 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Paper and Code
Sep 11, 2024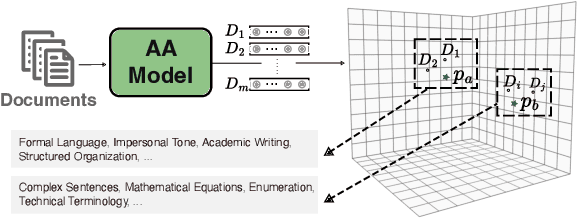
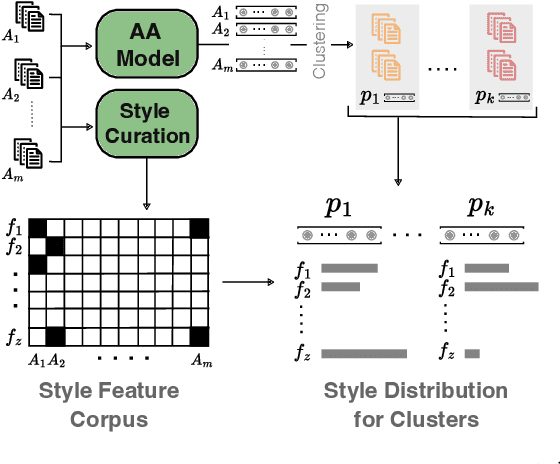

Recent state-of-the-art authorship attribution methods learn authorship representations of texts in a latent, non-interpretable space, hindering their usability in real-world applications. Our work proposes a novel approach to interpreting these learned embeddings by identifying representative points in the latent space and utilizing LLMs to generate informative natural language descriptions of the writing style of each point. We evaluate the alignment of our interpretable space with the latent one and find that it achieves the best prediction agreement compared to other baselines. Additionally, we conduct a human evaluation to assess the quality of these style descriptions, validating their utility as explanations for the latent space. Finally, we investigate whether human performance on the challenging AA task improves when aided by our system's explanations, finding an average improvement of around +20% in accuracy.