 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Thinking Tokens Help with Safety?
Jun 23, 2026Today's reasoning models use thinking tokens to attain stronger performance on benchmarks than their instruction-tuned counterparts. It is also generally believed that this more "deliberative" mode should improve alignment and safety, by providing the model a safe space to consider whether its planned answer to a request violates its safety principles. We present evidence that this intuition is not always correct. Across frontier open-weight reasoning models spanning GPT-OSS, Qwen, Olmo, and Phi families, we find that the eventual refusal/compliance outcome is already strongly predictable via a trained head on the first token's hidden representation ($0.84$-$0.95$ AUROC and $\sim88\%$ balanced accuracy for predicting refusal/compliance) before any visible thinking. The thinking process turns out to be more akin to prefix completion than to deliberative revision, with the final outcome rarely changing after the first $\sim20\%$ of thinking, despite giving the appearance of deliberation at the text level ($\sim74\%$ of text-level deliberations occur when the response distribution is already locked to one refusal/compliance side). We also find that existing inference-time and training-based safety interventions, despite being motivated by the goal of inducing deliberation, largely shift model behavior toward over-refusal while suppressing already-scarce deliberation signals. Our results suggest that safety behavior in current reasoning models is much less deliberative than commonly assumed, and highlight the need for methods that induce real safety deliberation.
Goedel-Architect: Streamlining Formal Theorem Proving with Blueprint Generation and Refinement
Jun 04, 2026We introduce Goedel-Architect, an agentic framework for formal theorem proving in Lean 4 centered on blueprint generation and refinement. A blueprint is a dependency graph of definitions and lemmas that builds up to the main theorem. First, Goedel-Architect generates a blueprint of formally stated definitions and lemmas, along with declared dependencies. This blueprint is optionally guided by a natural language proof. Then, a tool-equipped Lean prover component closes each open lemma node in parallel using relevant dependencies. Failed lemmas in turn drive refinement of the global blueprint. This strategy contrasts with other mainstream approaches which use recursive lemma decomposition, and can inefficiently loop on dead-end strategies. Using the open-weight DeepSeek-V4-Flash (284B-A13B) as the backbone, Goedel-Architect attains 99.2% pass@1 on MiniF2F-test and 75.6% pass@1 on PutnamBench. With an optional natural-language proof seeding the initial blueprint on the harder problems, we additionally close the remaining two MiniF2F-test problems (reaching 100%), lift PutnamBench to 88.8% (597/672), and solve 4/6 on IMO 2025, 11/12 on Putnam 2025, and 3/6 on USAMO 2026. This represents state-of-the-art performance for an open-source pipeline at a price point up to 500x less than comparable open-source pipelines.
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Apr 13, 2026Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
Speak Easy: Eliciting Harmful Jailbreaks from LLMs with Simple Interactions
Feb 06, 2025



Despite extensive safety alignment efforts, large language models (LLMs) remain vulnerable to jailbreak attacks that elicit harmful behavior. While existing studies predominantly focus on attack methods that require technical expertise, two critical questions remain underexplored: (1) Are jailbroken responses truly useful in enabling average users to carry out harmful actions? (2) Do safety vulnerabilities exist in more common, simple human-LLM interactions? In this paper, we demonstrate that LLM responses most effectively facilitate harmful actions when they are both actionable and informative--two attributes easily elicited in multi-step, multilingual interactions. Using this insight, we propose HarmScore, a jailbreak metric that measures how effectively an LLM response enables harmful actions, and Speak Easy, a simple multi-step, multilingual attack framework. Notably, by incorporating Speak Easy into direct request and jailbreak baselines, we see an average absolute increase of 0.319 in Attack Success Rate and 0.426 in HarmScore in both open-source and proprietary LLMs across four safety benchmarks. Our work reveals a critical yet often overlooked vulnerability: Malicious users can easily exploit common interaction patterns for harmful intentions.
Latent Space Interpretation for Stylistic Analysis and Explainable Authorship Attribution
Sep 11, 2024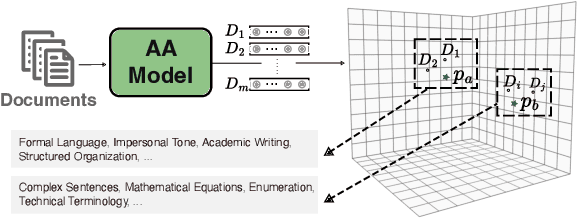
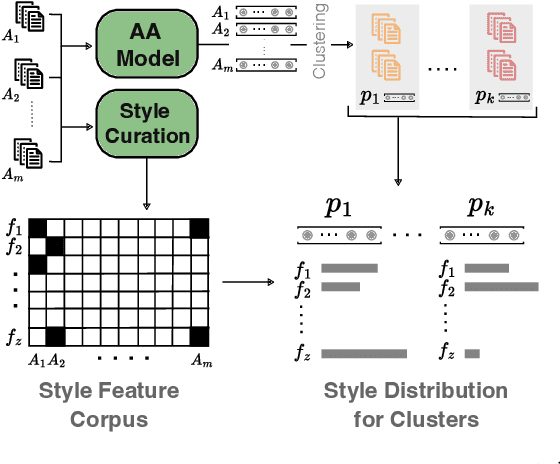

Recent state-of-the-art authorship attribution methods learn authorship representations of texts in a latent, non-interpretable space, hindering their usability in real-world applications. Our work proposes a novel approach to interpreting these learned embeddings by identifying representative points in the latent space and utilizing LLMs to generate informative natural language descriptions of the writing style of each point. We evaluate the alignment of our interpretable space with the latent one and find that it achieves the best prediction agreement compared to other baselines. Additionally, we conduct a human evaluation to assess the quality of these style descriptions, validating their utility as explanations for the latent space. Finally, we investigate whether human performance on the challenging AA task improves when aided by our system's explanations, finding an average improvement of around +20% in accuracy.
Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations
Jul 17, 2023Large language models (LLMs) are trained to imitate humans to explain human decisions. However, do LLMs explain themselves? Can they help humans build mental models of how LLMs process different inputs? To answer these questions, we propose to evaluate $\textbf{counterfactual simulatability}$ of natural language explanations: whether an explanation can enable humans to precisely infer the model's outputs on diverse counterfactuals of the explained input. For example, if a model answers "yes" to the input question "Can eagles fly?" with the explanation "all birds can fly", then humans would infer from the explanation that it would also answer "yes" to the counterfactual input "Can penguins fly?". If the explanation is precise, then the model's answer should match humans' expectations. We implemented two metrics based on counterfactual simulatability: precision and generality. We generated diverse counterfactuals automatically using LLMs. We then used these metrics to evaluate state-of-the-art LLMs (e.g., GPT-4) on two tasks: multi-hop factual reasoning and reward modeling. We found that LLM's explanations have low precision and that precision does not correlate with plausibility. Therefore, naively optimizing human approvals (e.g., RLHF) may not be a sufficient solution.
Contrastive Loss is All You Need to Recover Analogies as Parallel Lines
Jun 14, 2023



While static word embedding models are known to represent linguistic analogies as parallel lines in high-dimensional space, the underlying mechanism as to why they result in such geometric structures remains obscure. We find that an elementary contrastive-style method employed over distributional information performs competitively with popular word embedding models on analogy recovery tasks, while achieving dramatic speedups in training time. Further, we demonstrate that a contrastive loss is sufficient to create these parallel structures in word embeddings, and establish a precise relationship between the co-occurrence statistics and the geometric structure of the resulting word embeddings.
IdEALS: Idiomatic Expressions for Advancement of Language Skills
May 24, 2023
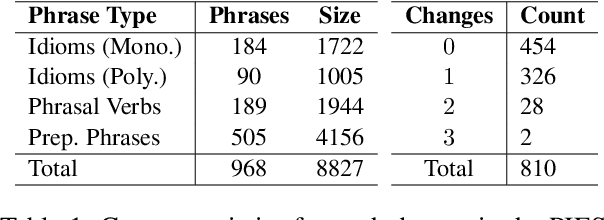
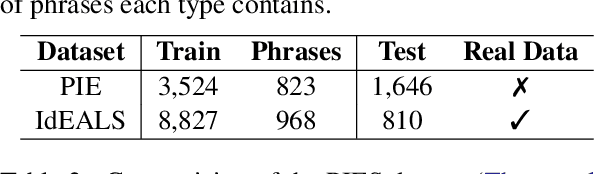

Although significant progress has been made in developing methods for Grammatical Error Correction (GEC), addressing word choice improvements has been notably lacking and enhancing sentence expressivity by replacing phrases with advanced expressions is an understudied aspect. In this paper, we focus on this area and present our investigation into the task of incorporating the usage of idiomatic expressions in student writing. To facilitate our study, we curate extensive training sets and expert-annotated testing sets using real-world data and evaluate various approaches and compare their performance against human experts.
Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies
May 21, 2023In-context learning (ICL) has emerged as a new approach to various natural language processing tasks, utilizing large language models (LLMs) to make predictions based on context that has been supplemented with a few examples or task-specific instructions. In this paper, we aim to extend this method to question answering tasks that utilize structured knowledge sources, and improve Text-to-SQL systems by exploring various prompt design strategies for employing LLMs. We conduct a systematic investigation into different demonstration selection methods and optimal instruction formats for prompting LLMs in the Text-to-SQL task. Our approach involves leveraging the syntactic structure of an example's SQL query to retrieve demonstrations, and we demonstrate that pursuing both diversity and similarity in demonstration selection leads to enhanced performance. Furthermore, we show that LLMs benefit from database-related knowledge augmentations. Our most effective strategy outperforms the state-of-the-art system by 2.5 points (Execution Accuracy) and the best fine-tuned system by 5.1 points on the Spider dataset. These results highlight the effectiveness of our approach in adapting LLMs to the Text-to-SQL task, and we present an analysis of the factors contributing to the success of our strategy.