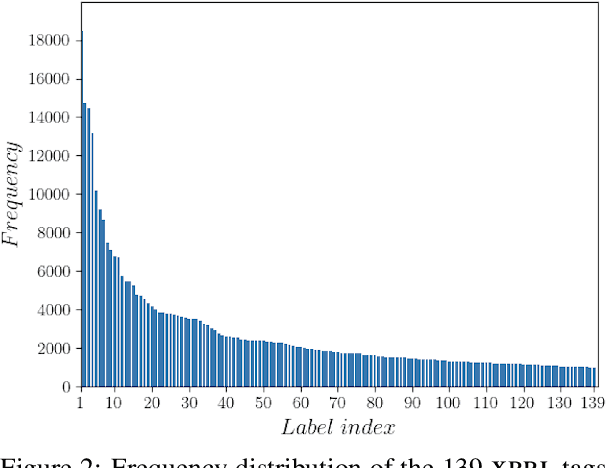
Publicly traded companies are required to submit periodic reports with eXtensive Business Reporting Language (XBRL) word-level tags. Manually tagging the reports is tedious and costly. We, therefore, introduce XBRL tagging as a new entity extraction task for the financial domain and release FiNER-139, a dataset of 1.1M sentences with gold XBRL tags. Unlike typical entity extraction datasets, FiNER-139 uses a much larger label set of 139 entity types. Most annotated tokens are numeric, with the correct tag per token depending mostly on context, rather than the token itself. We show that subword fragmentation of numeric expressions harms BERT's performance, allowing word-level BILSTMs to perform better. To improve BERT's performance, we propose two simple and effective solutions that replace numeric expressions with pseudo-tokens reflecting original token shapes and numeric magnitudes. We also experiment with FIN-BERT, an existing BERT model for the financial domain, and release our own BERT (SEC-BERT), pre-trained on financial filings, which performs best. Through data and error analysis, we finally identify possible limitations to inspire future work on XBRL tagging.
EDGAR-CORPUS: Billions of Tokens Make The World Go Round
Oct 01, 2021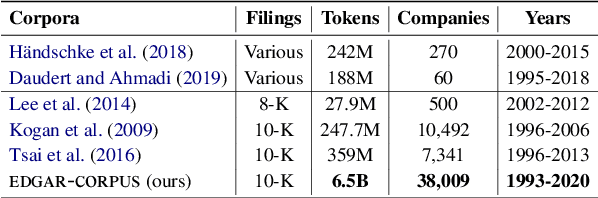



We release EDGAR-CORPUS, a novel corpus comprising annual reports from all the publicly traded companies in the US spanning a period of more than 25 years. To the best of our knowledge, EDGAR-CORPUS is the largest financial NLP corpus available to date. All the reports are downloaded, split into their corresponding items (sections), and provided in a clean, easy-to-use JSON format. We use EDGAR-CORPUS to train and release EDGAR-W2V, which are WORD2VEC embeddings for the financial domain. We employ these embeddings in a battery of financial NLP tasks and showcase their superiority over generic GloVe embeddings and other existing financial word embeddings. We also open-source EDGAR-CRAWLER, a toolkit that facilitates downloading and extracting future annual reports.
DICoE@FinSim-3: Financial Hypernym Detection using Augmented Terms and Distance-based Features
Sep 30, 2021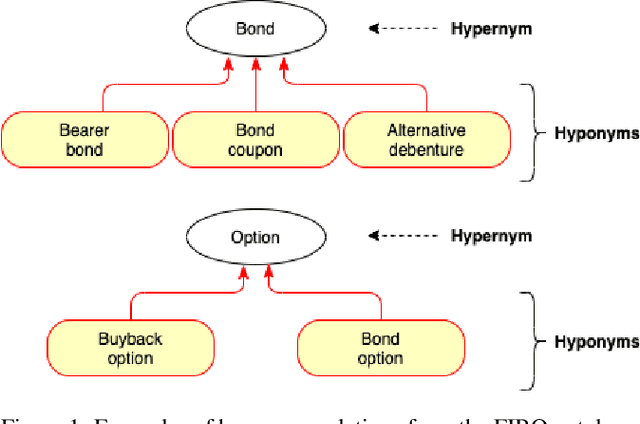
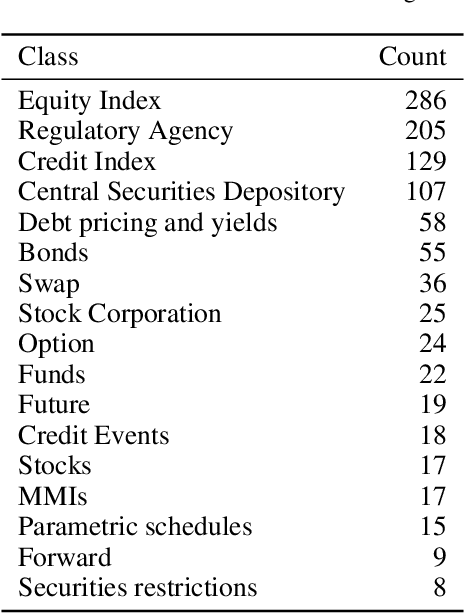
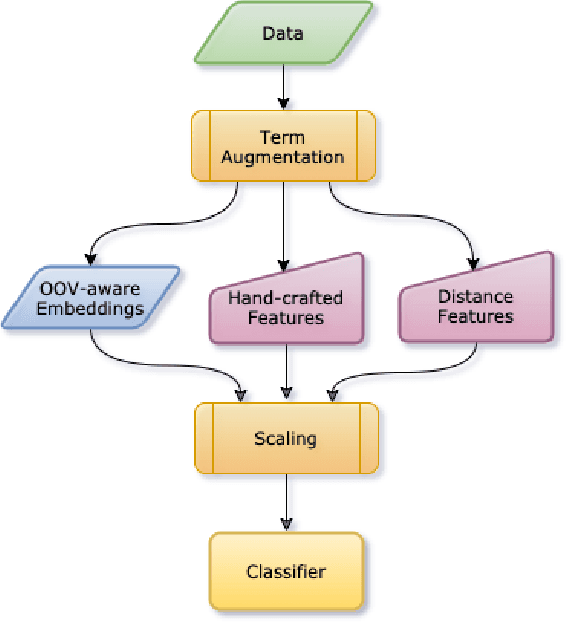
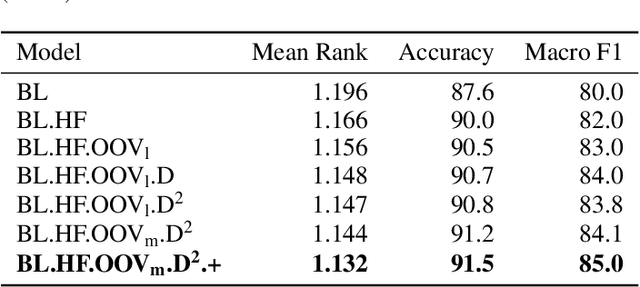
We present the submission of team DICoE for FinSim-3, the 3rd Shared Task on Learning Semantic Similarities for the Financial Domain. The task provides a set of terms in the financial domain and requires to classify them into the most relevant hypernym from a financial ontology. After augmenting the terms with their Investopedia definitions, our system employs a Logistic Regression classifier over financial word embeddings and a mix of hand-crafted and distance-based features. Also, for the first time in this task, we employ different replacement methods for out-of-vocabulary terms, leading to improved performance. Finally, we have also experimented with word representations generated from various financial corpora. Our best-performing submission ranked 4th on the task's leaderboard.
MultiEURLEX -- A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer
Sep 06, 2021

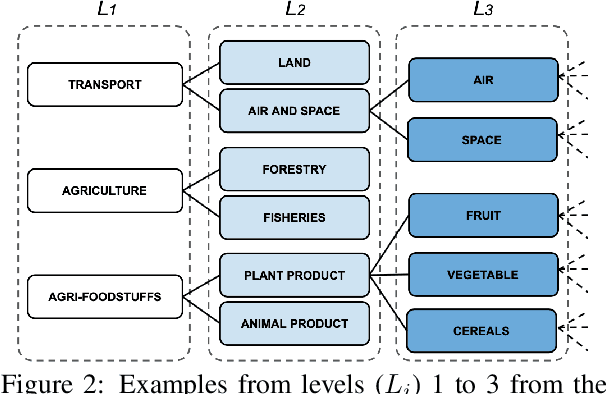
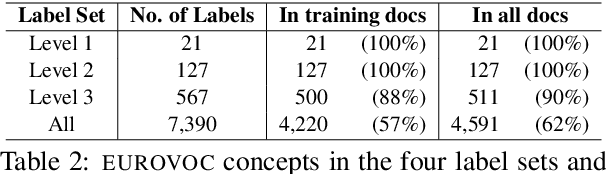
We introduce MULTI-EURLEX, a new multilingual dataset for topic classification of legal documents. The dataset comprises 65k European Union (EU) laws, officially translated in 23 languages, annotated with multiple labels from the EUROVOC taxonomy. We highlight the effect of temporal concept drift and the importance of chronological, instead of random splits. We use the dataset as a testbed for zero-shot cross-lingual transfer, where we exploit annotated training documents in one language (source) to classify documents in another language (target). We find that fine-tuning a multilingually pretrained model (XLM-ROBERTA, MT5) in a single source language leads to catastrophic forgetting of multilingual knowledge and, consequently, poor zero-shot transfer to other languages. Adaptation strategies, namely partial fine-tuning, adapters, BITFIT, LNFIT, originally proposed to accelerate fine-tuning for new end-tasks, help retain multilingual knowledge from pretraining, substantially improving zero-shot cross-lingual transfer, but their impact also depends on the pretrained model used and the size of the label set.
Paragraph-level Rationale Extraction through Regularization: A case study on European Court of Human Rights Cases
Mar 24, 2021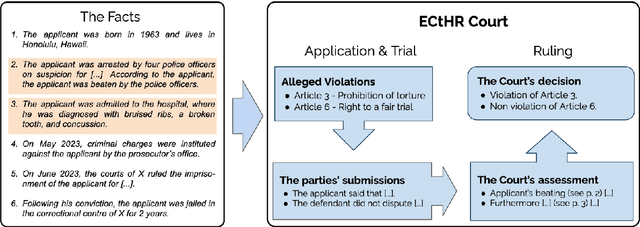
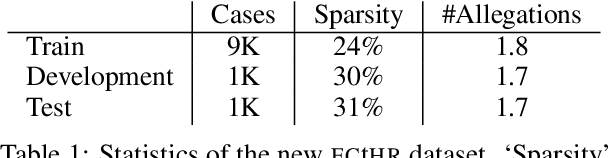
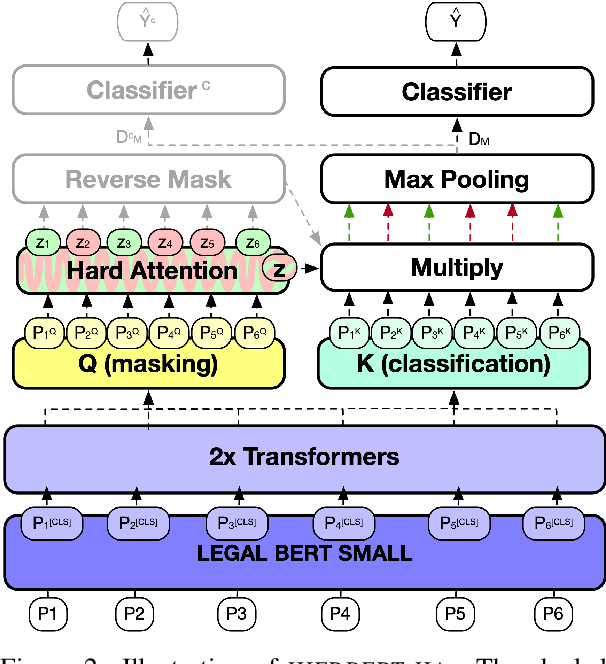
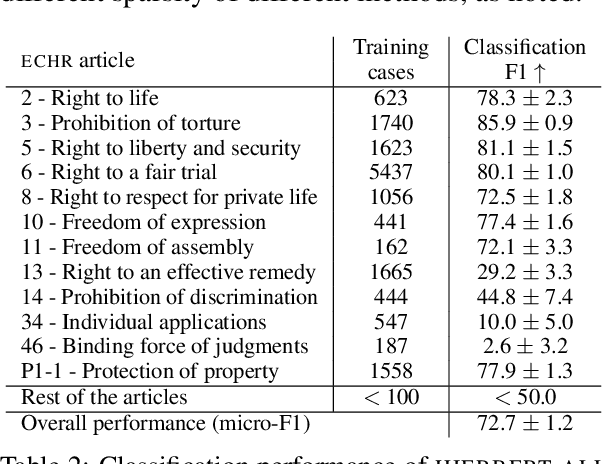
Interpretability or explainability is an emerging research field in NLP. From a user-centric point of view, the goal is to build models that provide proper justification for their decisions, similar to those of humans, by requiring the models to satisfy additional constraints. To this end, we introduce a new application on legal text where, contrary to mainstream literature targeting word-level rationales, we conceive rationales as selected paragraphs in multi-paragraph structured court cases. We also release a new dataset comprising European Court of Human Rights cases, including annotations for paragraph-level rationales. We use this dataset to study the effect of already proposed rationale constraints, i.e., sparsity, continuity, and comprehensiveness, formulated as regularizers. Our findings indicate that some of these constraints are not beneficial in paragraph-level rationale extraction, while others need re-formulation to better handle the multi-label nature of the task we consider. We also introduce a new constraint, singularity, which further improves the quality of rationales, even compared with noisy rationale supervision. Experimental results indicate that the newly introduced task is very challenging and there is a large scope for further research.
Regulatory Compliance through Doc2Doc Information Retrieval: A case study in EU/UK legislation where text similarity has limitations
Jan 26, 2021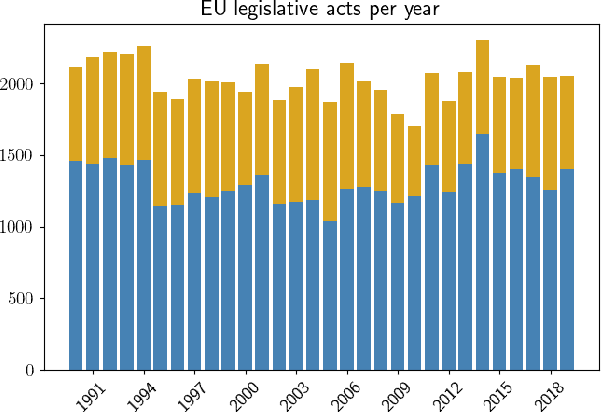
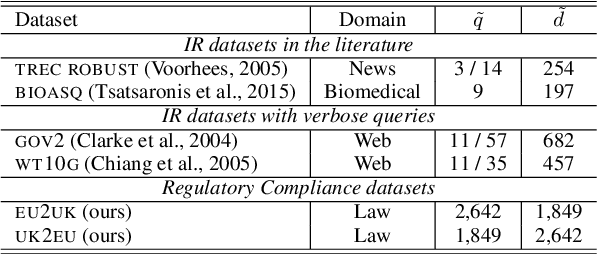
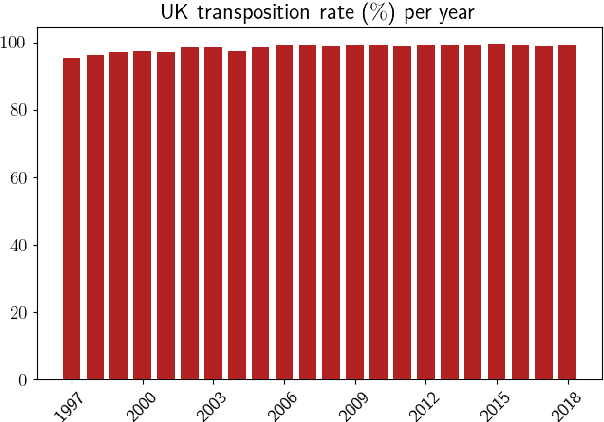

Major scandals in corporate history have urged the need for regulatory compliance, where organizations need to ensure that their controls (processes) comply with relevant laws, regulations, and policies. However, keeping track of the constantly changing legislation is difficult, thus organizations are increasingly adopting Regulatory Technology (RegTech) to facilitate the process. To this end, we introduce regulatory information retrieval (REG-IR), an application of document-to-document information retrieval (DOC2DOC IR), where the query is an entire document making the task more challenging than traditional IR where the queries are short. Furthermore, we compile and release two datasets based on the relationships between EU directives and UK legislation. We experiment on these datasets using a typical two-step pipeline approach comprising a pre-fetcher and a neural re-ranker. Experimenting with various pre-fetchers from BM25 to k nearest neighbors over representations from several BERT models, we show that fine-tuning a BERT model on an in-domain classification task produces the best representations for IR. We also show that neural re-rankers under-perform due to contradicting supervision, i.e., similar query-document pairs with opposite labels. Thus, they are biased towards the pre-fetcher's score. Interestingly, applying a date filter further improves the performance, showcasing the importance of the time dimension.
Neural Contract Element Extraction Revisited
Jan 12, 2021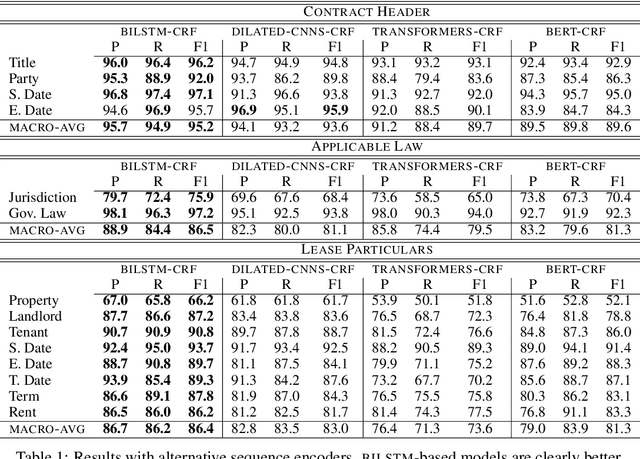

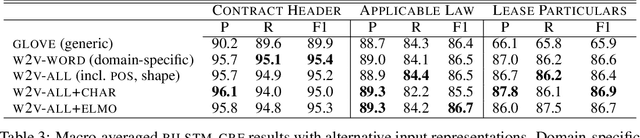
We investigate contract element extraction. We show that LSTM-based encoders perform better than dilated CNNs, Transformers, and BERT in this task. We also find that domain-specific WORD2VEC embeddings outperform generic pre-trained GLOVE embeddings. Morpho-syntactic features in the form of POS tag and token shape embeddings, as well as context-aware ELMO embeddings, do not improve performance. Several of these observations contradict choices or findings of previous work on contract element extraction and generic sequence labeling tasks, indicating that contract element extraction requires careful task-specific choices.
* 4 pages
LEGAL-BERT: The Muppets straight out of Law School
Oct 06, 2020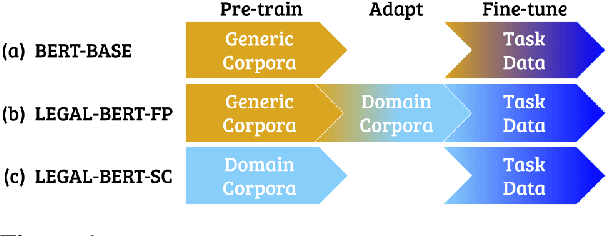

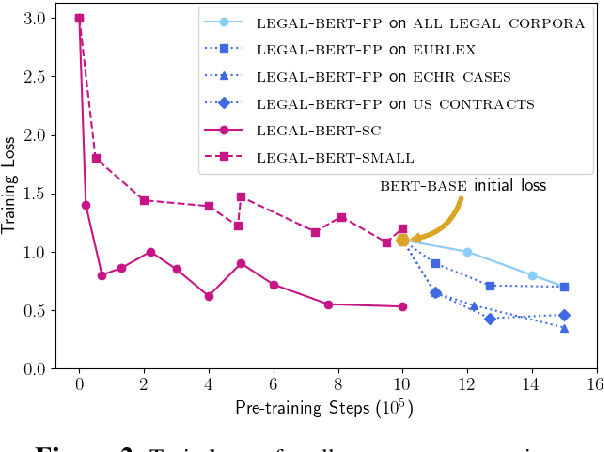
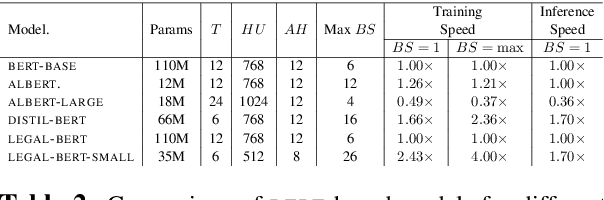
BERT has achieved impressive performance in several NLP tasks. However, there has been limited investigation on its adaptation guidelines in specialised domains. Here we focus on the legal domain, where we explore several approaches for applying BERT models to downstream legal tasks, evaluating on multiple datasets. Our findings indicate that the previous guidelines for pre-training and fine-tuning, often blindly followed, do not always generalize well in the legal domain. Thus we propose a systematic investigation of the available strategies when applying BERT in specialised domains. These are: (a) use the original BERT out of the box, (b) adapt BERT by additional pre-training on domain-specific corpora, and (c) pre-train BERT from scratch on domain-specific corpora. We also propose a broader hyper-parameter search space when fine-tuning for downstream tasks and we release LEGAL-BERT, a family of BERT models intended to assist legal NLP research, computational law, and legal technology applications.
An Empirical Study on Large-Scale Multi-Label Text Classification Including Few and Zero-Shot Labels
Oct 04, 2020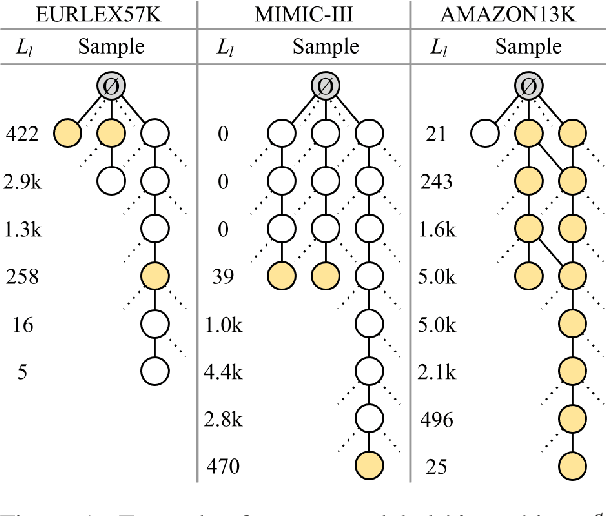
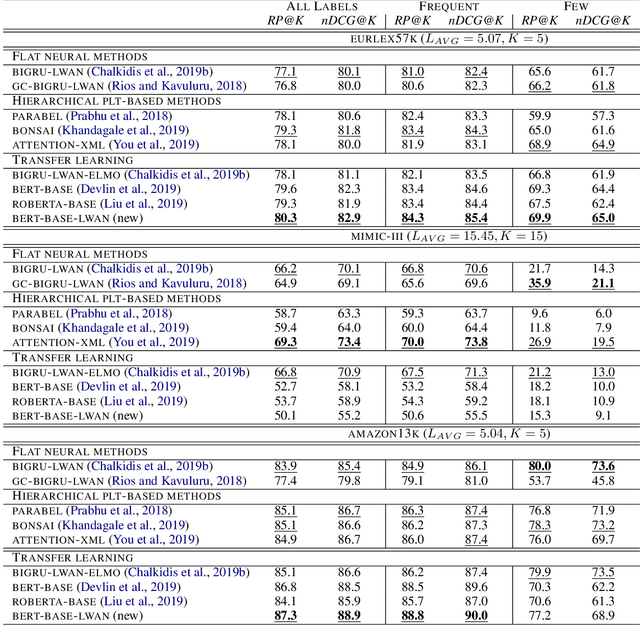
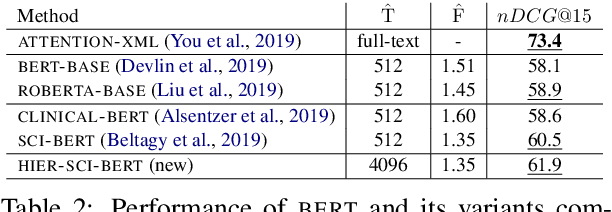
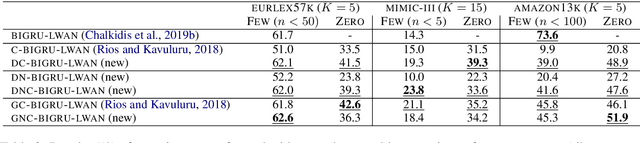
Large-scale Multi-label Text Classification (LMTC) has a wide range of Natural Language Processing (NLP) applications and presents interesting challenges. First, not all labels are well represented in the training set, due to the very large label set and the skewed label distributions of LMTC datasets. Also, label hierarchies and differences in human labelling guidelines may affect graph-aware annotation proximity. Finally, the label hierarchies are periodically updated, requiring LMTC models capable of zero-shot generalization. Current state-of-the-art LMTC models employ Label-Wise Attention Networks (LWANs), which (1) typically treat LMTC as flat multi-label classification; (2) may use the label hierarchy to improve zero-shot learning, although this practice is vastly understudied; and (3) have not been combined with pre-trained Transformers (e.g. BERT), which have led to state-of-the-art results in several NLP benchmarks. Here, for the first time, we empirically evaluate a battery of LMTC methods from vanilla LWANs to hierarchical classification approaches and transfer learning, on frequent, few, and zero-shot learning on three datasets from different domains. We show that hierarchical methods based on Probabilistic Label Trees (PLTs) outperform LWANs. Furthermore, we show that Transformer-based approaches outperform the state-of-the-art in two of the datasets, and we propose a new state-of-the-art method which combines BERT with LWANs. Finally, we propose new models that leverage the label hierarchy to improve few and zero-shot learning, considering on each dataset a graph-aware annotation proximity measure that we introduce.