 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciNoBo : A Hierarchical Multi-Label Classifier of Scientific Publications
Apr 02, 2022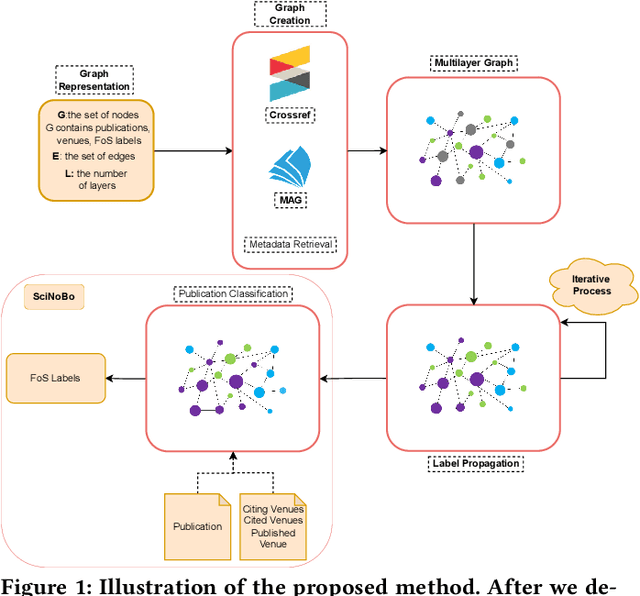
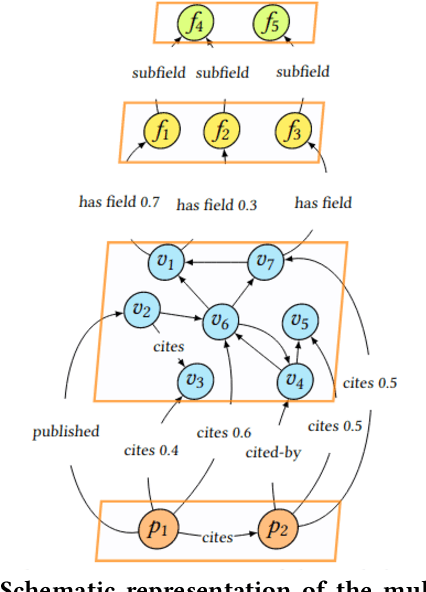

Classifying scientific publications according to Field-of-Science (FoS) taxonomies is of crucial importance, allowing funders, publishers, scholars, companies and other stakeholders to organize scientific literature more effectively. Most existing works address classification either at venue level or solely based on the textual content of a research publication. We present SciNoBo, a novel classification system of publications to predefined FoS taxonomies, leveraging the structural properties of a publication and its citations and references organised in a multilayer network. In contrast to other works, our system supports assignments of publications to multiple fields by considering their multidisciplinarity potential. By unifying publications and venues under a common multilayer network structure made up of citing and publishing relationships, classifications at the venue-level can be augmented with publication-level classifications. We evaluate SciNoBo on a publications' dataset extracted from Microsoft Academic Graph and we perform a comparative analysis against a state-of-the-art neural-network baseline. The results reveal that our proposed system is capable of producing high-quality classifications of publications.
An Empirical Study on Large-Scale Multi-Label Text Classification Including Few and Zero-Shot Labels
Oct 04, 2020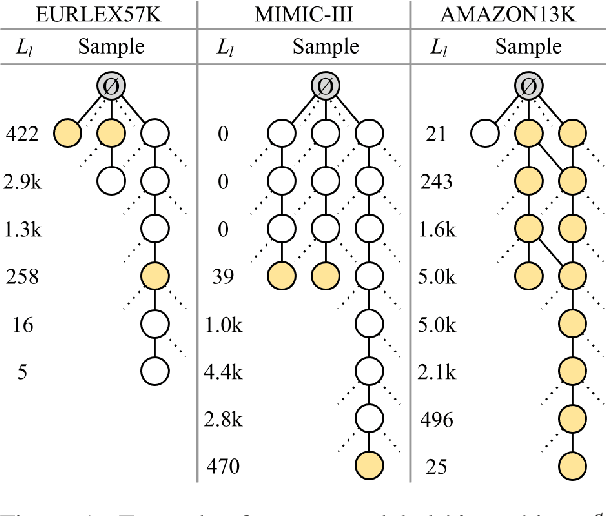
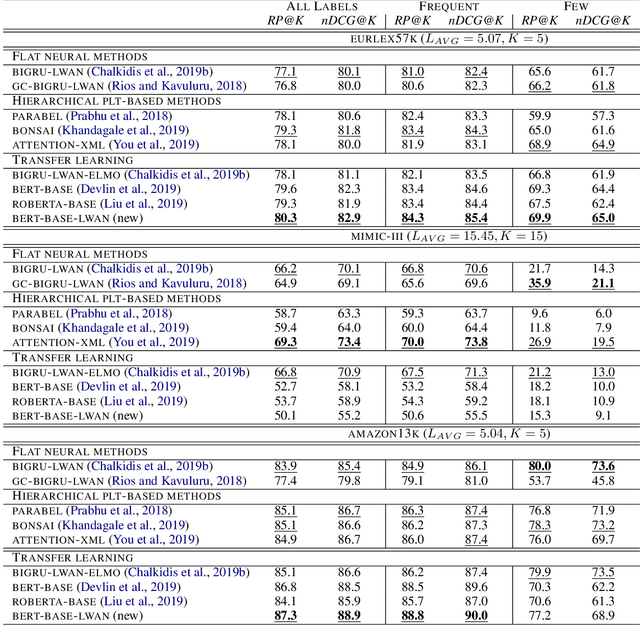
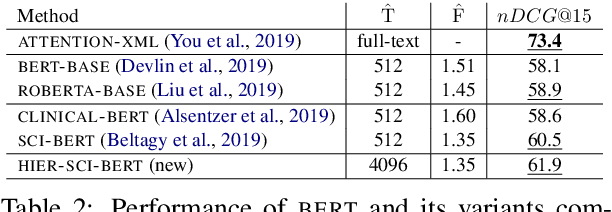
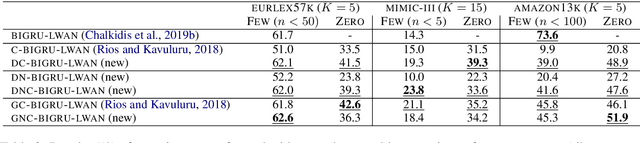
Large-scale Multi-label Text Classification (LMTC) has a wide range of Natural Language Processing (NLP) applications and presents interesting challenges. First, not all labels are well represented in the training set, due to the very large label set and the skewed label distributions of LMTC datasets. Also, label hierarchies and differences in human labelling guidelines may affect graph-aware annotation proximity. Finally, the label hierarchies are periodically updated, requiring LMTC models capable of zero-shot generalization. Current state-of-the-art LMTC models employ Label-Wise Attention Networks (LWANs), which (1) typically treat LMTC as flat multi-label classification; (2) may use the label hierarchy to improve zero-shot learning, although this practice is vastly understudied; and (3) have not been combined with pre-trained Transformers (e.g. BERT), which have led to state-of-the-art results in several NLP benchmarks. Here, for the first time, we empirically evaluate a battery of LMTC methods from vanilla LWANs to hierarchical classification approaches and transfer learning, on frequent, few, and zero-shot learning on three datasets from different domains. We show that hierarchical methods based on Probabilistic Label Trees (PLTs) outperform LWANs. Furthermore, we show that Transformer-based approaches outperform the state-of-the-art in two of the datasets, and we propose a new state-of-the-art method which combines BERT with LWANs. Finally, we propose new models that leverage the label hierarchy to improve few and zero-shot learning, considering on each dataset a graph-aware annotation proximity measure that we introduce.
Embedding Biomedical Ontologies by Jointly Encoding Network Structure and Textual Node Descriptors
Jun 20, 2019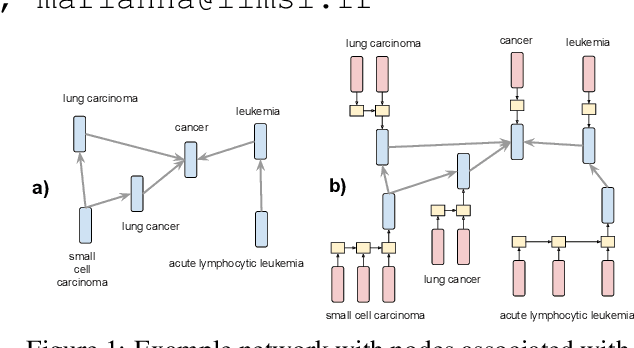
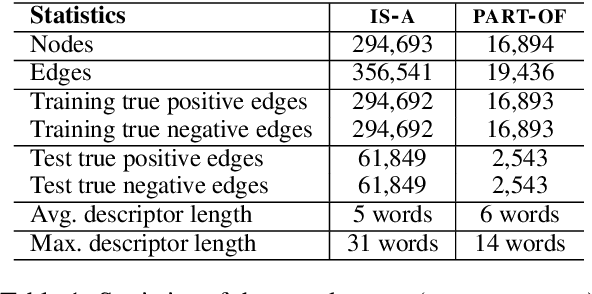
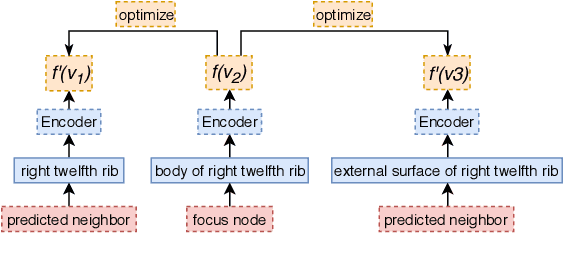
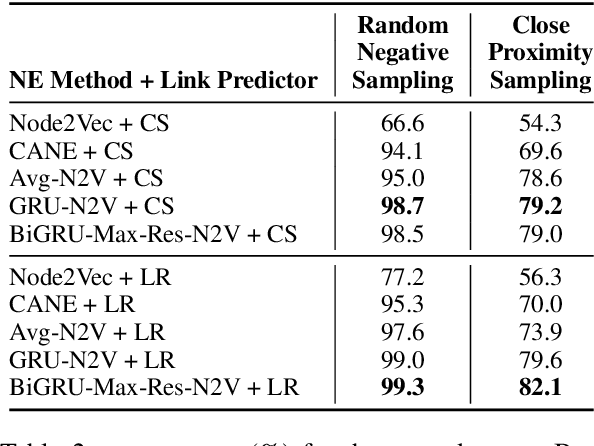
Network Embedding (NE) methods, which map network nodes to low-dimensional feature vectors, have wide applications in network analysis and bioinformatics. Many existing NE methods rely only on network structure, overlooking other information associated with the nodes, e.g., text describing the nodes. Recent attempts to combine the two sources of information only consider local network structure. We extend NODE2VEC, a well-known NE method that considers broader network structure, to also consider textual node descriptors using recurrent neural encoders. Our method is evaluated on link prediction in two networks derived from UMLS. Experimental results demonstrate the effectiveness of the proposed approach compared to previous work.