 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Predict Alignment Before Models Finish Thinking? Towards Monitoring Misaligned Reasoning Models
Jul 16, 2025Open-weights reasoning language models generate long chains-of-thought (CoTs) before producing a final response, which improves performance but introduces additional alignment risks, with harmful content often appearing in both the CoTs and the final outputs. In this work, we investigate if we can use CoTs to predict final response misalignment. We evaluate a range of monitoring approaches, including humans, highly-capable large language models, and text classifiers, using either CoT text or activations. First, we find that a simple linear probe trained on CoT activations can significantly outperform all text-based methods in predicting whether a final response will be safe or unsafe. CoT texts are often unfaithful and can mislead humans and classifiers, while model latents (i.e., CoT activations) offer a more reliable predictive signal. Second, the probe makes accurate predictions before reasoning completes, achieving strong performance even when applied to early CoT segments. These findings generalize across model sizes, families, and safety benchmarks, suggesting that lightweight probes could enable real-time safety monitoring and early intervention during generation.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Speak Easy: Eliciting Harmful Jailbreaks from LLMs with Simple Interactions
Feb 06, 2025



Despite extensive safety alignment efforts, large language models (LLMs) remain vulnerable to jailbreak attacks that elicit harmful behavior. While existing studies predominantly focus on attack methods that require technical expertise, two critical questions remain underexplored: (1) Are jailbroken responses truly useful in enabling average users to carry out harmful actions? (2) Do safety vulnerabilities exist in more common, simple human-LLM interactions? In this paper, we demonstrate that LLM responses most effectively facilitate harmful actions when they are both actionable and informative--two attributes easily elicited in multi-step, multilingual interactions. Using this insight, we propose HarmScore, a jailbreak metric that measures how effectively an LLM response enables harmful actions, and Speak Easy, a simple multi-step, multilingual attack framework. Notably, by incorporating Speak Easy into direct request and jailbreak baselines, we see an average absolute increase of 0.319 in Attack Success Rate and 0.426 in HarmScore in both open-source and proprietary LLMs across four safety benchmarks. Our work reveals a critical yet often overlooked vulnerability: Malicious users can easily exploit common interaction patterns for harmful intentions.
A Demonstration of Adaptive Collaboration of Large Language Models for Medical Decision-Making
Oct 31, 2024



Medical Decision-Making (MDM) is a multi-faceted process that requires clinicians to assess complex multi-modal patient data patient, often collaboratively. Large Language Models (LLMs) promise to streamline this process by synthesizing vast medical knowledge and multi-modal health data. However, single-agent are often ill-suited for nuanced medical contexts requiring adaptable, collaborative problem-solving. Our MDAgents addresses this need by dynamically assigning collaboration structures to LLMs based on task complexity, mimicking real-world clinical collaboration and decision-making. This framework improves diagnostic accuracy and supports adaptive responses in complex, real-world medical scenarios, making it a valuable tool for clinicians in various healthcare settings, and at the same time, being more efficient in terms of computing cost than static multi-agent decision making methods.
Adaptive Collaboration Strategy for LLMs in Medical Decision Making
Apr 22, 2024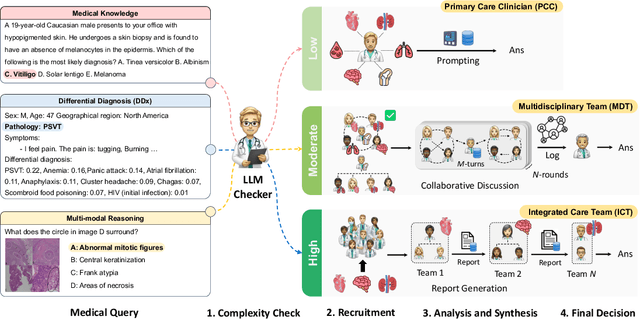
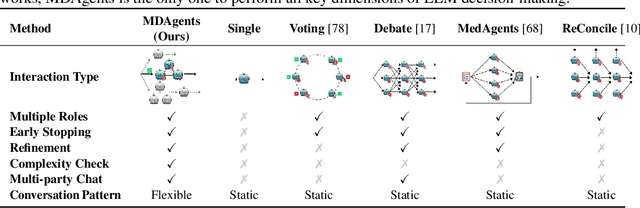
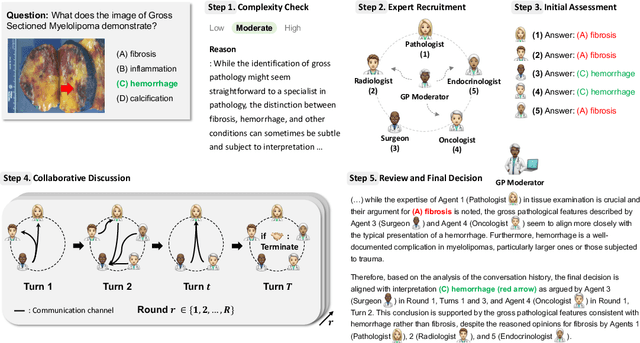
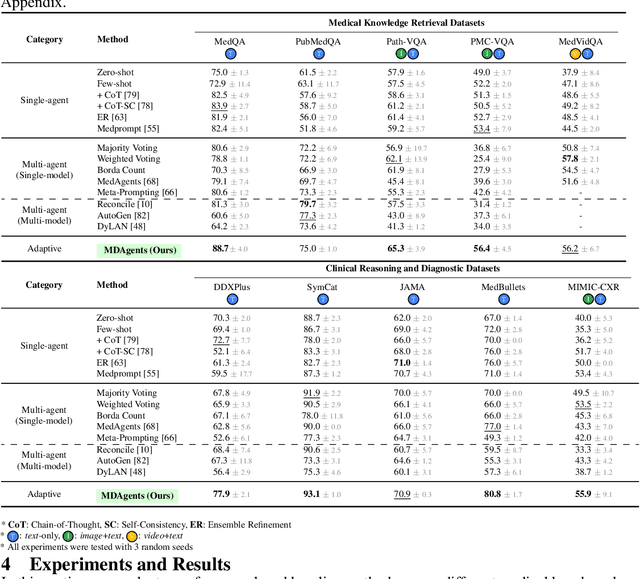
Foundation models have become invaluable in advancing the medical field. Despite their promise, the strategic deployment of LLMs for effective utility in complex medical tasks remains an open question. Our novel framework, Medical Decision-making Agents (MDAgents) aims to address this gap by automatically assigning the effective collaboration structure for LLMs. Assigned solo or group collaboration structure is tailored to the complexity of the medical task at hand, emulating real-world medical decision making processes. We evaluate our framework and baseline methods with state-of-the-art LLMs across a suite of challenging medical benchmarks: MedQA, MedMCQA, PubMedQA, DDXPlus, PMC-VQA, Path-VQA, and MedVidQA, achieving the best performance in 5 out of 7 benchmarks that require an understanding of multi-modal medical reasoning. Ablation studies reveal that MDAgents excels in adapting the number of collaborating agents to optimize efficiency and accuracy, showcasing its robustness in diverse scenarios. We also explore the dynamics of group consensus, offering insights into how collaborative agents could behave in complex clinical team dynamics. Our code can be found at https://github.com/mitmedialab/MDAgents.