 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes
Apr 16, 2025We present the Mu-SHROOM shared task which is focused on detecting hallucinations and other overgeneration mistakes in the output of instruction-tuned large language models (LLMs). Mu-SHROOM addresses general-purpose LLMs in 14 languages, and frames the hallucination detection problem as a span-labeling task. We received 2,618 submissions from 43 participating teams employing diverse methodologies. The large number of submissions underscores the interest of the community in hallucination detection. We present the results of the participating systems and conduct an empirical analysis to identify key factors contributing to strong performance in this task. We also emphasize relevant current challenges, notably the varying degree of hallucinations across languages and the high annotator disagreement when labeling hallucination spans.
mStyleDistance: Multilingual Style Embeddings and their Evaluation
Feb 21, 2025Style embeddings are useful for stylistic analysis and style transfer; however, only English style embeddings have been made available. We introduce Multilingual StyleDistance (mStyleDistance), a multilingual style embedding model trained using synthetic data and contrastive learning. We train the model on data from nine languages and create a multilingual STEL-or-Content benchmark (Wegmann et al., 2022) that serves to assess the embeddings' quality. We also employ our embeddings in an authorship verification task involving different languages. Our results show that mStyleDistance embeddings outperform existing models on these multilingual style benchmarks and generalize well to unseen features and languages. We make our model publicly available at https://huggingface.co/StyleDistance/mstyledistance .
GenAI Content Detection Task 3: Cross-Domain Machine-Generated Text Detection Challenge
Jan 15, 2025



Recently there have been many shared tasks targeting the detection of generated text from Large Language Models (LLMs). However, these shared tasks tend to focus either on cases where text is limited to one particular domain or cases where text can be from many domains, some of which may not be seen during test time. In this shared task, using the newly released RAID benchmark, we aim to answer whether or not models can detect generated text from a large, yet fixed, number of domains and LLMs, all of which are seen during training. Over the course of three months, our task was attempted by 9 teams with 23 detector submissions. We find that multiple participants were able to obtain accuracies of over 99% on machine-generated text from RAID while maintaining a 5% False Positive Rate -- suggesting that detectors are able to robustly detect text from many domains and models simultaneously. We discuss potential interpretations of this result and provide directions for future research.
StyleDistance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples
Oct 16, 2024



Style representations aim to embed texts with similar writing styles closely and texts with different styles far apart, regardless of content. However, the contrastive triplets often used for training these representations may vary in both style and content, leading to potential content leakage in the representations. We introduce StyleDistance, a novel approach to training stronger content-independent style embeddings. We use a large language model to create a synthetic dataset of near-exact paraphrases with controlled style variations, and produce positive and negative examples across 40 distinct style features for precise contrastive learning. We assess the quality of our synthetic data and embeddings through human and automatic evaluations. StyleDistance enhances the content-independence of style embeddings, which generalize to real-world benchmarks and outperform leading style representations in downstream applications. Our model can be found at https://huggingface.co/StyleDistance/styledistance .
Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Sep 11, 2024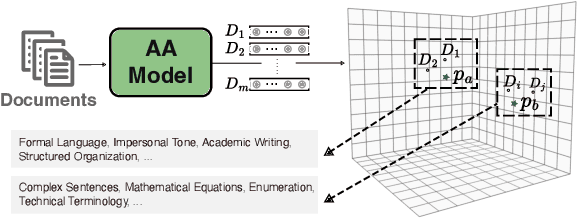
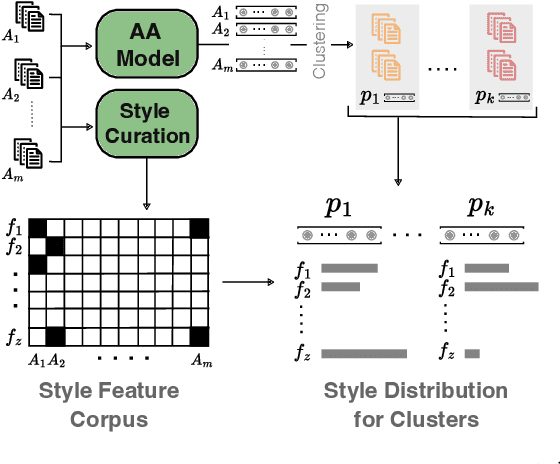

Recent state-of-the-art authorship attribution methods learn authorship representations of texts in a latent, non-interpretable space, hindering their usability in real-world applications. Our work proposes a novel approach to interpreting these learned embeddings by identifying representative points in the latent space and utilizing LLMs to generate informative natural language descriptions of the writing style of each point. We evaluate the alignment of our interpretable space with the latent one and find that it achieves the best prediction agreement compared to other baselines. Additionally, we conduct a human evaluation to assess the quality of these style descriptions, validating their utility as explanations for the latent space. Finally, we investigate whether human performance on the challenging AA task improves when aided by our system's explanations, finding an average improvement of around +20% in accuracy.
Learning Translations via Matrix Completion
Jun 19, 2024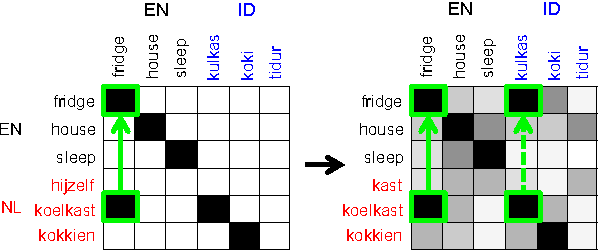
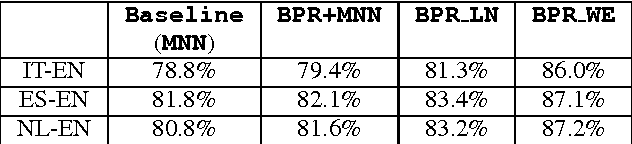
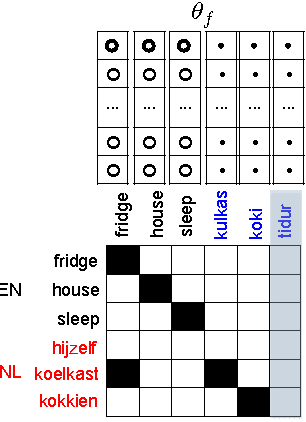

Bilingual Lexicon Induction is the task of learning word translations without bilingual parallel corpora. We model this task as a matrix completion problem, and present an effective and extendable framework for completing the matrix. This method harnesses diverse bilingual and monolingual signals, each of which may be incomplete or noisy. Our model achieves state-of-the-art performance for both high and low resource languages.
* This is a late posting of an old paper as Google Scholar somehow misses indexing the ACL anthology version of the paper
Adjusting Interpretable Dimensions in Embedding Space with Human Judgments
Apr 03, 2024Embedding spaces contain interpretable dimensions indicating gender, formality in style, or even object properties. This has been observed multiple times. Such interpretable dimensions are becoming valuable tools in different areas of study, from social science to neuroscience. The standard way to compute these dimensions uses contrasting seed words and computes difference vectors over them. This is simple but does not always work well. We combine seed-based vectors with guidance from human ratings of where words fall along a specific dimension, and evaluate on predicting both object properties like size and danger, and the stylistic properties of formality and complexity. We obtain interpretable dimensions with markedly better performance especially in cases where seed-based dimensions do not work well.
SemEval-2024 Shared Task 6: SHROOM, a Shared-task on Hallucinations and Related Observable Overgeneration Mistakes
Mar 20, 2024This paper presents the results of the SHROOM, a shared task focused on detecting hallucinations: outputs from natural language generation (NLG) systems that are fluent, yet inaccurate. Such cases of overgeneration put in jeopardy many NLG applications, where correctness is often mission-critical. The shared task was conducted with a newly constructed dataset of 4000 model outputs labeled by 5 annotators each, spanning 3 NLP tasks: machine translation, paraphrase generation and definition modeling. The shared task was tackled by a total of 58 different users grouped in 42 teams, out of which 27 elected to write a system description paper; collectively, they submitted over 300 prediction sets on both tracks of the shared task. We observe a number of key trends in how this approach was tackled -- many participants rely on a handful of model, and often rely either on synthetic data for fine-tuning or zero-shot prompting strategies. While a majority of the teams did outperform our proposed baseline system, the performances of top-scoring systems are still consistent with a random handling of the more challenging items.
Calibrating Large Language Models with Sample Consistency
Feb 21, 2024Accurately gauging the confidence level of Large Language Models' (LLMs) predictions is pivotal for their reliable application. However, LLMs are often uncalibrated inherently and elude conventional calibration techniques due to their proprietary nature and massive scale. In this work, we explore the potential of deriving confidence from the distribution of multiple randomly sampled model generations, via three measures of consistency. We perform an extensive evaluation across various open and closed-source models on nine reasoning datasets. Results show that consistency-based calibration methods outperform existing post-hoc approaches. Meanwhile, we find that factors such as intermediate explanations, model scaling, and larger sample sizes enhance calibration, while instruction-tuning makes calibration more difficult. Moreover, confidence scores obtained from consistency have the potential to enhance model performance. Finally, we offer practical guidance on choosing suitable consistency metrics for calibration, tailored to the characteristics of various LMs.
Representation Of Lexical Stylistic Features In Language Models' Embedding Space
May 31, 2023



The representation space of pretrained Language Models (LMs) encodes rich information about words and their relationships (e.g., similarity, hypernymy, polysemy) as well as abstract semantic notions (e.g., intensity). In this paper, we demonstrate that lexical stylistic notions such as complexity, formality, and figurativeness, can also be identified in this space. We show that it is possible to derive a vector representation for each of these stylistic notions from only a small number of seed pairs. Using these vectors, we can characterize new texts in terms of these dimensions by performing simple calculations in the corresponding embedding space. We conduct experiments on five datasets and find that static embeddings encode these features more accurately at the level of words and phrases, whereas contextualized LMs perform better on sentences. The lower performance of contextualized representations at the word level is partially attributable to the anisotropy of their vector space, which can be corrected to some extent using techniques like standardization.