 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modern System Recipe for Situated Embodied Human-Robot Conversation with Real-Time Multimodal LLMs and Tool-Calling
Feb 04, 2026Situated embodied conversation requires robots to interleave real-time dialogue with active perception: deciding what to look at, when to look, and what to say under tight latency constraints. We present a simple, minimal system recipe that pairs a real-time multimodal language model with a small set of tool interfaces for attention and active perception. We study six home-style scenarios that require frequent attention shifts and increasing perceptual scope. Across four system variants, we evaluate turn-level tool-decision correctness against human annotations and collect subjective ratings of interaction quality. Results indicate that real-time multimodal large language models and tool use for active perception is a promising direction for practical situated embodied conversation.
Collaborative Multi-Agent Test-Time Reinforcement Learning for Reasoning
Jan 15, 2026Multi-agent systems have evolved into practical LLM-driven collaborators for many applications, gaining robustness from diversity and cross-checking. However, multi-agent RL (MARL) training is resource-intensive and unstable: co-adapting teammates induce non-stationarity, and rewards are often sparse and high-variance. Therefore, we introduce \textbf{Multi-Agent Test-Time Reinforcement Learning (MATTRL)}, a framework that injects structured textual experience into multi-agent deliberation at inference time. MATTRL forms a multi-expert team of specialists for multi-turn discussions, retrieves and integrates test-time experiences, and reaches consensus for final decision-making. We also study credit assignment for constructing a turn-level experience pool, then reinjecting it into the dialogue. Across challenging benchmarks in medicine, math, and education, MATTRL improves accuracy by an average of 3.67\% over a multi-agent baseline, and by 8.67\% over comparable single-agent baselines. Ablation studies examine different credit-assignment schemes and provide a detailed comparison of how they affect training outcomes. MATTRL offers a stable, effective and efficient path to distribution-shift-robust multi-agent reasoning without tuning.
Rewarding the Rare: Uniqueness-Aware RL for Creative Problem Solving in LLMs
Jan 13, 2026Reinforcement learning (RL) has become a central paradigm for post-training large language models (LLMs), particularly for complex reasoning tasks, yet it often suffers from exploration collapse: policies prematurely concentrate on a small set of dominant reasoning patterns, improving pass@1 while limiting rollout-level diversity and gains in pass@k. We argue that this failure stems from regularizing local token behavior rather than diversity over sets of solutions. To address this, we propose Uniqueness-Aware Reinforcement Learning, a rollout-level objective that explicitly rewards correct solutions that exhibit rare high-level strategies. Our method uses an LLM-based judge to cluster rollouts for the same problem according to their high-level solution strategies, ignoring superficial variations, and reweights policy advantages inversely with cluster size. As a result, correct but novel strategies receive higher rewards than redundant ones. Across mathematics, physics, and medical reasoning benchmarks, our approach consistently improves pass@$k$ across large sampling budgets and increases the area under the pass@$k$ curve (AUC@$K$) without sacrificing pass@1, while sustaining exploration and uncovering more diverse solution strategies at scale.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
InvThink: Towards AI Safety via Inverse Reasoning
Oct 02, 2025



We present InvThink, a simple yet powerful approach that gives large language models (LLMs) the capability of inverse thinking: reasoning through failure modes before generating responses. Unlike existing safety alignment methods that optimize directly for safe response, InvThink instructs models to 1) enumerate potential harms, 2) analyze their consequences, and 3) generate safe outputs that proactively avoid these risks. Our method reveals three key findings: (i) safety improvements show stronger scaling with model size compared to existing safety methods. (ii) InvThink mitigates safety tax; by training models to systematically consider failure modes, it preserves general reasoning capabilities on standard benchmarks. (iii) beyond general safety tasks, InvThink excels in high-stakes domains including external-facing (medicine, finance, law) and agentic (blackmail, murder) risk scenarios, achieving up to 15.7% reduction in harmful responses compared to baseline methods like SafetyPrompt. We further implement InvThink via supervised fine-tuning, and reinforcement learning across three LLM families. These results suggest that inverse reasoning provides a scalable and generalizable path toward safer, more capable language models.
Tiered Agentic Oversight: A Hierarchical Multi-Agent System for AI Safety in Healthcare
Jun 14, 2025Current large language models (LLMs), despite their power, can introduce safety risks in clinical settings due to limitations such as poor error detection and single point of failure. To address this, we propose Tiered Agentic Oversight (TAO), a hierarchical multi-agent framework that enhances AI safety through layered, automated supervision. Inspired by clinical hierarchies (e.g., nurse, physician, specialist), TAO conducts agent routing based on task complexity and agent roles. Leveraging automated inter- and intra-tier collaboration and role-playing, TAO creates a robust safety framework. Ablation studies reveal that TAO's superior performance is driven by its adaptive tiered architecture, which improves safety by over 3.2% compared to static single-tier configurations; the critical role of its lower tiers, particularly tier 1, whose removal most significantly impacts safety; and the strategic assignment of more advanced LLM to these initial tiers, which boosts performance by over 2% compared to less optimal allocations while achieving near-peak safety efficiently. These mechanisms enable TAO to outperform single-agent and multi-agent frameworks in 4 out of 5 healthcare safety benchmarks, showing up to an 8.2% improvement over the next-best methods in these evaluations. Finally, we validate TAO via an auxiliary clinician-in-the-loop study where integrating expert feedback improved TAO's accuracy in medical triage from 40% to 60%.
BehaviorSFT: Behavioral Token Conditioning for Clinical Agents Across the Proactivity Spectrum
May 27, 2025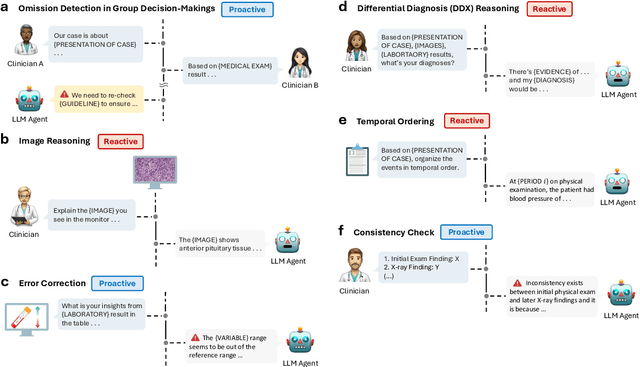
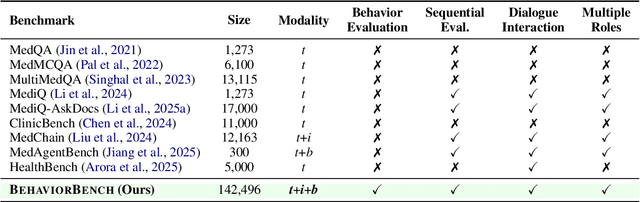
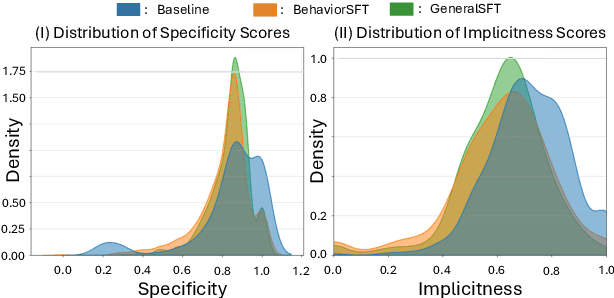
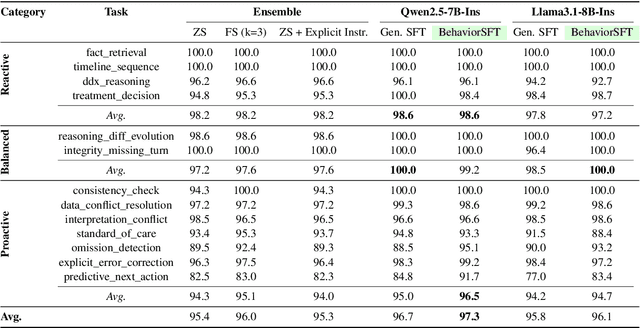
Large Language Models (LLMs) as clinical agents require careful behavioral adaptation. While adept at reactive tasks (e.g., diagnosis reasoning), LLMs often struggle with proactive engagement, like unprompted identification of critical missing information or risks. We introduce BehaviorBench, a comprehensive dataset to evaluate agent behaviors across a clinical assistance spectrum, ranging from reactive query responses to proactive interventions (e.g., clarifying ambiguities, flagging overlooked critical data). Our BehaviorBench experiments reveal LLMs' inconsistent proactivity. To address this, we propose BehaviorSFT, a novel training strategy using behavioral tokens to explicitly condition LLMs for dynamic behavioral selection along this spectrum. BehaviorSFT boosts performance, achieving up to 97.3% overall Macro F1 on BehaviorBench and improving proactive task scores (e.g., from 95.0% to 96.5% for Qwen2.5-7B-Ins). Crucially, blind clinician evaluations confirmed BehaviorSFT-trained agents exhibit more realistic clinical behavior, striking a superior balance between helpful proactivity (e.g., timely, relevant suggestions) and necessary restraint (e.g., avoiding over-intervention) versus standard fine-tuning or explicit instructed agents.
Words Like Knives: Backstory-Personalized Modeling and Detection of Violent Communication
May 27, 2025Conversational breakdowns in close relationships are deeply shaped by personal histories and emotional context, yet most NLP research treats conflict detection as a general task, overlooking the relational dynamics that influence how messages are perceived. In this work, we leverage nonviolent communication (NVC) theory to evaluate LLMs in detecting conversational breakdowns and assessing how relationship backstory influences both human and model perception of conflicts. Given the sensitivity and scarcity of real-world datasets featuring conflict between familiar social partners with rich personal backstories, we contribute the PersonaConflicts Corpus, a dataset of N=5,772 naturalistic simulated dialogues spanning diverse conflict scenarios between friends, family members, and romantic partners. Through a controlled human study, we annotate a subset of dialogues and obtain fine-grained labels of communication breakdown types on individual turns, and assess the impact of backstory on human and model perception of conflict in conversation. We find that the polarity of relationship backstories significantly shifted human perception of communication breakdowns and impressions of the social partners, yet models struggle to meaningfully leverage those backstories in the detection task. Additionally, we find that models consistently overestimate how positively a message will make a listener feel. Our findings underscore the critical role of personalization to relationship contexts in enabling LLMs to serve as effective mediators in human communication for authentic connection.
Aligning Dialogue Agents with Global Feedback via Large Language Model Reward Decomposition
May 21, 2025We propose a large language model based reward decomposition framework for aligning dialogue agents using only a single session-level feedback signal. We leverage the reasoning capabilities of a frozen, pretrained large language model (LLM) to infer fine-grained local implicit rewards by decomposing global, session-level feedback. Our first text-only variant prompts the LLM to perform reward decomposition using only the dialogue transcript. The second multimodal variant incorporates additional behavioral cues, such as pitch, gaze, and facial affect, expressed as natural language descriptions. These inferred turn-level rewards are distilled into a lightweight reward model, which we utilize for RL-based fine-tuning for dialogue generation. We evaluate both text-only and multimodal variants against state-of-the-art reward decomposition methods and demonstrate notable improvements in human evaluations of conversation quality, suggesting that LLMs are strong reward decomposers that obviate the need for manual reward shaping and granular human feedback.
VocalAgent: Large Language Models for Vocal Health Diagnostics with Safety-Aware Evaluation
May 19, 2025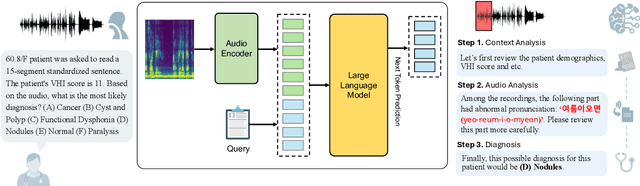
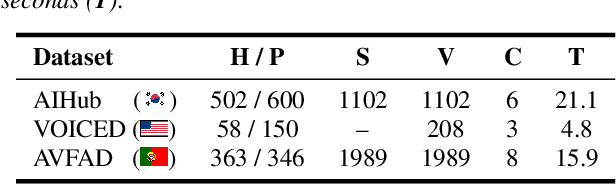
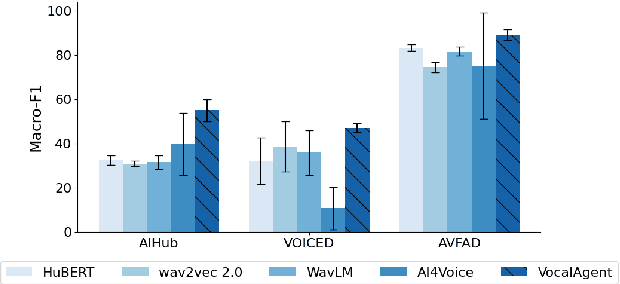
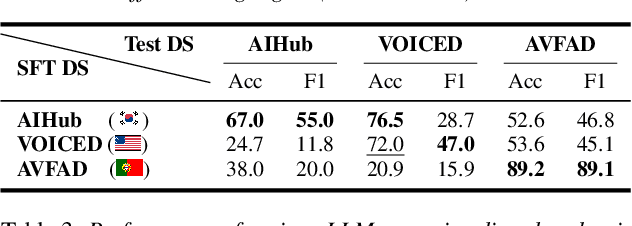
Vocal health plays a crucial role in peoples' lives, significantly impacting their communicative abilities and interactions. However, despite the global prevalence of voice disorders, many lack access to convenient diagnosis and treatment. This paper introduces VocalAgent, an audio large language model (LLM) to address these challenges through vocal health diagnosis. We leverage Qwen-Audio-Chat fine-tuned on three datasets collected in-situ from hospital patients, and present a multifaceted evaluation framework encompassing a safety assessment to mitigate diagnostic biases, cross-lingual performance analysis, and modality ablation studies. VocalAgent demonstrates superior accuracy on voice disorder classification compared to state-of-the-art baselines. Its LLM-based method offers a scalable solution for broader adoption of health diagnostics, while underscoring the importance of ethical and technical validation.